
现代游戏引擎 - 游戏引擎中的粒子和声效系统(十二)
游戏引擎中的粒子和声效系统
粒子系统(Particle System)
粒子系统(particle system)是现代游戏中非常重要的组成部分,游戏中大量的特效都是基于粒子系统来实现的。 粒子系统
粒子系统
粒子基础(Fundamentals)
实际上粒子系统来自于电影行业对于视觉特效的追求,它最早可以追溯到1982年的电影《星际迷航2:可汗之怒》。 粒子系统的历史
粒子系统的历史
所谓的粒子是指具有一些物理信息的物体,常见的物理量包括位置、速度、大小、颜色等。 粒子
粒子
同时粒子还需要考虑自身的生命周期(life cycle),当粒子的生命周期结束后需要被系统回收。 粒子生命周期
粒子生命周期
粒子发射器(Particle Emitter)
每一种不同的粒子都是由相应的粒子发射器(particle emitter)生成的。每一种粒子发射器需要指定自身的生成规则同时为粒子赋予相应的仿真逻辑。 粒子发射器
粒子发射器
在一个粒子系统中往往会同时具有多个不同的例子发射器进行工作,它们之间相互配合就实现了丰富的粒子效果。 粒子系统
粒子系统
粒子生成(Particle Spawn)
粒子系统在生成粒子时可以根据需求使用不同的生成策略。比较简单的生成方式是从单点生成粒子,而在现代粒子生成器中则可以从某个区域甚至从物体的网格来生成粒子。
同时粒子生成器也可以根据需求只产生一次性的粒子,或是源源不断地生成新的粒子。 粒子生成位置
粒子生成位置 粒子生成模式
粒子生成模式
模拟(Simulation)
完成粒子的生成后就可以利用质点运动学的相关方法对粒子进行仿真。由于粒子系统一般不需要严格地遵守物理规律,
在实践中往往只会使用最简单的前向积分来实现对粒子状态进行更新。 模拟
模拟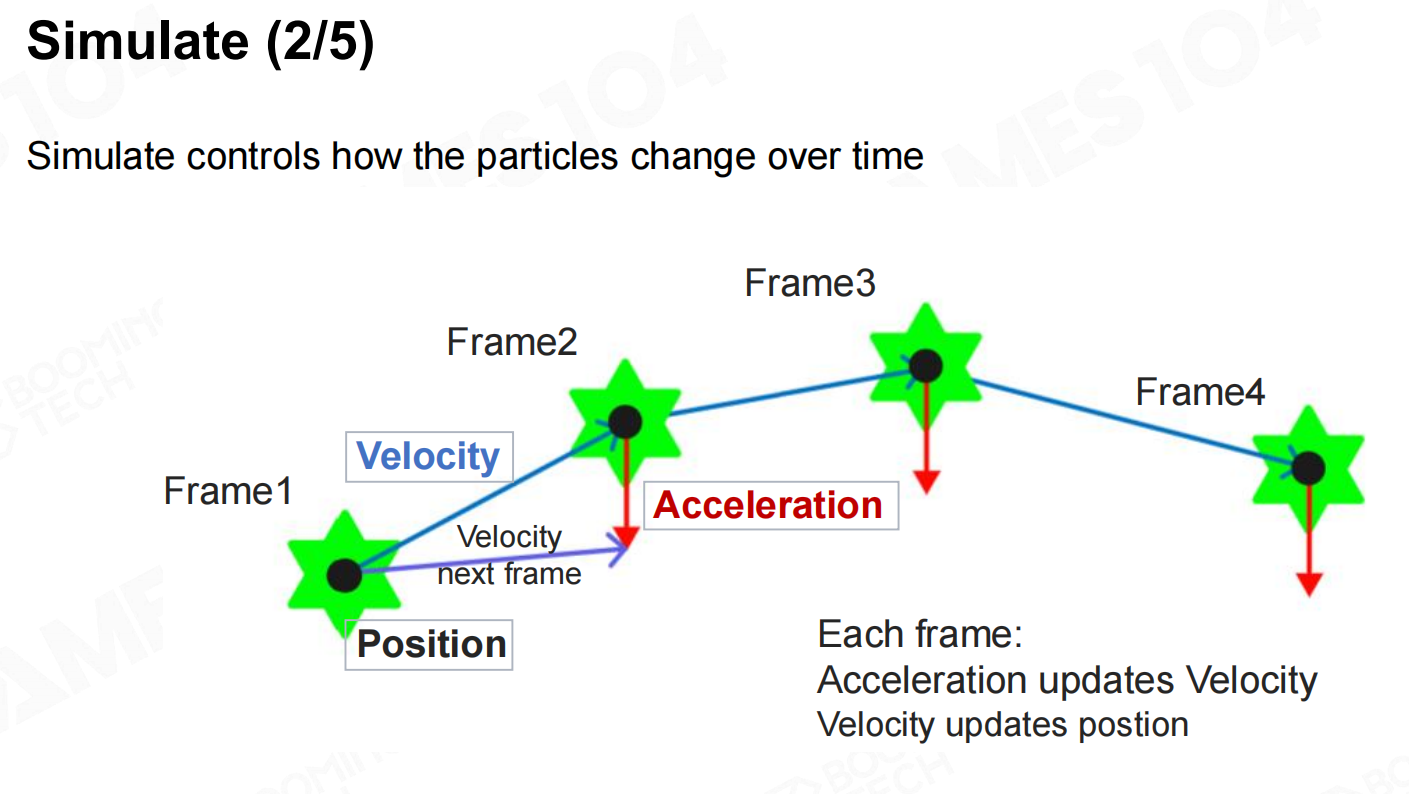 模拟2
模拟2
粒子类型(Particle Type)
早期的粒子系统会假定粒子都位于某个平面上进行运动,这种方法称为billboard particle。当观察者的视角发生变化时,
billboard会随着观察者的视角一起变化从而保证它一直位于观察者的正前方。 粒子面片
粒子面片
随着游戏技术的进步,后来还出现了mesh particle这种带有几何信息的粒子。这种形式的粒子可以用来模拟岩石、碎屑等带有明显几何信息的颗粒。 网格粒子
网格粒子
在很多游戏中还使用了ribbon particle这种带状的粒子用来模拟各种拖动的效果,比如说游戏中各种武器的特效一般都是使用这种技术来制作的。
在使用ribbon particle时一般还会结合Catmull曲线来形成光滑连贯的特效。 带状粒子
带状粒子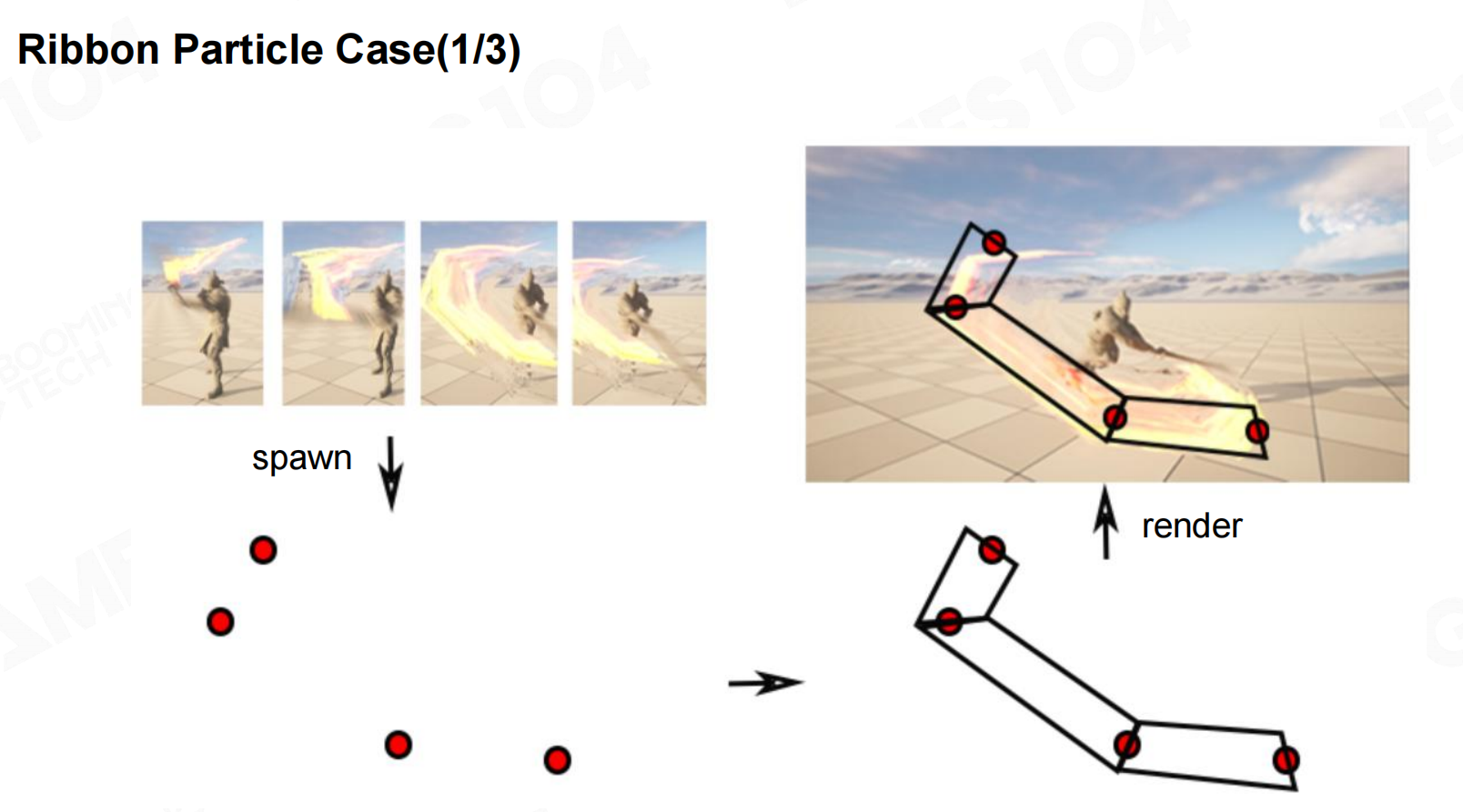 带状粒子2
带状粒子2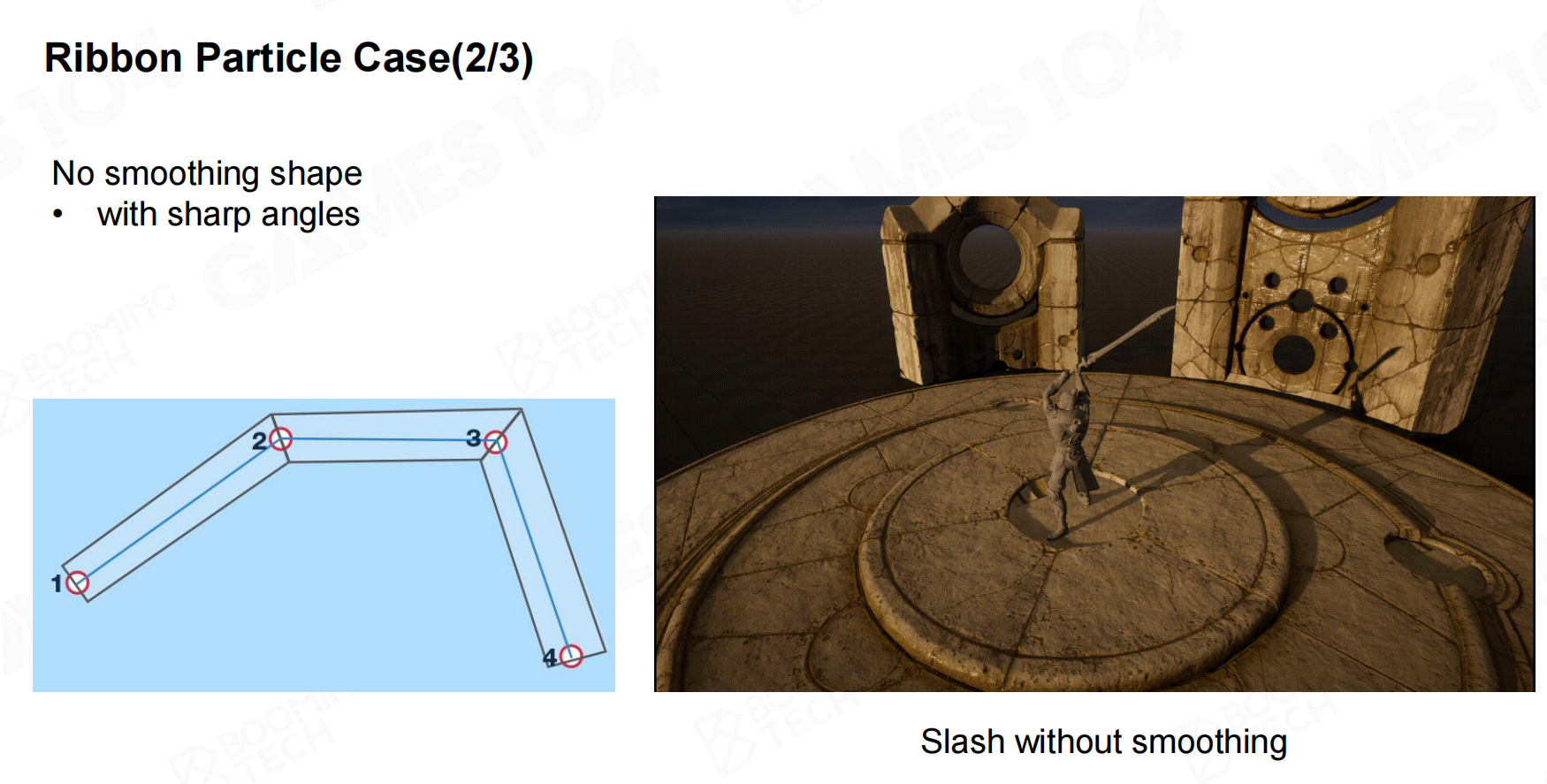 带状粒子3
带状粒子3 带状粒子4
带状粒子4
粒子渲染(Particle System Rendering)
粒子排序(Particle Sort)
粒子在进行渲染时的一大难点在于如何进行排序。按照alpha混合的理论,我们需要从最远端开始由远及近地对场景中的物体进行绘制。 alpha混合
alpha混合
由于场景中往往同时存在巨量的粒子,对这些粒子进行排序往往会耗费大量的计算资源。目前对于粒子进行排序主要有两种做法:
其一是全局排序即无考虑发射器的信息单纯对所有的粒子进行排序,这种做法可以获得正确的结果但需要非常多的计算资源;
另一种做法是按照发射器进行排序,这种方法可以极大地减少计算资源但可能会出现错误的排序结果。 alpha混合
alpha混合
分辨率(Resolution)
当粒子充满场景时非透明的粒子会导致我们必须在同一像素上进行反复的绘制,这往往会导致帧数极大的下降。 全分辨率粒子
全分辨率粒子
因此在对粒子进行渲染时还会结合降采样的技术来减少需要进行绘制的像素数。
把降采样后的图像和非透明的粒子按照透明度混合后在通过上采样来恢复原始分辨率。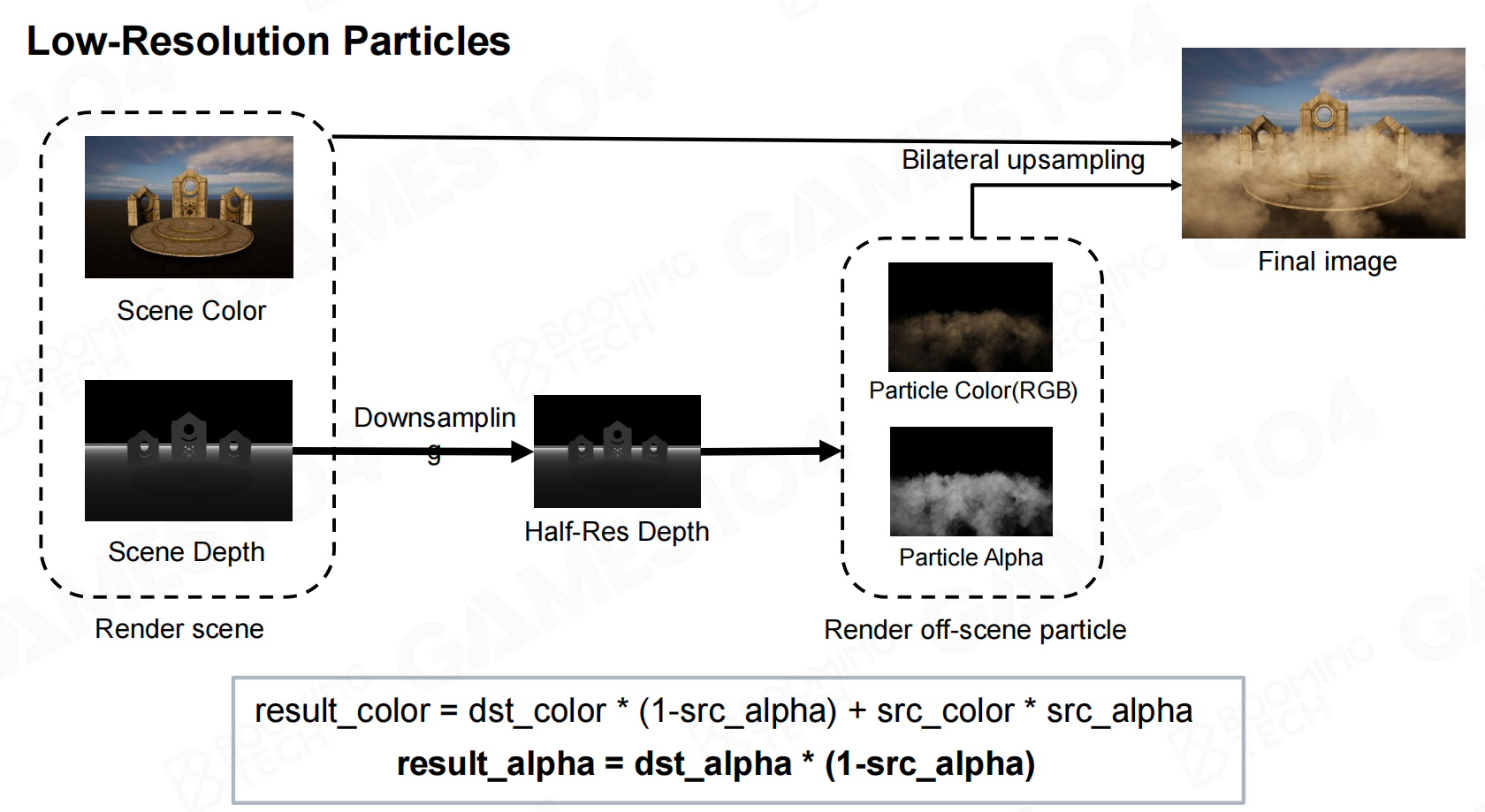 低分辨率粒子
低分辨率粒子
GPU粒子
显然粒子系统这种天然并行的系统非常适合使用GPU进行计算,在现代游戏中也确实是使用GPU来实现对粒子系统的仿真。
稍后我们会看到使用GPU来对粒子系统进行计算不仅可以节约CPU的计算资源,更可以加速整个渲染的流程。 GPU处理粒子
GPU处理粒子 GPU粒子
GPU粒子
粒子列表(Particle Lists)
我们可以通过维护若干个列表来实现对粒子系统的仿真。首先我们把系统中所有可能的粒子及其携带的信息放入particle pool中,并且在deal list中初始化所有的粒子编号。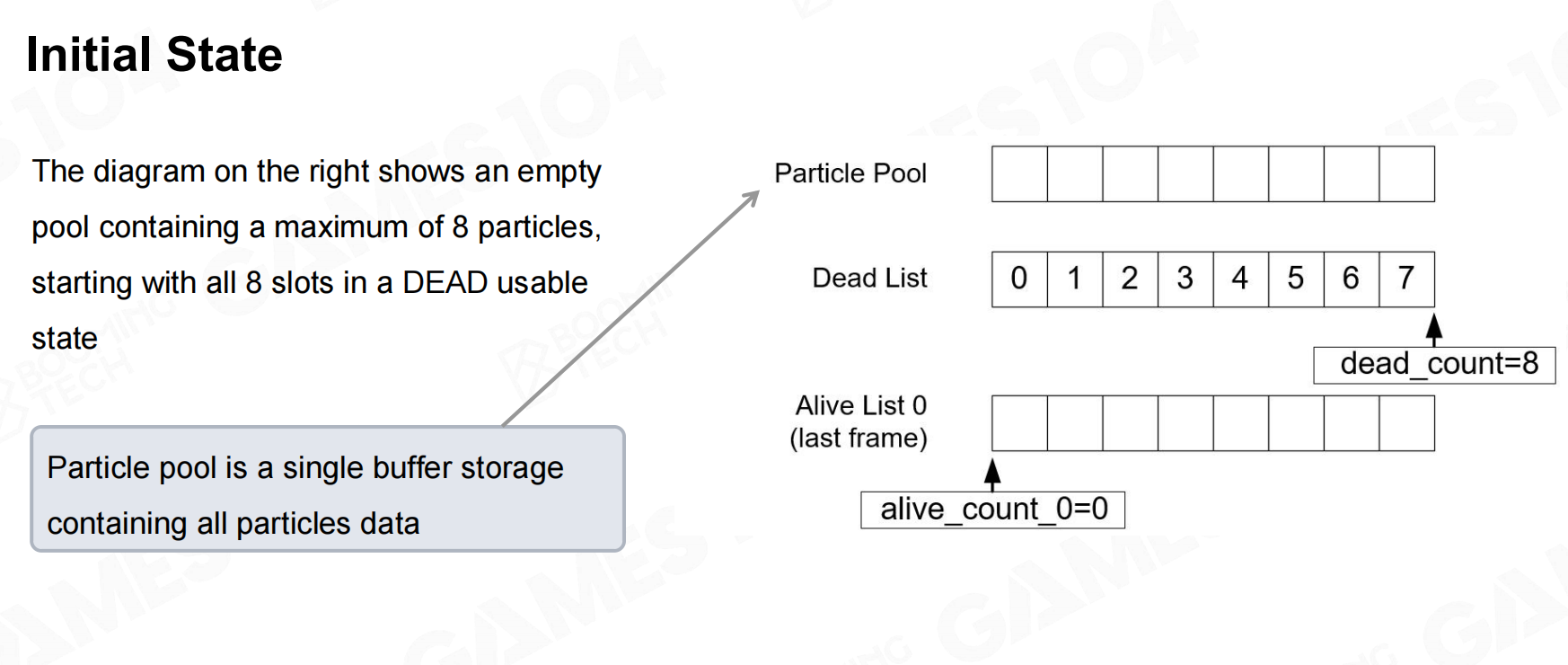 初始化状态
初始化状态
当emitter生成新的粒子时只需要将dead list中的粒子推入当前帧的alive list即可。 生成新粒子
生成新粒子
对粒子进行仿真时只需要考虑alive list中的粒子。如果某个粒子的生命周期结束了,则需要把该粒子编号重新放入dead list中,
然后在写入下一帧的alive list时跳过该编号。当需要切换到下一帧时只需交换两个alive list即可。 模拟
模拟
由于所有的数据都在GPU上,我们还可以方便地对粒子进行frustum culling以及排序。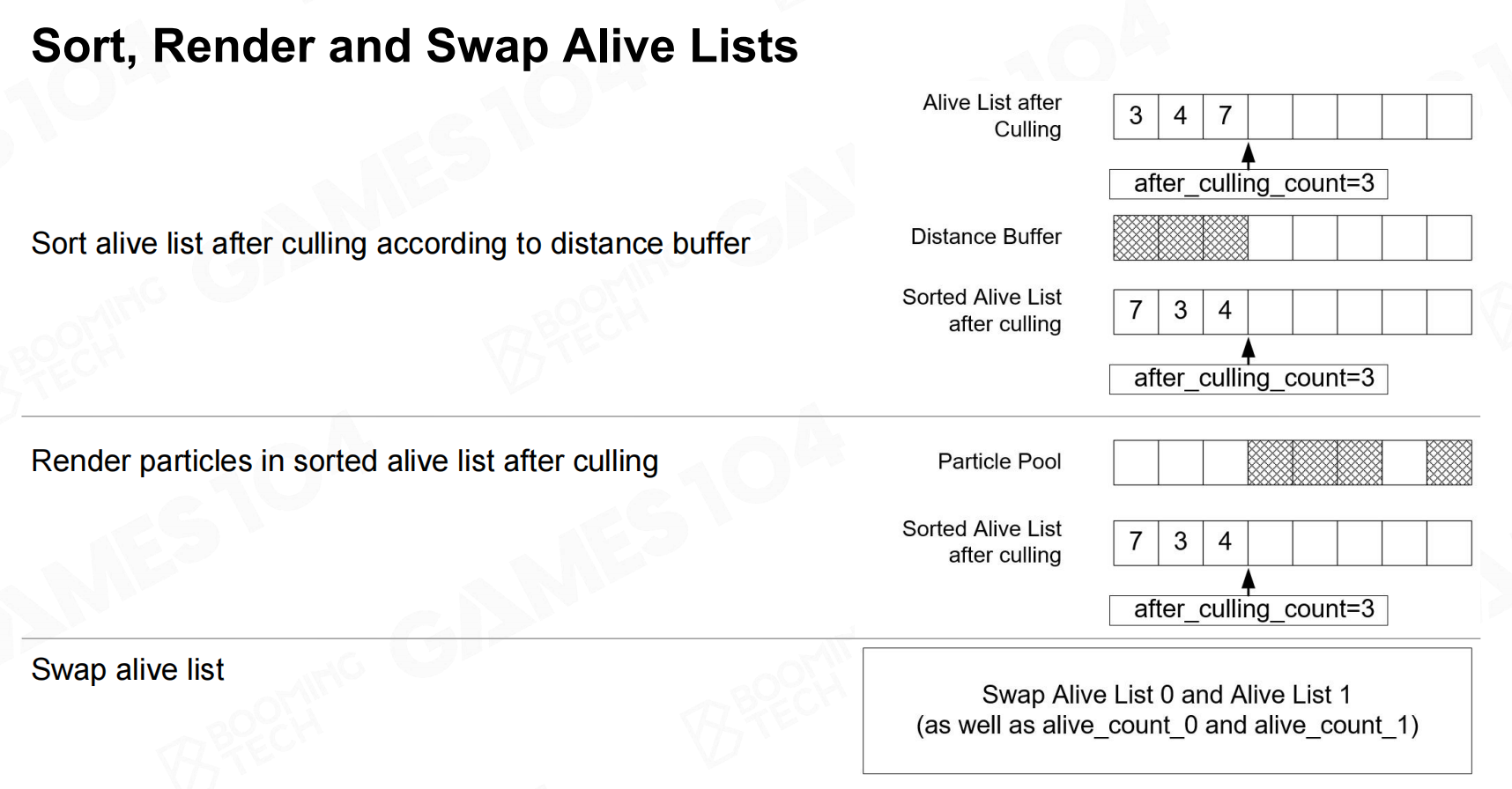 排序
排序
并行合并排序(Parallel Mergesort)
在GPU上进行排序时需要使用并行的排序算法,其中比较经典的算法是parallel mergesort。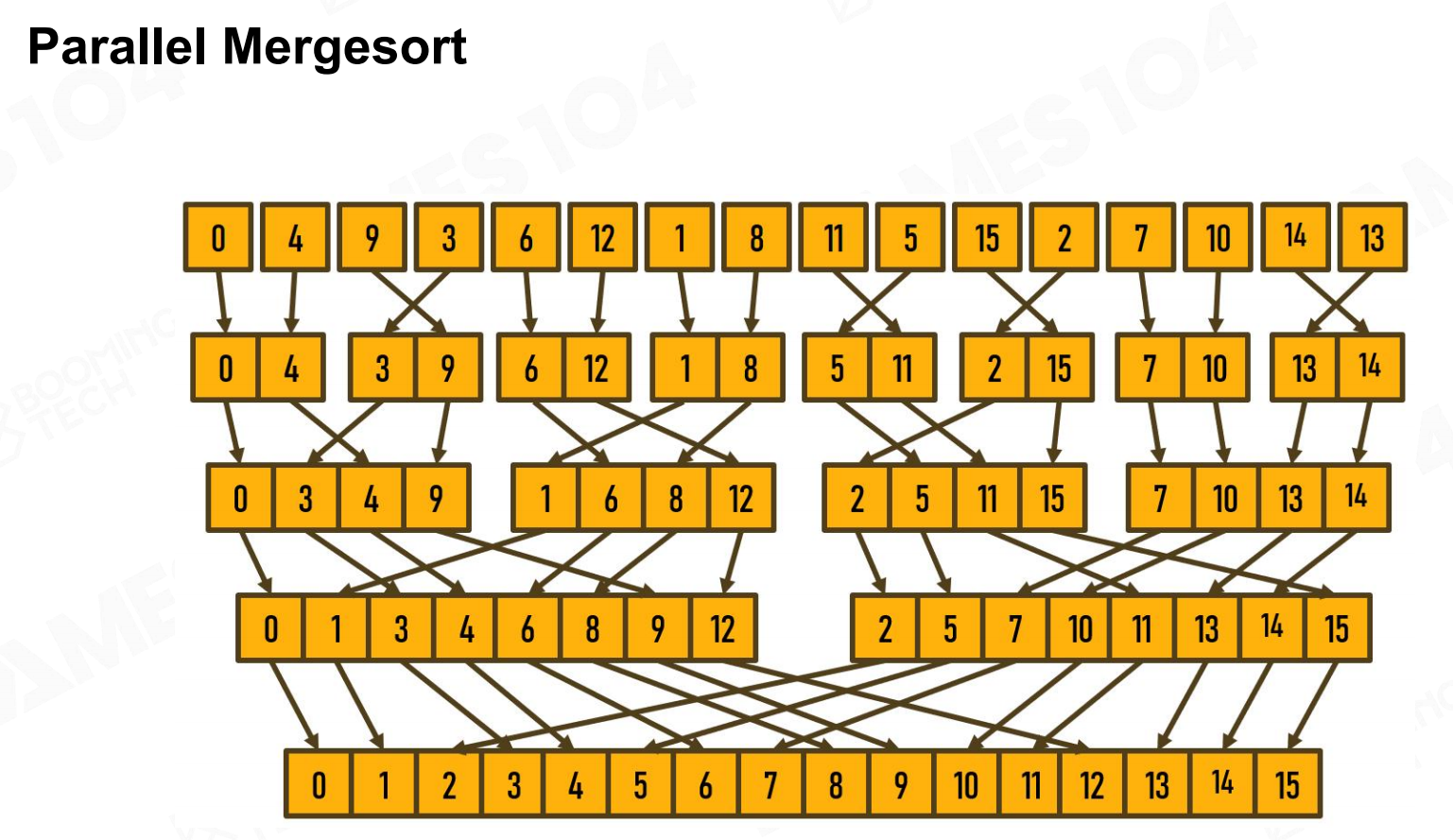 并行合并排序
并行合并排序
在合并两个有序数组时还可以使用从目标队列出发寻找源队列的方式进一步提升性能。 并行合并排序2
并行合并排序2
深度缓冲区碰撞(Depth Buffer Collision)
除此之外还可以在GPU中进行粒子和场景的碰撞检测。出于计算效率方面的考虑,
在对粒子进行碰撞检测时一般只会使用屏幕空间和深度图来简化计算。 深度缓冲区碰撞
深度缓冲区碰撞
粒子应用(Advanced Particles)
人群模拟(Crowd Simulation)
现代游戏的粒子系统已经远不局限于实现不同的视觉特效,实际上我们可以基于粒子系统来实现更加丰富的功能。
比如说游戏中大量NPC的运动行为就可以利用粒子系统进行实现。此时每个粒子不仅仅具有常见的物理属性, 还会携带顶点等几何信息。 动画粒子网格
动画粒子网格
基于粒子的几何信息还可以让NPC动起来,甚至可以利用状态机的理论制作简单的动画。 粒子动画贴图
粒子动画贴图
基于SDF的相关技术还可以控制群体的运动行为。 导航贴图
导航贴图 人群运行时行为
人群运行时行为
在虚幻5引擎中就实现了非常强大的粒子系统,从而方便开发者设计各种复杂的玩法和场景。 高级粒子展示
高级粒子展示 高级粒子展示2
高级粒子展示2
在游戏中使用粒子系统(Utilizing Particle System in Games)
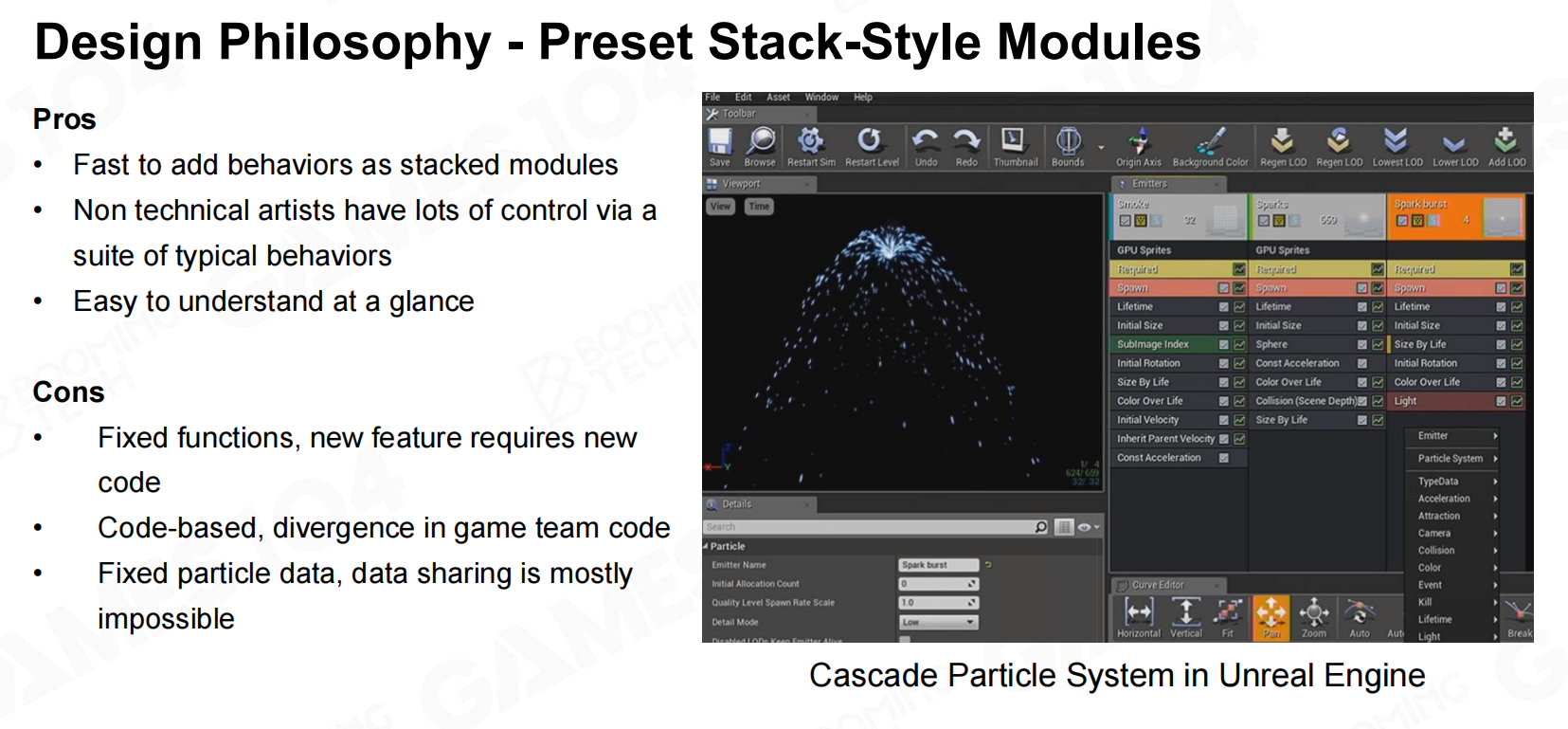 设计理念-预设堆叠式模块
设计理念-预设堆叠式模块 设计理念-基于图形的设计
设计理念-基于图形的设计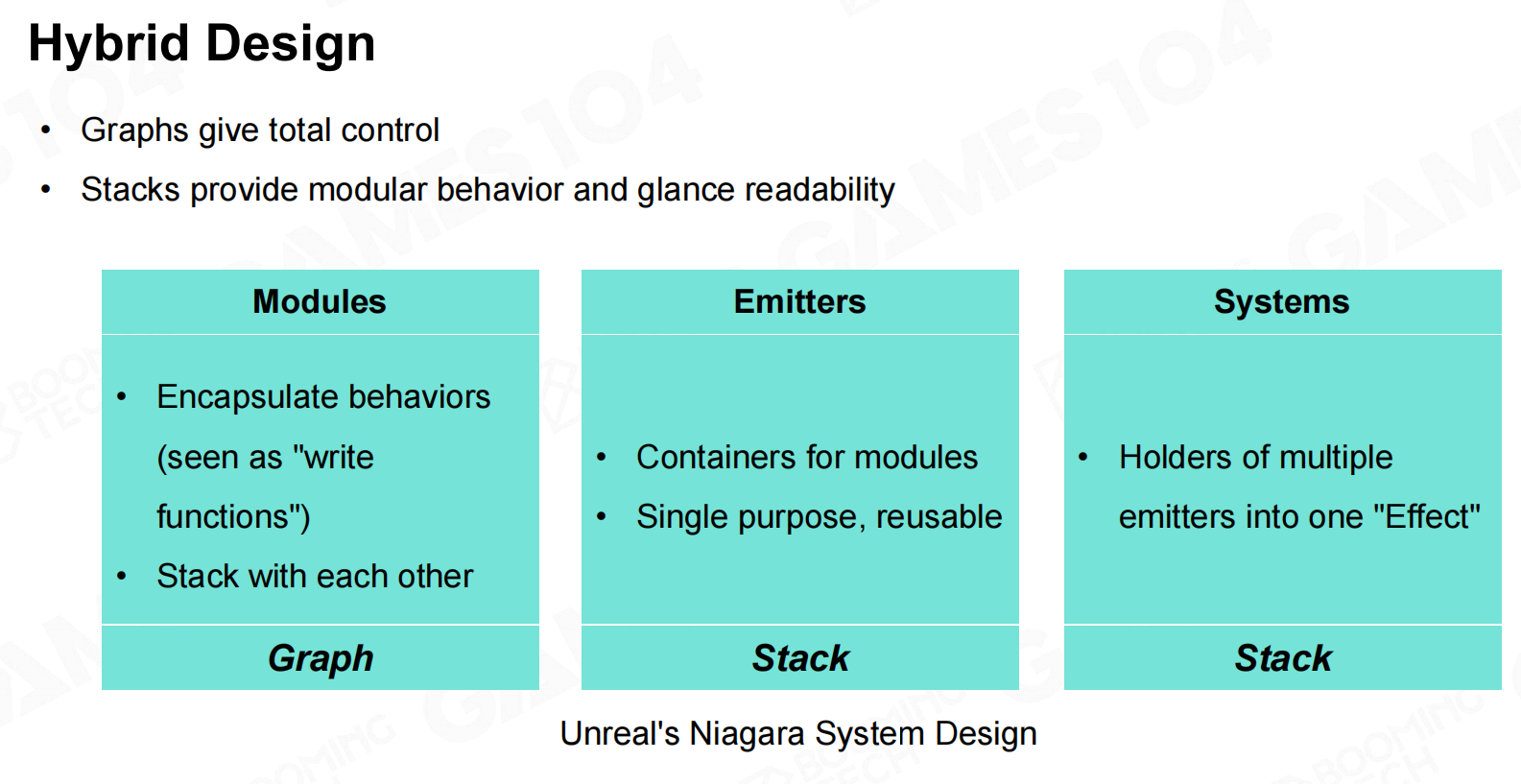 混合动力设计
混合动力设计
声音系统(Sound System)
声音基础
音效是影响游戏氛围和玩家体验的重要一环,很多游戏都需要使用大量的音效来调动玩家的情绪。 声音
声音
声音的大小称为音量(volume),它表示声波的振幅。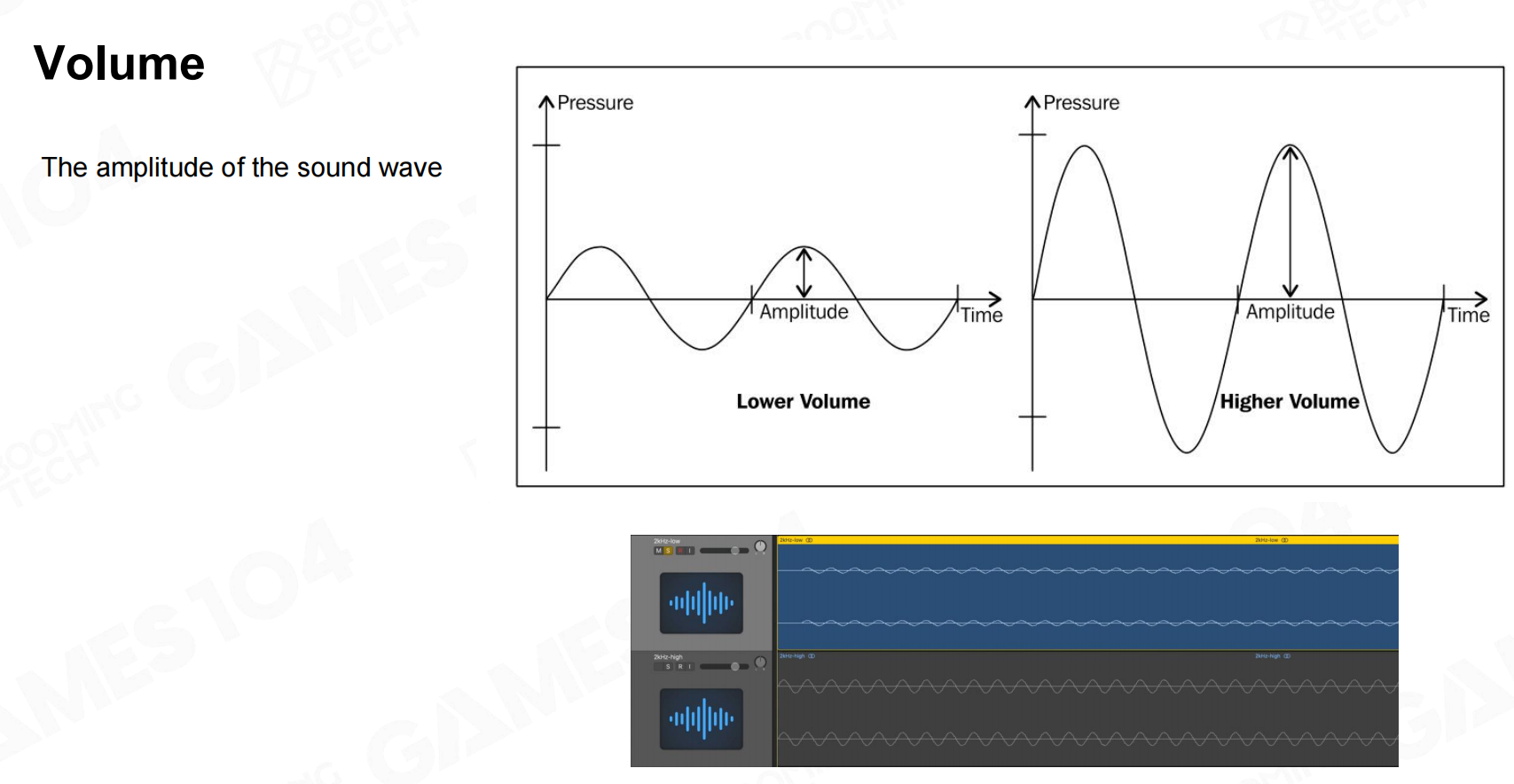 音量
音量
从物理的角度上讲,声音的本质是空气的振动。当空气发生振动时会产生相应的压强,这个压强的大小就对应人感知到的音量。
音量的单位是分贝(dB),它是基于人对于声音的感知来定义的。 音量术语
音量术语 音量术语2
音量术语2
音高(pitch)是描述人耳对声音调子感受的物理量,它取决于声音振动的频率。音高越高,声音就越尖锐。 音高
音高
音色(timbre)是描述声波形状的量。不同的乐器在演奏时会产生不同形式的基波,因此即使声波的频率相同也会产生不同的音色。 音色
音色
由于声音的本质是空气振动,我们可以在接收端叠加一个与当前振动相反的振动从而产生静音的效果。这就是现代降噪耳机的基本原理。 降噪
降噪
人耳对不同频率声音的感受范围可参考下图: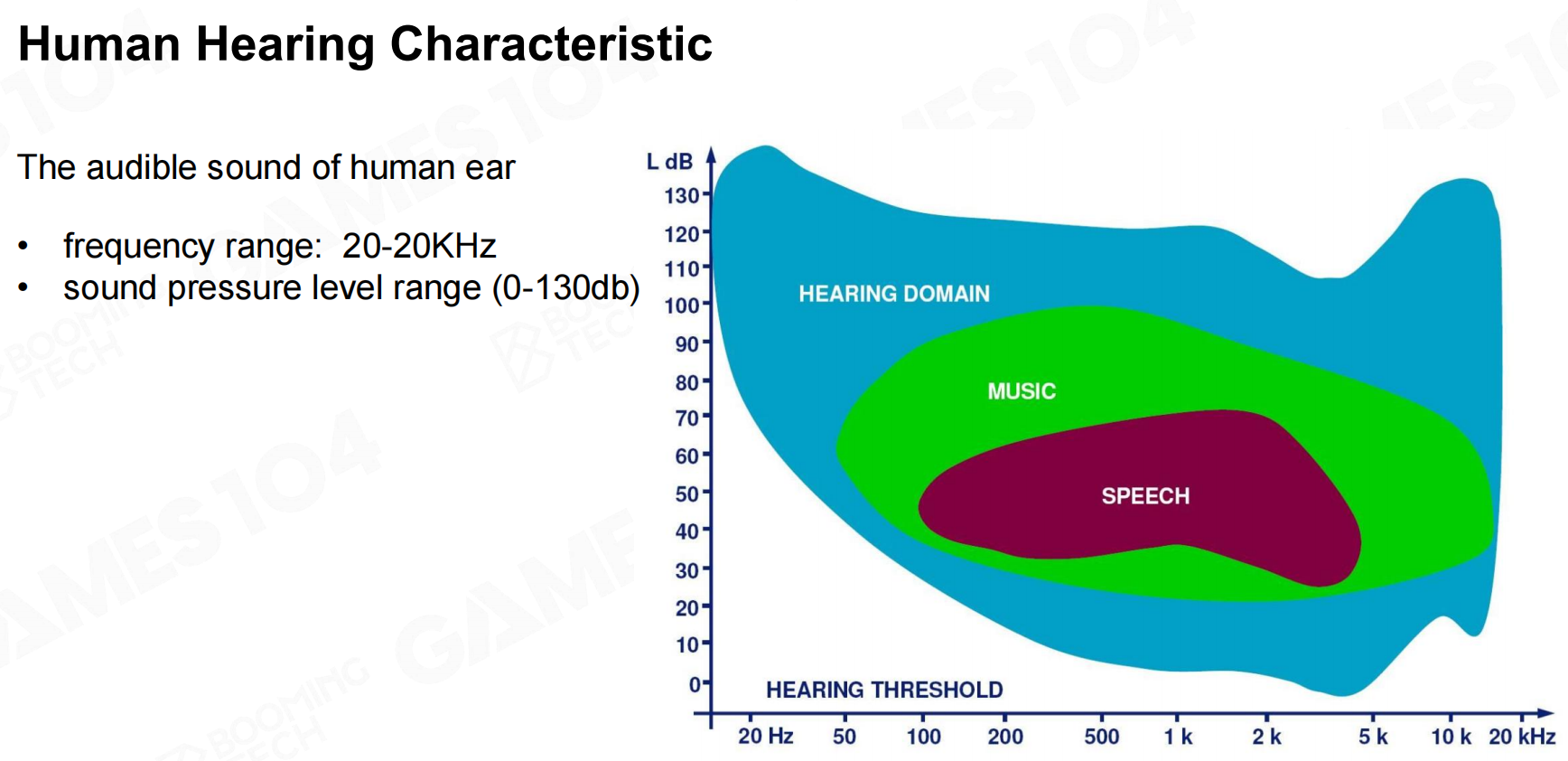 降噪
降噪
数字声音(Digital Sound)
自然界中的声音是连续的信号,因此要使用计算机存储或者表达声音就需要对连续的信号进行离散。
最常用的声音采样设备是PCM(pulse-code modulation),它可以把连续的信号量化为离散的数字信号。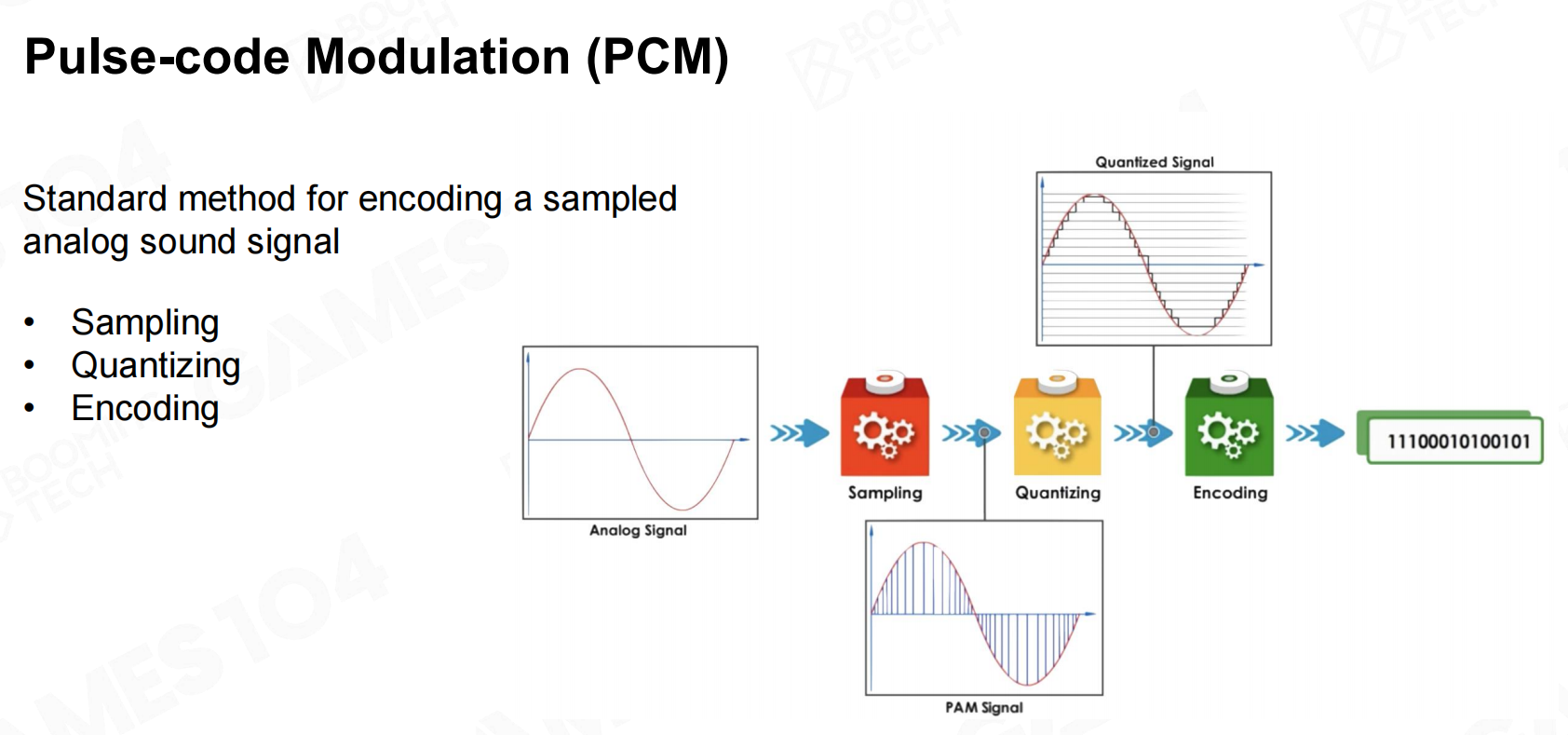 PCM
PCM
根据Nyquist采样定理,我们只需要2倍于人耳接收频率的采样频率就可以完美的重建原始信号。
不过在实际采样时往往会使用更高一些的采样频率来获得更好的音质。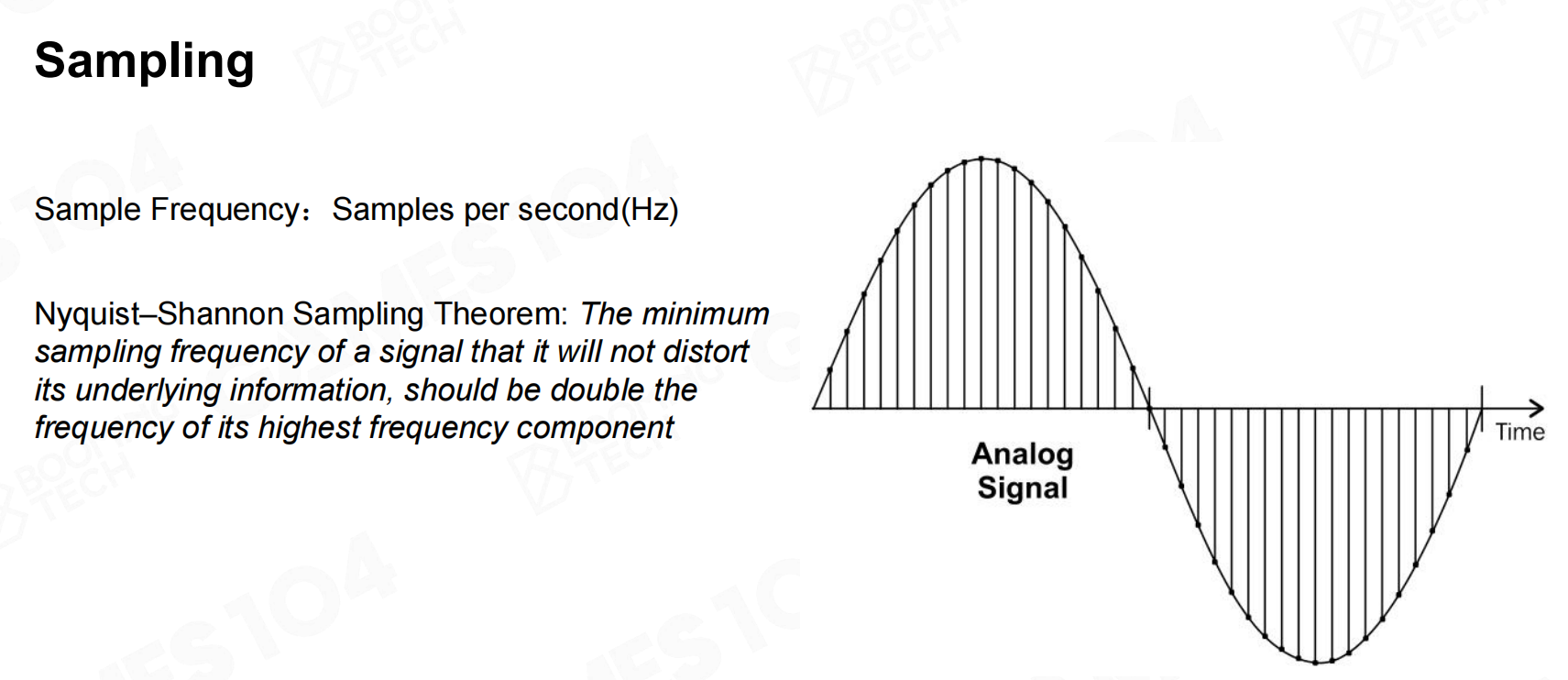 取样
取样
采样后的信号需要通过量化的过程编码为数字。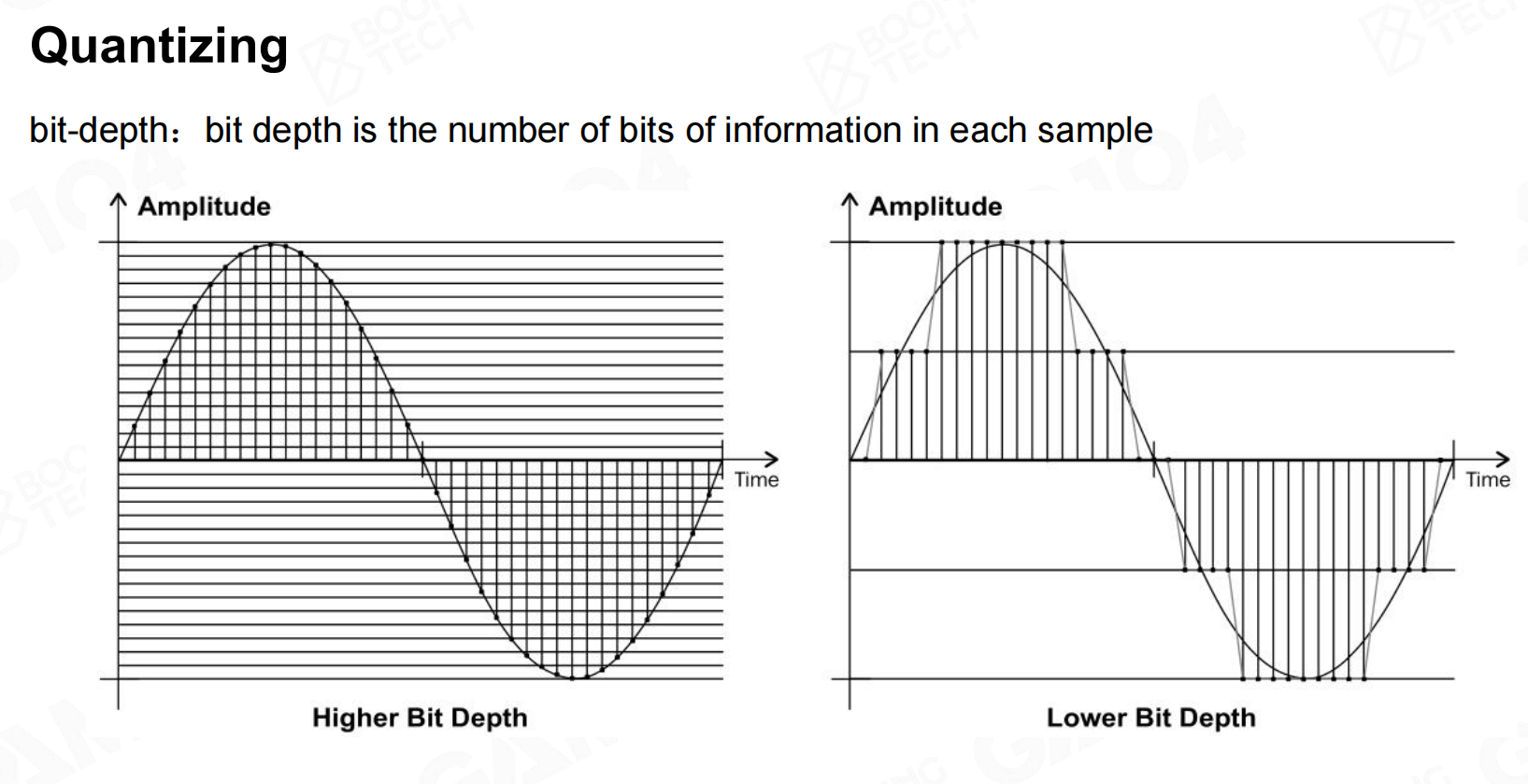 量化
量化
基于上面介绍的过程就可以把声音使用计算机可以识别和保存的数据。目前常用的声音格式如下: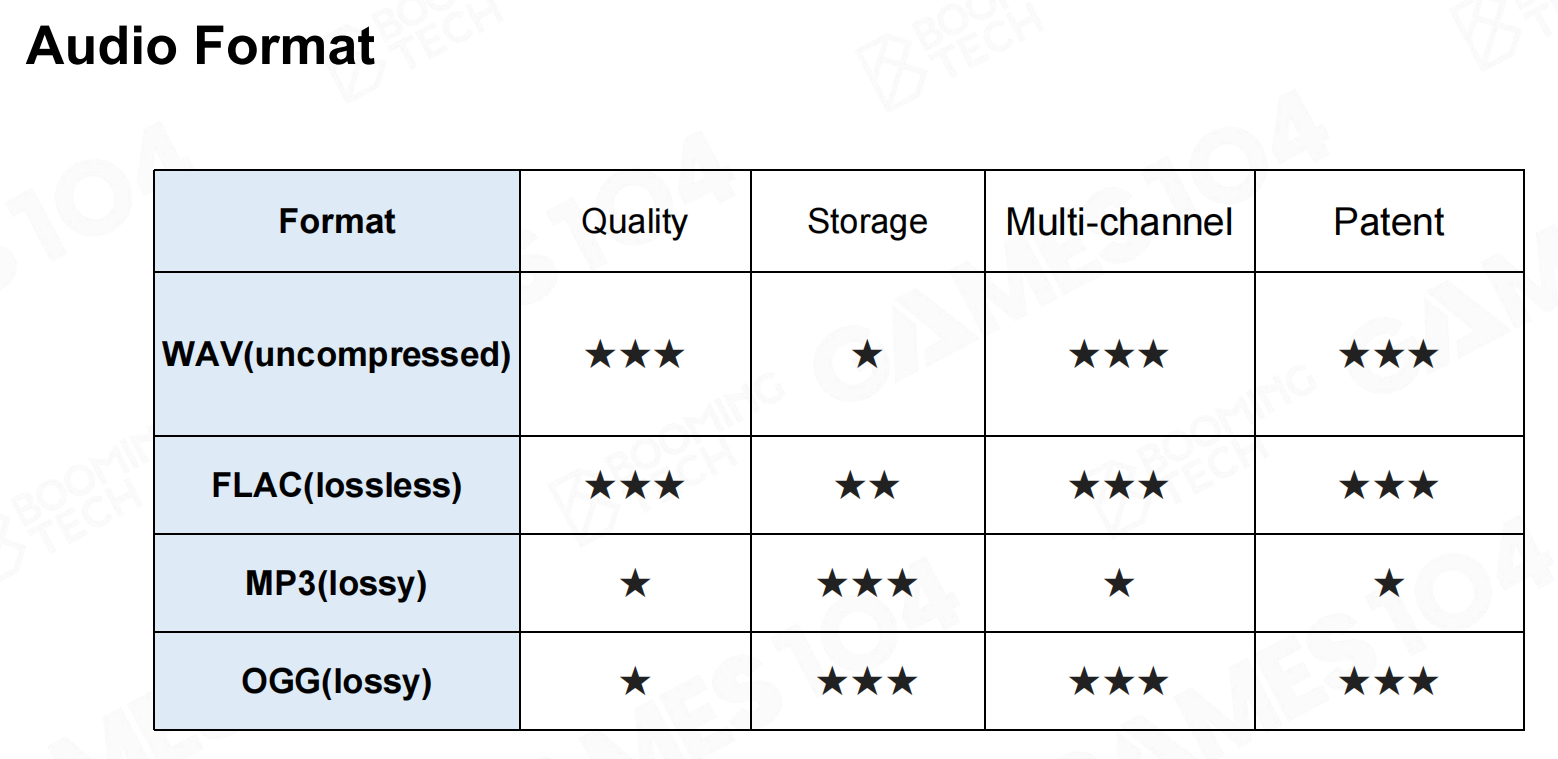 音频格式
音频格式
三维音频渲染
在游戏设计中我们需要在三维的环境里设置音效从而让玩家有身临其境的感受,因此我们需要设置一个虚拟的麦克风来采集场景中的声音。
通常情况下这个虚拟麦克风需要包含位置、速度以及朝向等物理信息。 3D声源
3D声源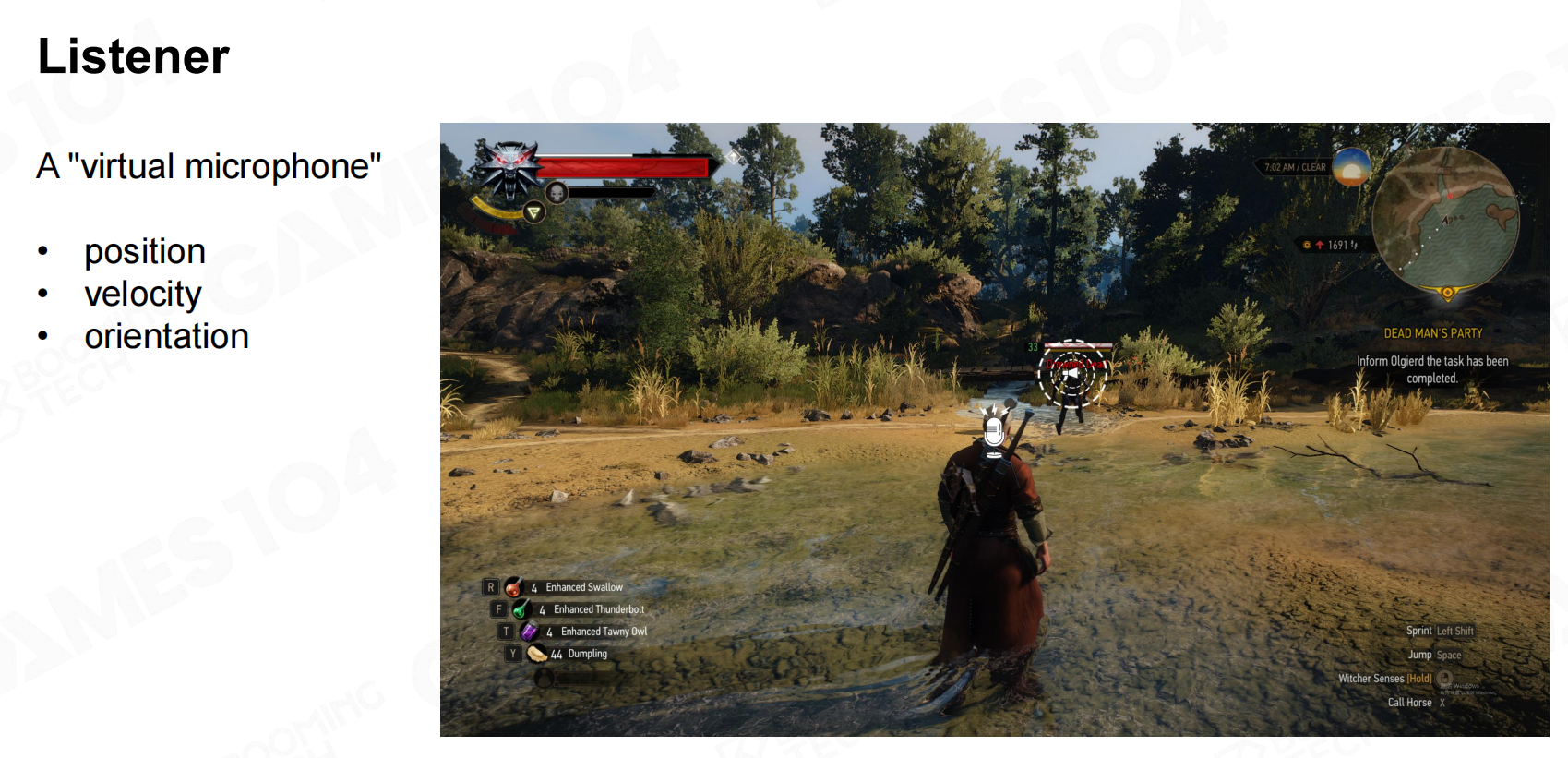 接收
接收
对于人耳而言,我们可以利用双耳之间接收声音细微的变化来判断声源的大致位置。因此在游戏音效系统中可以利用人耳的这种效应来制造空间感。 空间定位
空间定位
位移(Panning)
当音响有多个通道时我们可以调整不同音响的参数来产生空间感,这种方法称为panning。最简单的panning是进行线性插值
,假设有某个声源从前方经过,我们可以对左右两通道的声音进行线性插值来模拟这种效果。 扇形位移
扇形位移 线性位移
线性位移
实际上人耳对于声音的感知是一个非线性函数,因此我们可以使用平方函数来改进线性插值的效果。
此时会出现当声源经过正前方时接收到的声音会小一点。 线性位移2
线性位移2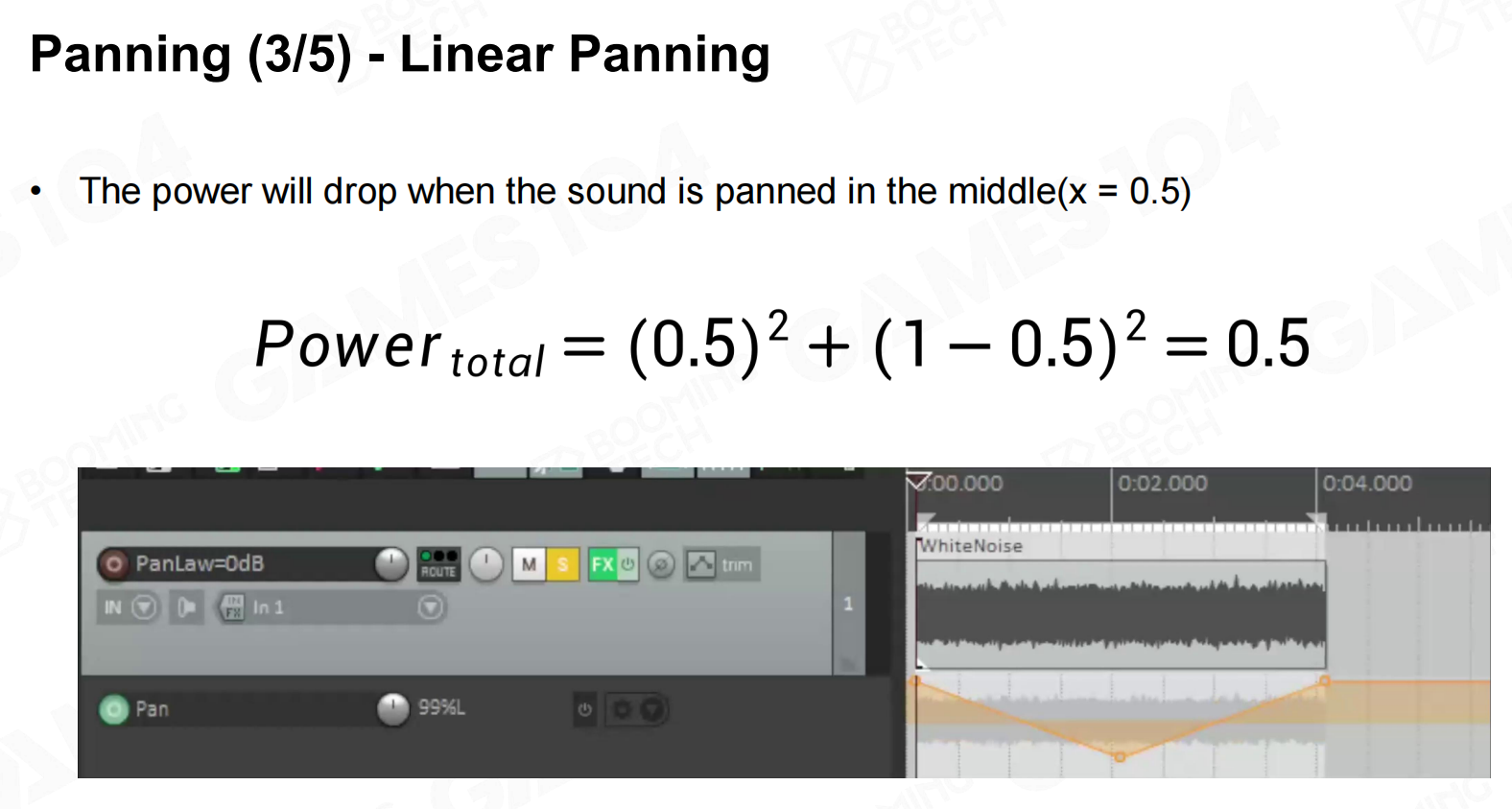 线性位移3
线性位移3
更进一步还可以使用三角函数来描述声音的变化,这样可以得到更逼真的效果。 线性位移4
线性位移4
当然实际游戏中的panning算法会比上面介绍的要复杂得多,也可以表达更加复杂的空间位置变化。 线性位移5
线性位移5
衰减(Attenuation)
当声源远离麦克风时会出现衰减(attenuation)的现象,随着距离的增加虚拟麦克风能接受到的声音会不断减少。
实际上不仅是接收到的音量会发生变化,距离也会对接收到声音的频率产生一定的影响。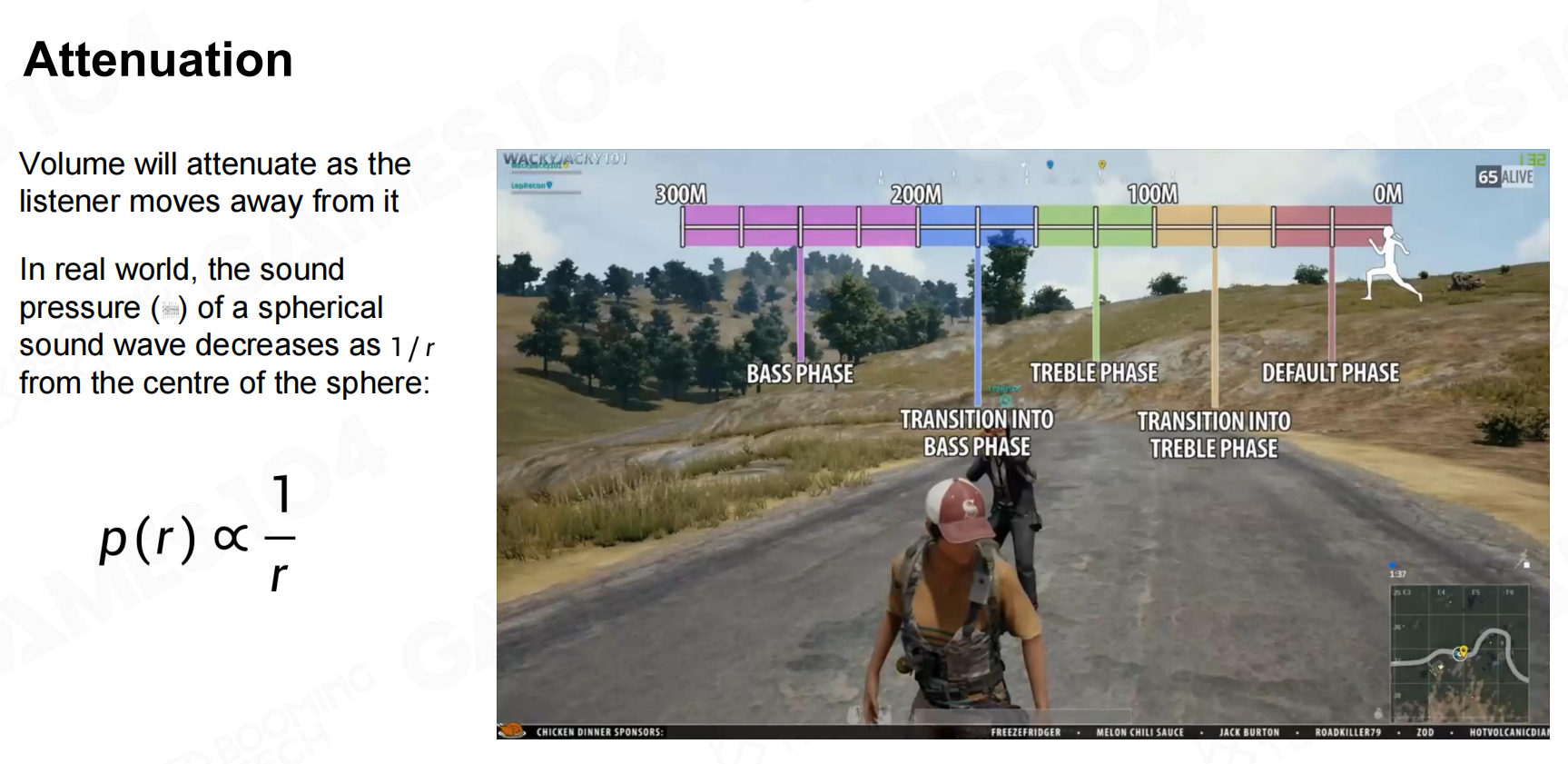 衰减
衰减
最简单的衰减模型是球形衰减,此时声音的变化只与声源和麦克风之间的距离有关。 衰减形体 - 球体
衰减形体 - 球体
更复杂的模型是胶囊形的衰减模型,它主要与麦克风到中心轴的距离相关。当接收端沿轴方向运动时声音的衰减基本保持不变。 衰减形体 - 胶囊
衰减形体 - 胶囊
对于室内场景可以考虑盒子形的衰减模型。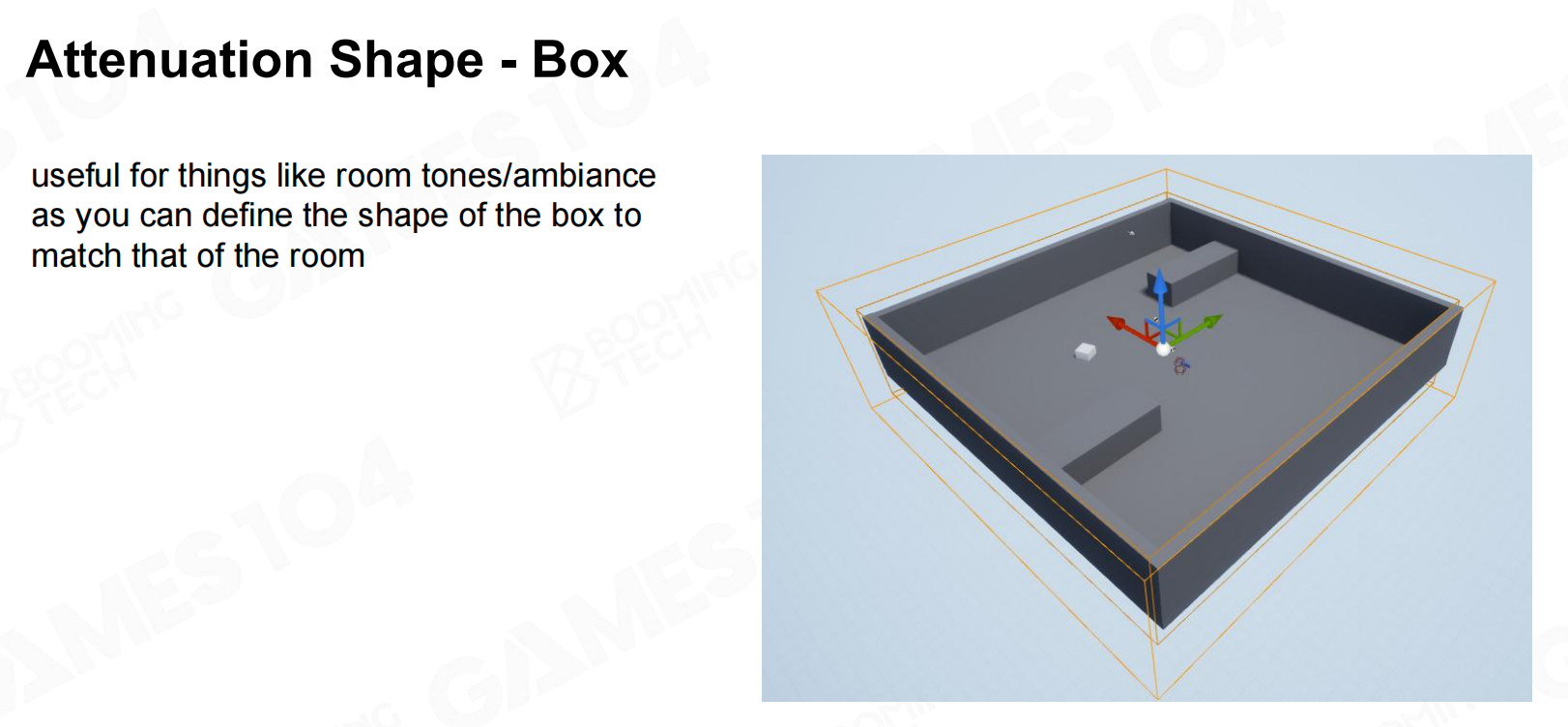 衰减形体 - 盒子
衰减形体 - 盒子
对于高音喇叭这种声源则可以使用锥形的衰减模型描述声源的朝向。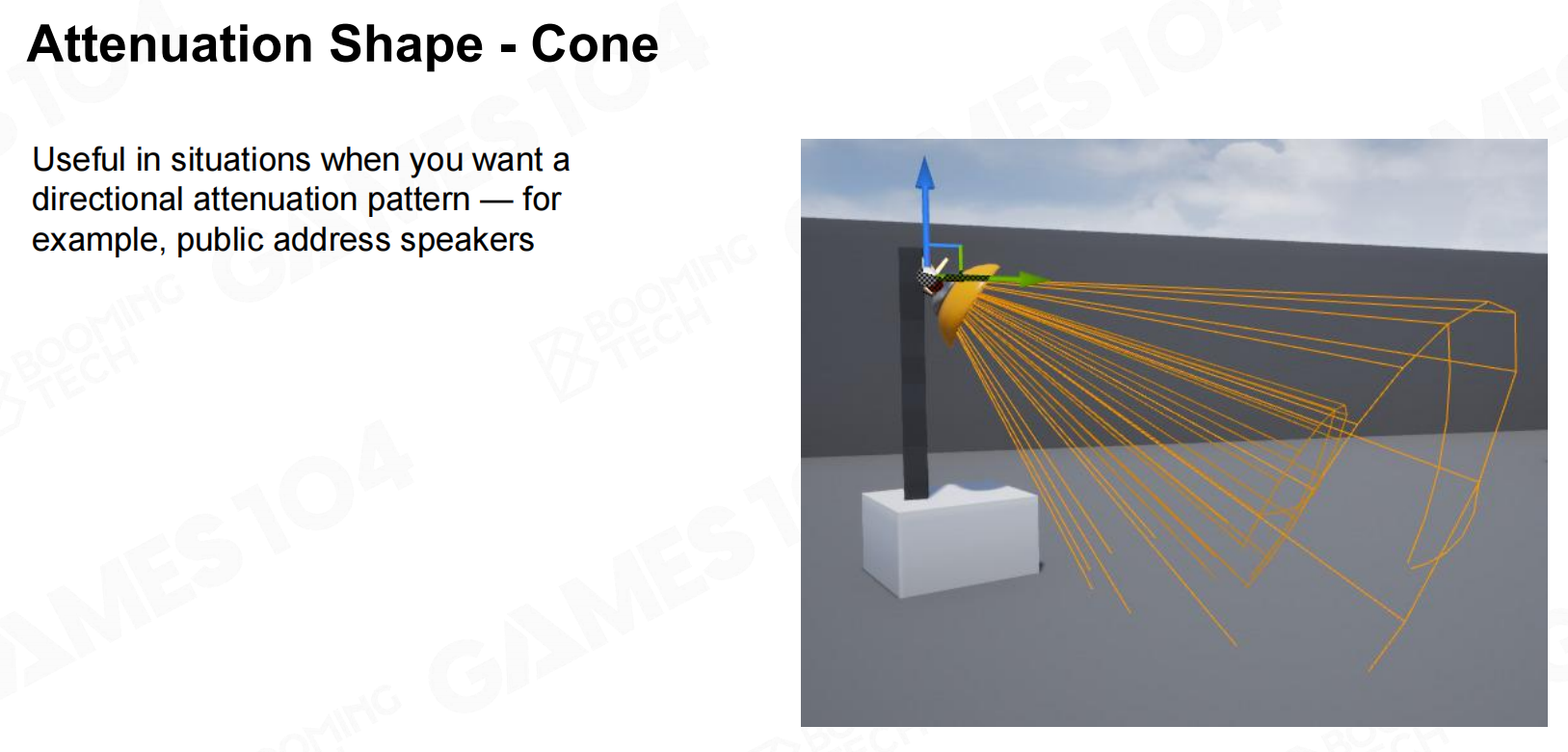 衰减形体 - 锥体
衰减形体 - 锥体
障碍和遮挡(Obstruction and Occlusion)
由于声音的本质是波,在封闭环境中还需要考虑声波与环境的互动。当声音被场景中的障碍物阻挡时可以通过衍射的方式继续传播,
而如果声音的传播被完全阻挡它也可以通过阻挡物自身的振动继续向外传播。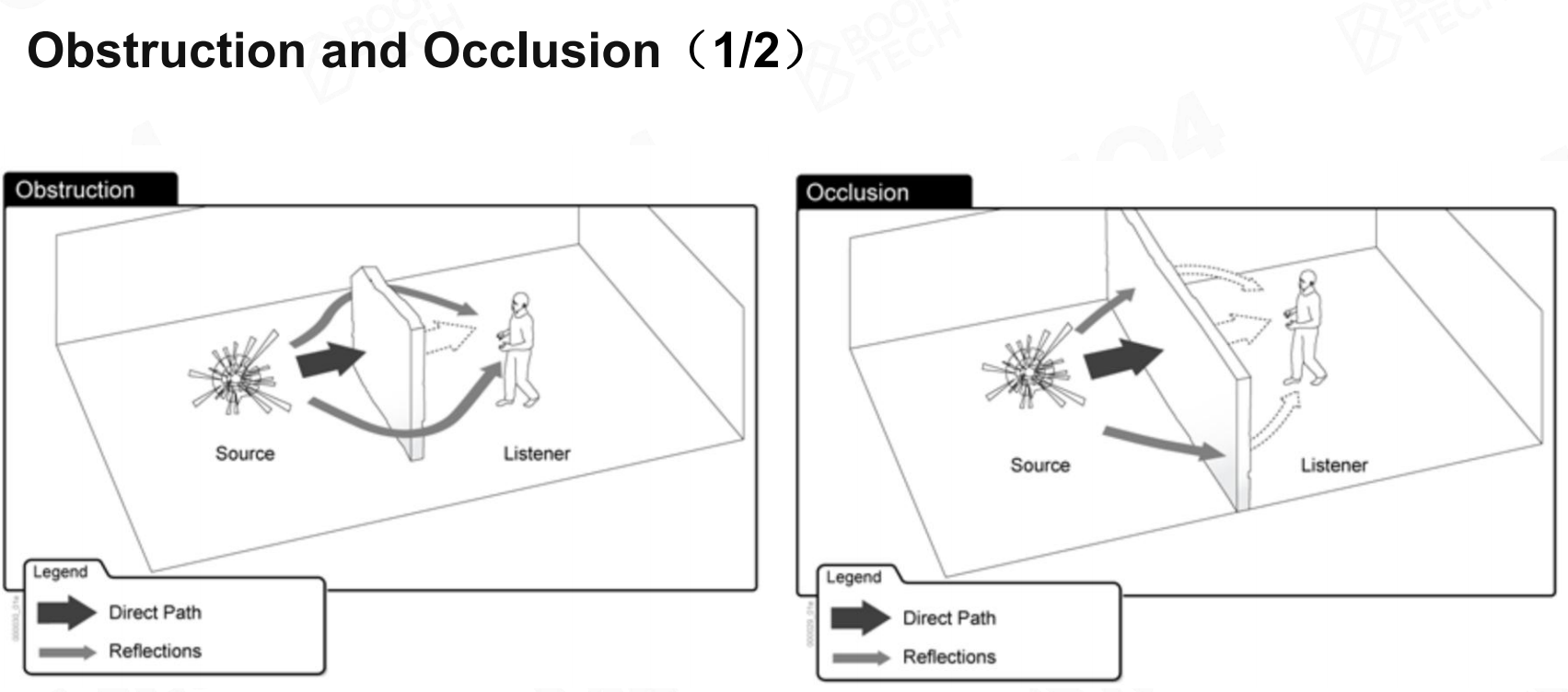 障碍和遮挡
障碍和遮挡
因此在复杂的场景中往往需要使用一些采样的方法来模拟声音传播的效果。 障碍和遮挡2
障碍和遮挡2
混响(Reverb)
除此之外声音在室内场景中还会出现混响(reverb)的现象,这是由于声波在场景中不断反射所导致的。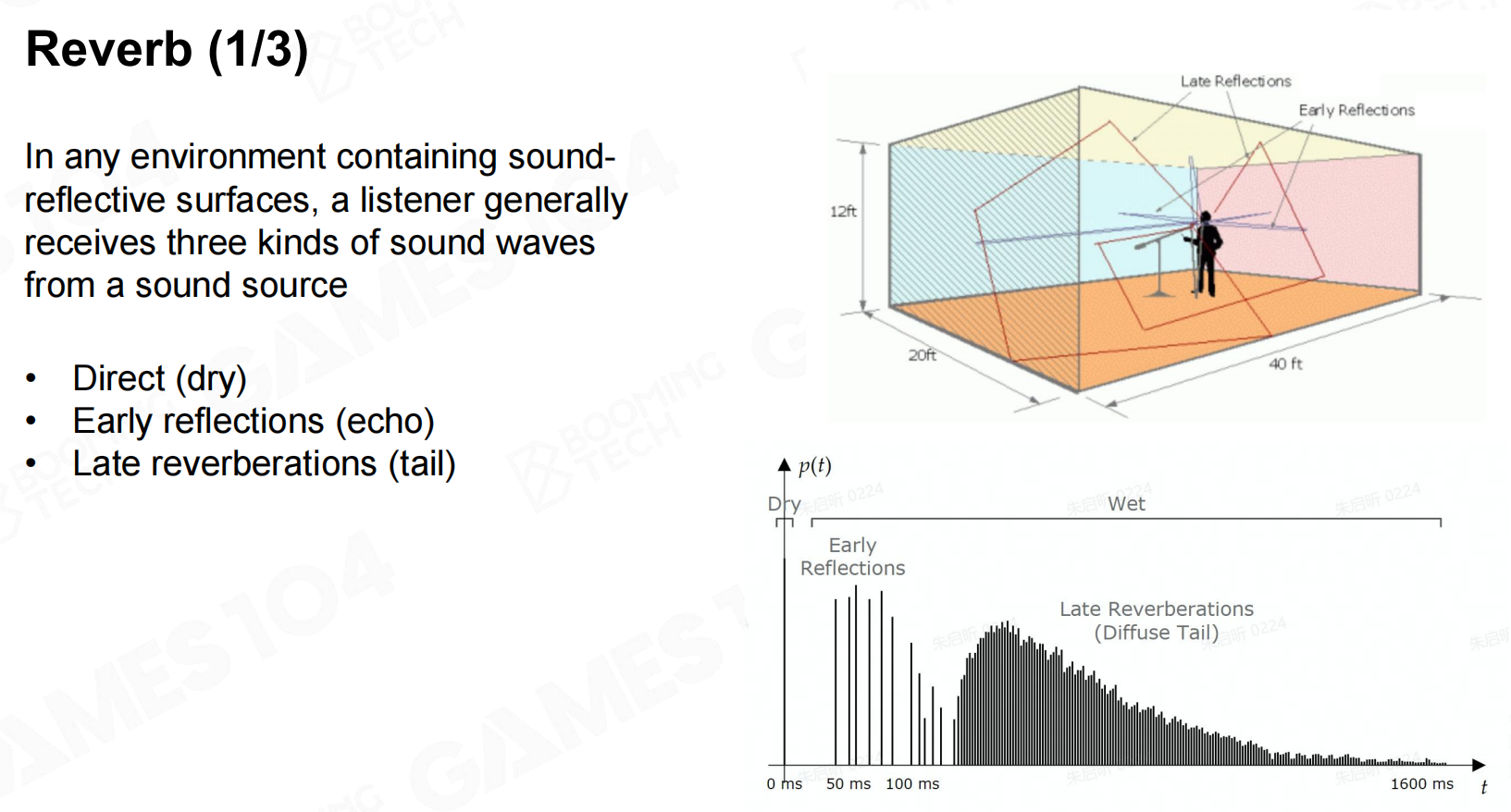 混响
混响
混响的效果很大程度上取决于材质的吸声特性,不同材质往往在不同的频率上有着巨大的性能差异。另一方面混响也取决于场景的几何特征。 混响2
混响2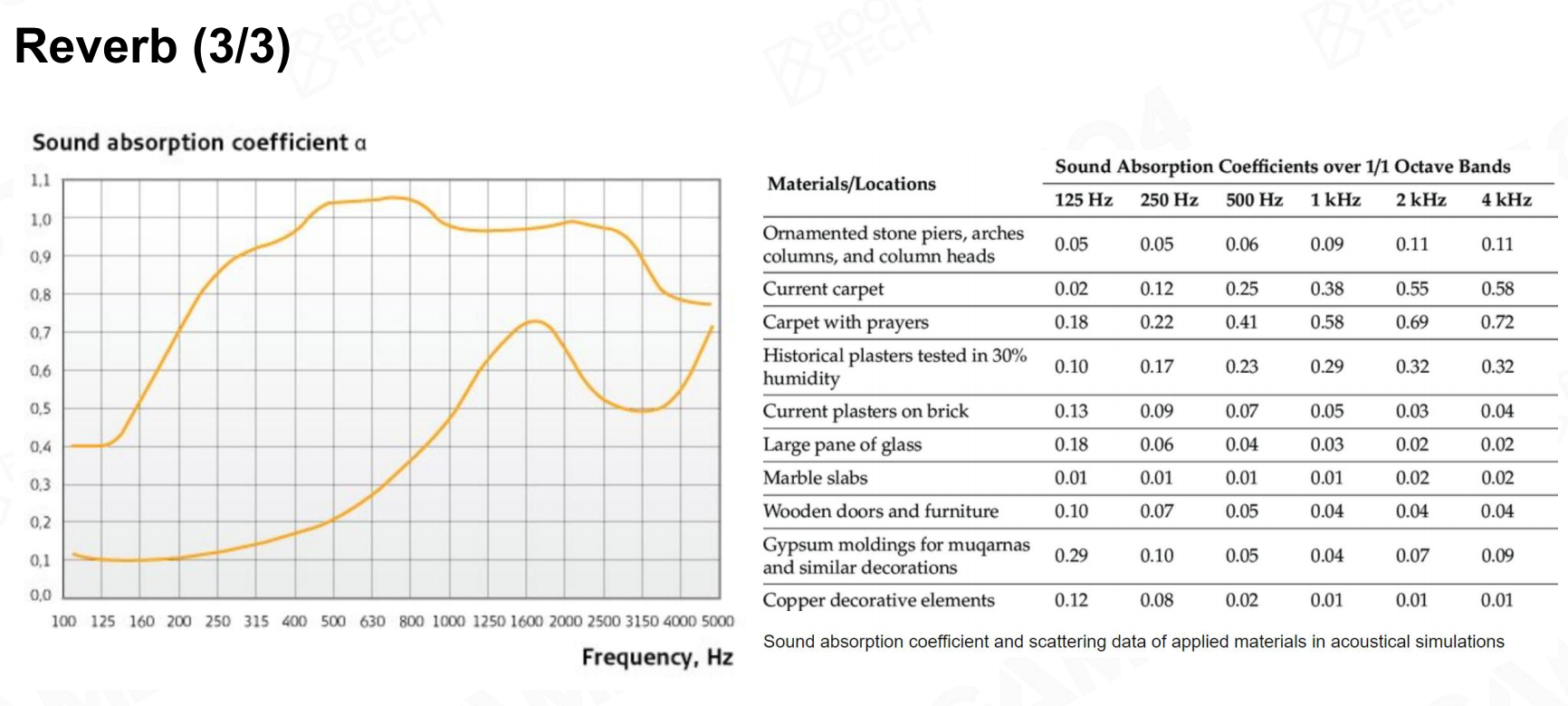 混响3
混响3
通过调整不同的混响组合比例可以实现丰富的声学效果。 基于声学参数的混响效果控制
基于声学参数的混响效果控制
运动中的声(Sound in Motion)
当声源发生运动时由于Doppler效应会导致接收端接收到的频率发生变化。 运动中的声:多普勒效应
运动中的声:多普勒效应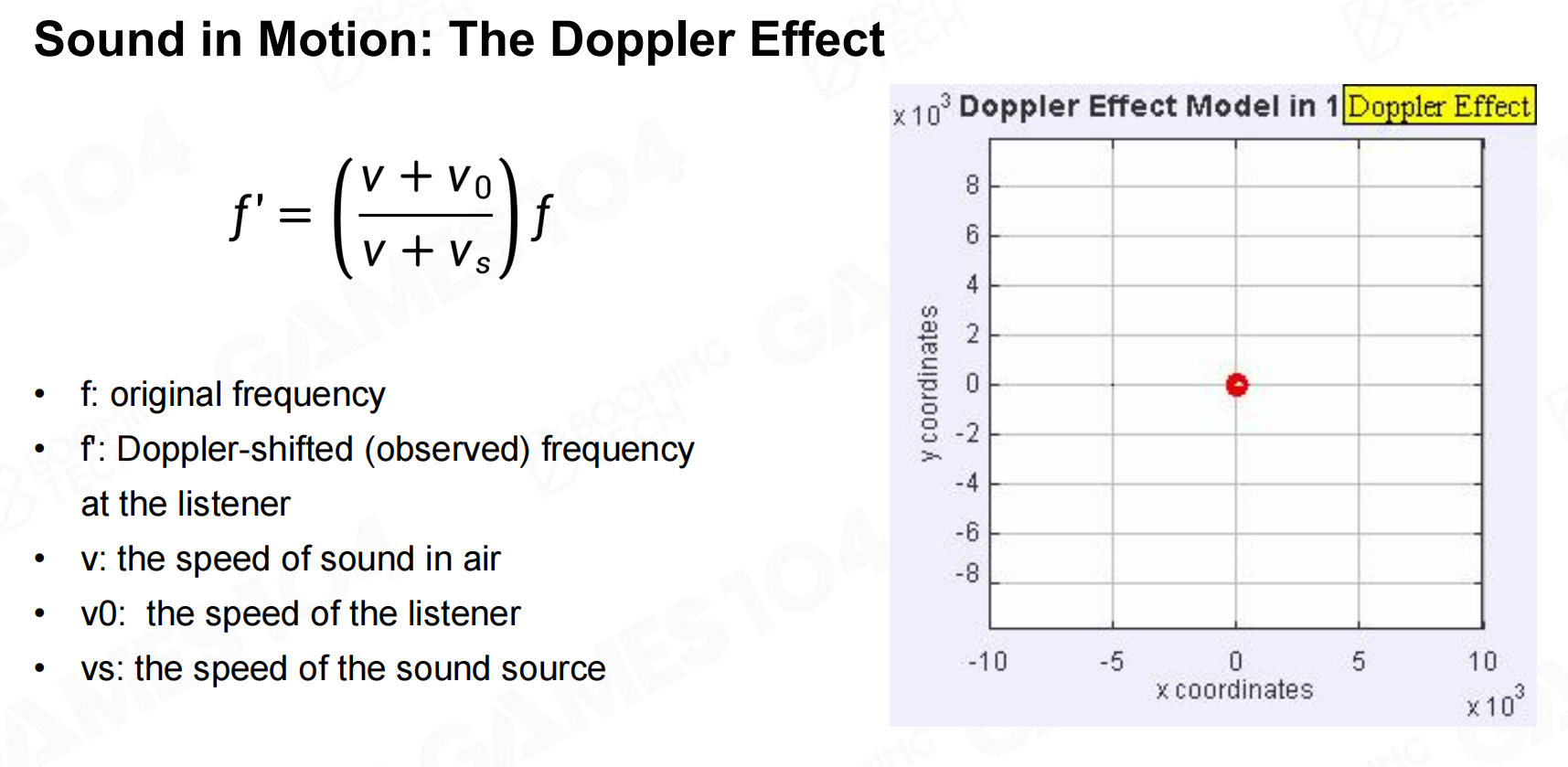 运动中的声:多普勒效应2
运动中的声:多普勒效应2
声场(Sound Field)
很多时候还可以对整个声场进行采集。 空间化-声场
空间化-声场
目前市面上常用的专业级声学引擎包括fmod或wwise等,这些引擎可以更好地辅助专业的声学设计。 常见的中间件
常见的中间件 音频中间件如何工作的
音频中间件如何工作的
目前想要表现大规模场景的声学特性仍是非常复杂的。 模拟音频世界
模拟音频世界
引用
- 本文作者:樱白 - Cherry White
- 本文链接:https://cherry-white.github.io/posts/277d96a5.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!
☕ 如果这篇文章对你有帮助
欢迎请我喝杯咖啡,支持持续创作