
现代游戏引擎 - 面向数据编程与任务系统(二十)
并行编程基础(Basics of Parallel Programming)
随着硬件技术的发展,芯片中晶体管的数量已经接近了物理极限。因此在现代计算机中会使用多核(multi-core)处理器来进一步提升计算性能。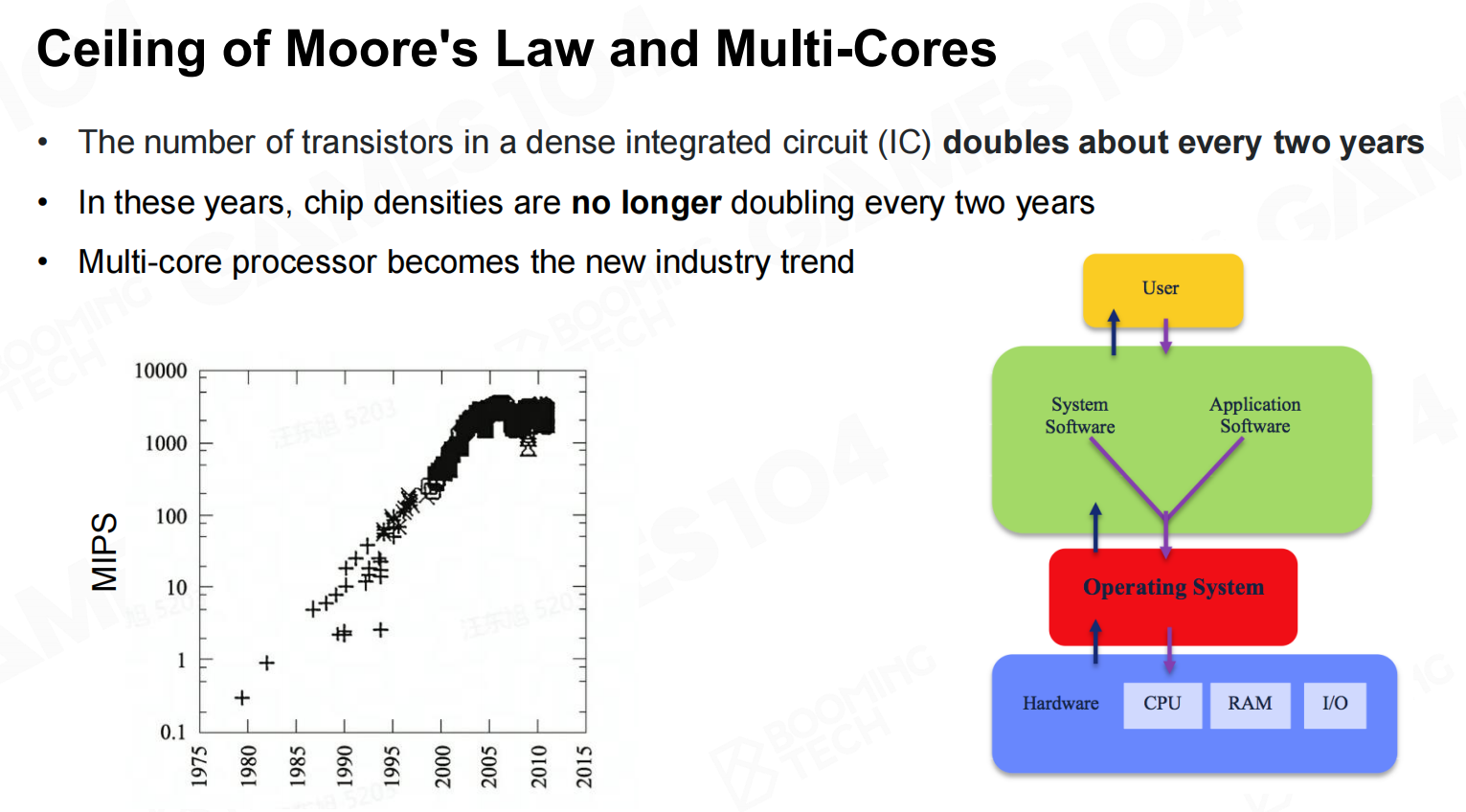 摩尔定律和多核定律的上限
摩尔定律和多核定律的上限
进程和线程(Process and Thread)
进程(process)和线程(thread)是并行编程会涉及到的基本概念。简单来说一个程序就是一个进程,它拥有自己的内存空间;而一个进程可以拥有很多线程,它们会共享进程指向的同一片内存数据。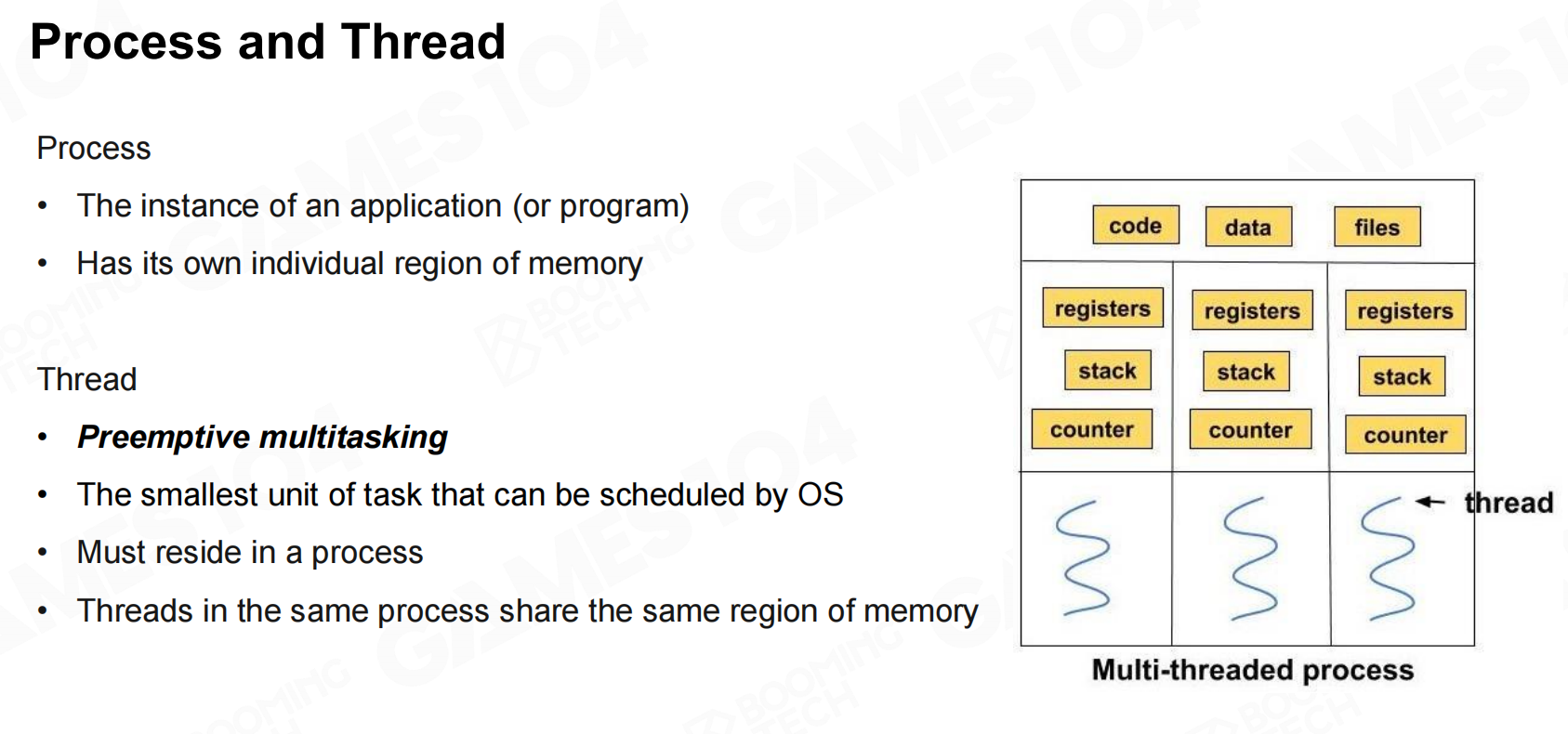 进程和线程
进程和线程
多任务处理的类型(Types of Multitasking)
对于多核的计算机我们希望能够充分利用不同的计算核心来提升程序的性能。根据处理器管理任务的不同可以把进程调度分为两种:抢占式(preemptive multitasking)和非抢占式(non-preemptive multitasking)式。preemptive multitasking是由调度器来控制任务的切换,而non-preemptive multitasking则是由任务自身来进行控制。 多任务处理的类型
多任务处理的类型
线程上下文切换(Thread Context Switch)
线程在进行切换时会产生额外的开销,因此在游戏引擎中我们希望尽可能减少线程的上下文切换。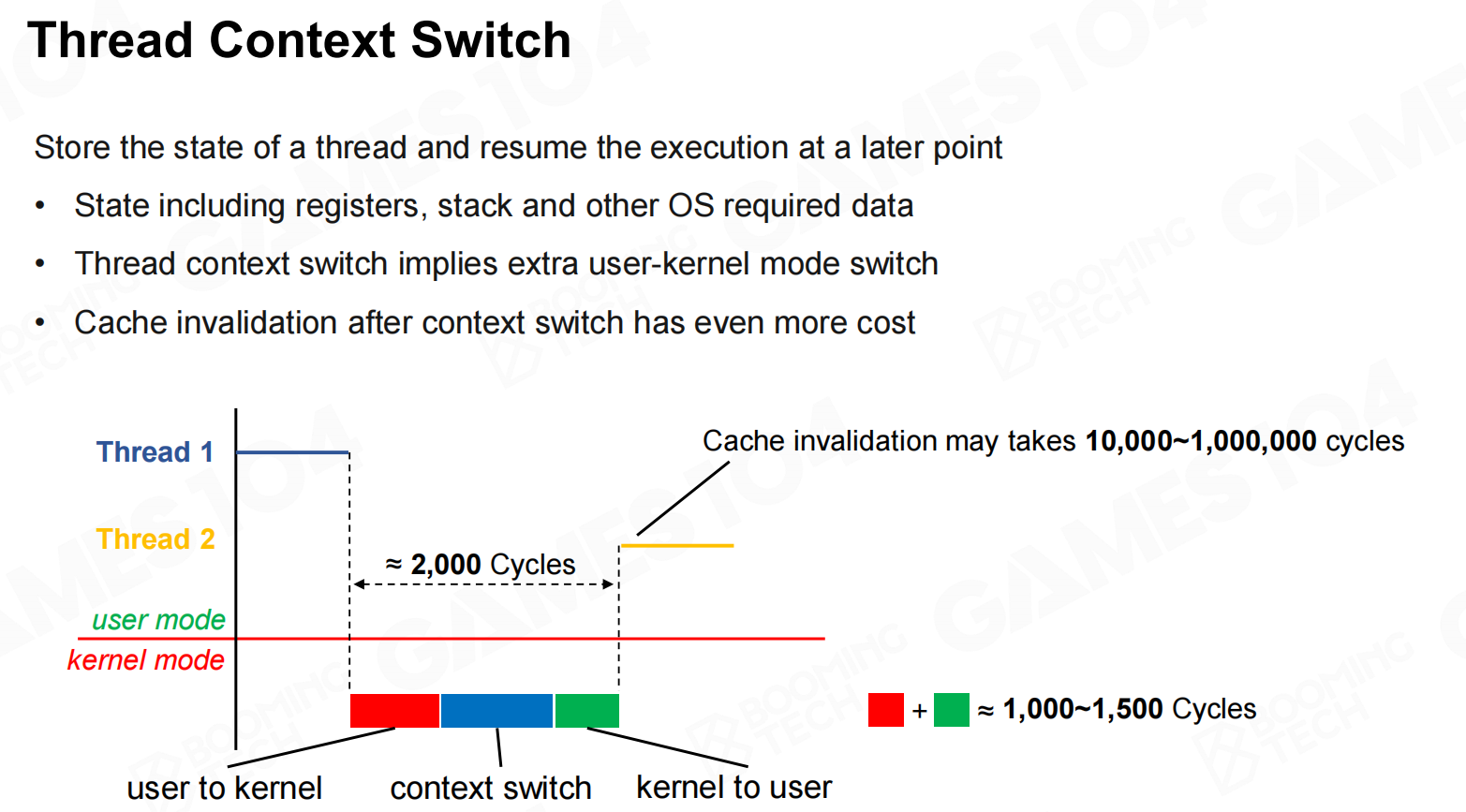 线程上下文切换
线程上下文切换
并行计算中的并行问题(Parallel Problems in Parallel Computing)
在并行程序中我们希望不同的任务之间互不打扰,只需要在程序最后把所有的计算结果进行汇总就好。这样的程序往往有着非常高的运行效率,比如说Monte Carlo模拟就是典型的例子。不过现实中的程序往往不会这样理想,很多任务之间存在各种相互依赖,这会降低程序的运行效率。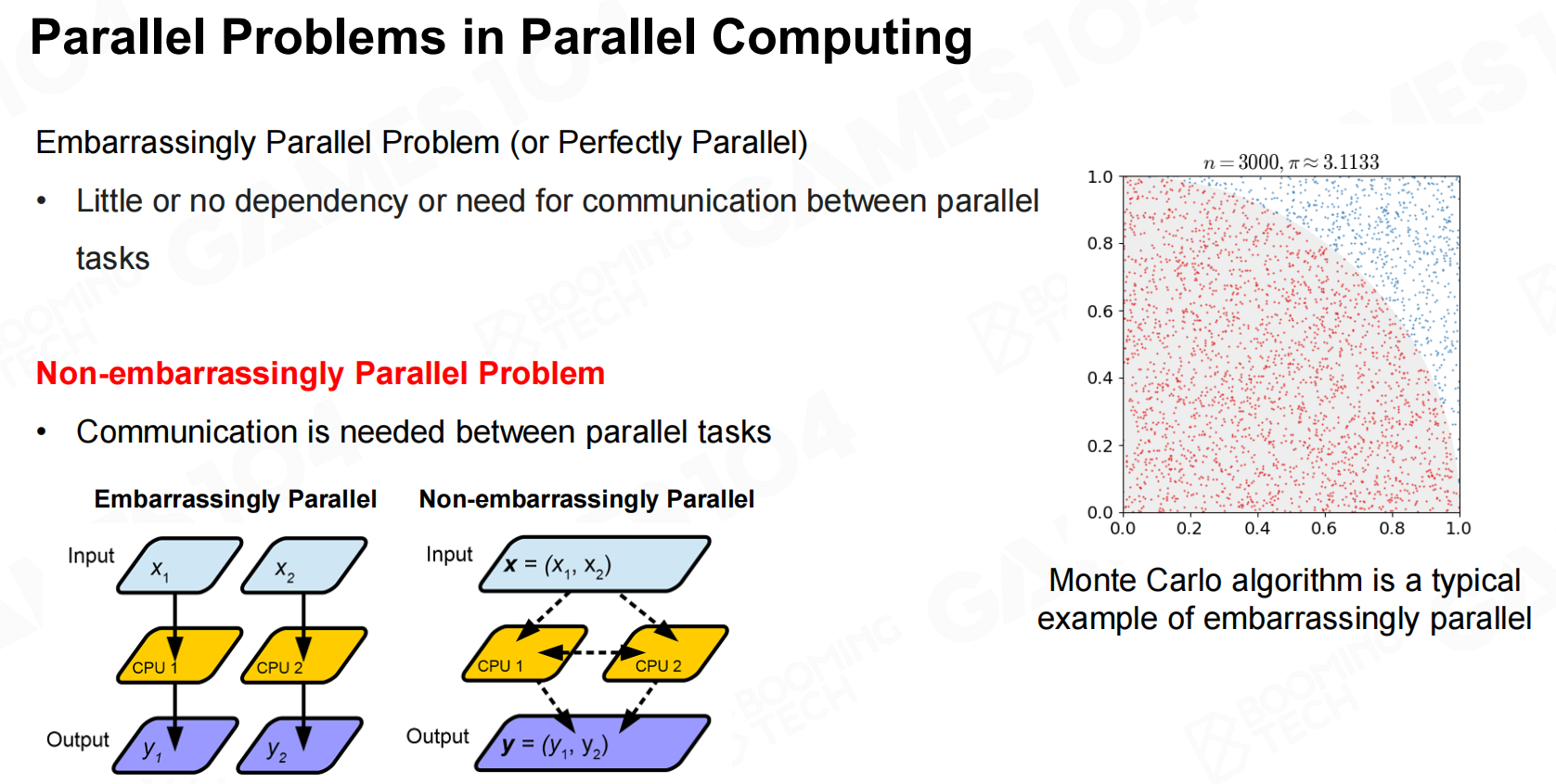 并行计算中的并行问题
并行计算中的并行问题
并行编程中的数据竞争(Data Race in Parallel Programming)
data race是编写并行程序中最常见的问题,当不同的线程想要访问并修改同一块内存时就会产生data race。由于线程的调度是不可预料的,data race会导致程序的计算结果出现各种各样的问题。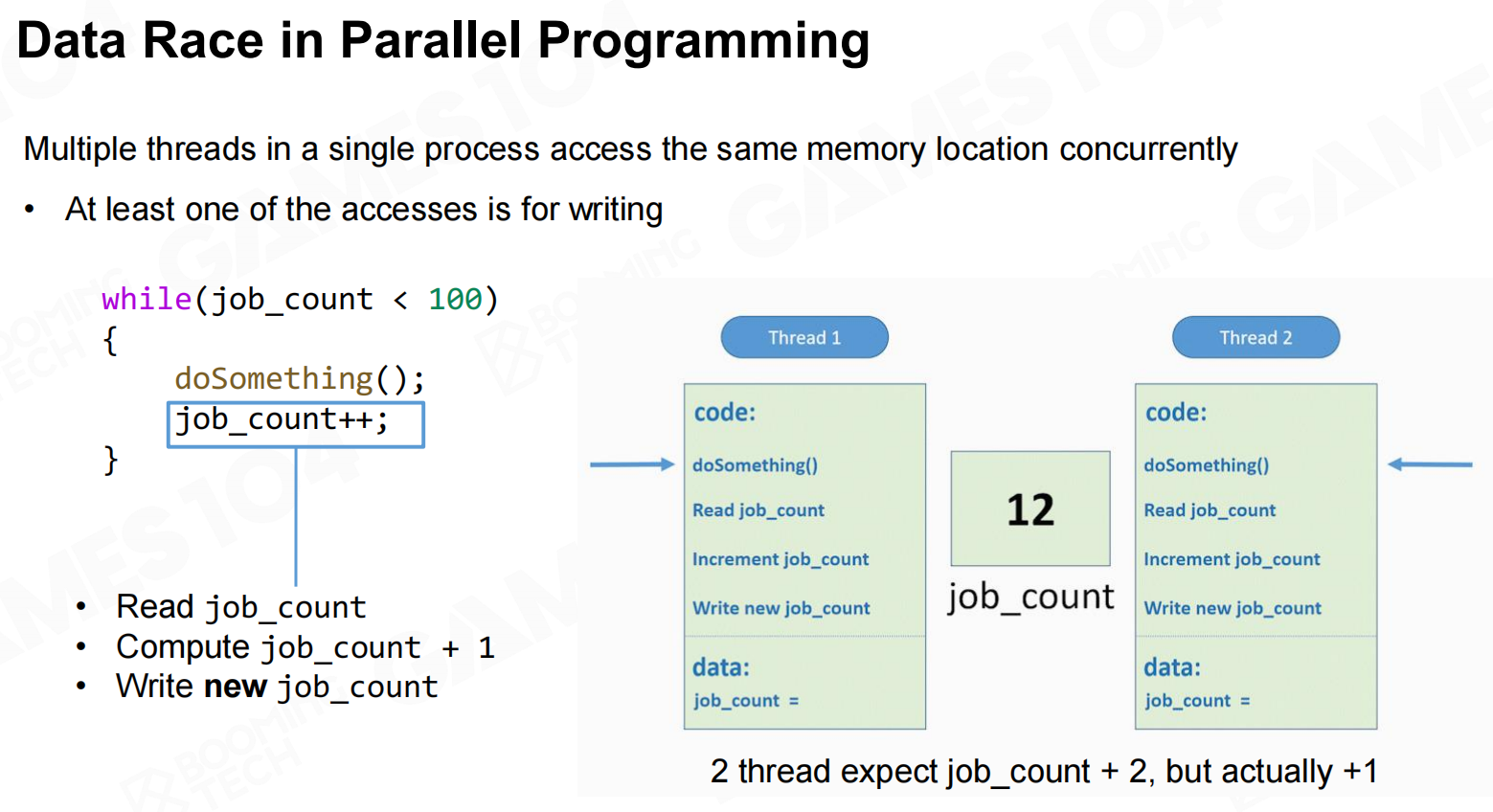 并行编程中的数据竞争
并行编程中的数据竞争
阻塞算法(Blocking Algorithm)
处理data race最简单的方式是给程序上锁(lock),这样可以保证同一时间只能有一个线程对指定的内存区域进行访问。锁之间的程序片断称为critical section,当某个线程执行critical section时其它需要访问同一内存的线程会被强制等待。 阻塞算法
阻塞算法
尽管使用锁可以保证程序的正确执行,但锁的存在会影响程序的并行性。更严重的是它可能会产生死锁(dead lock)的现象从而阻塞程序的运行。因此在编写并行程序时需要注意尽可能减少锁的使用。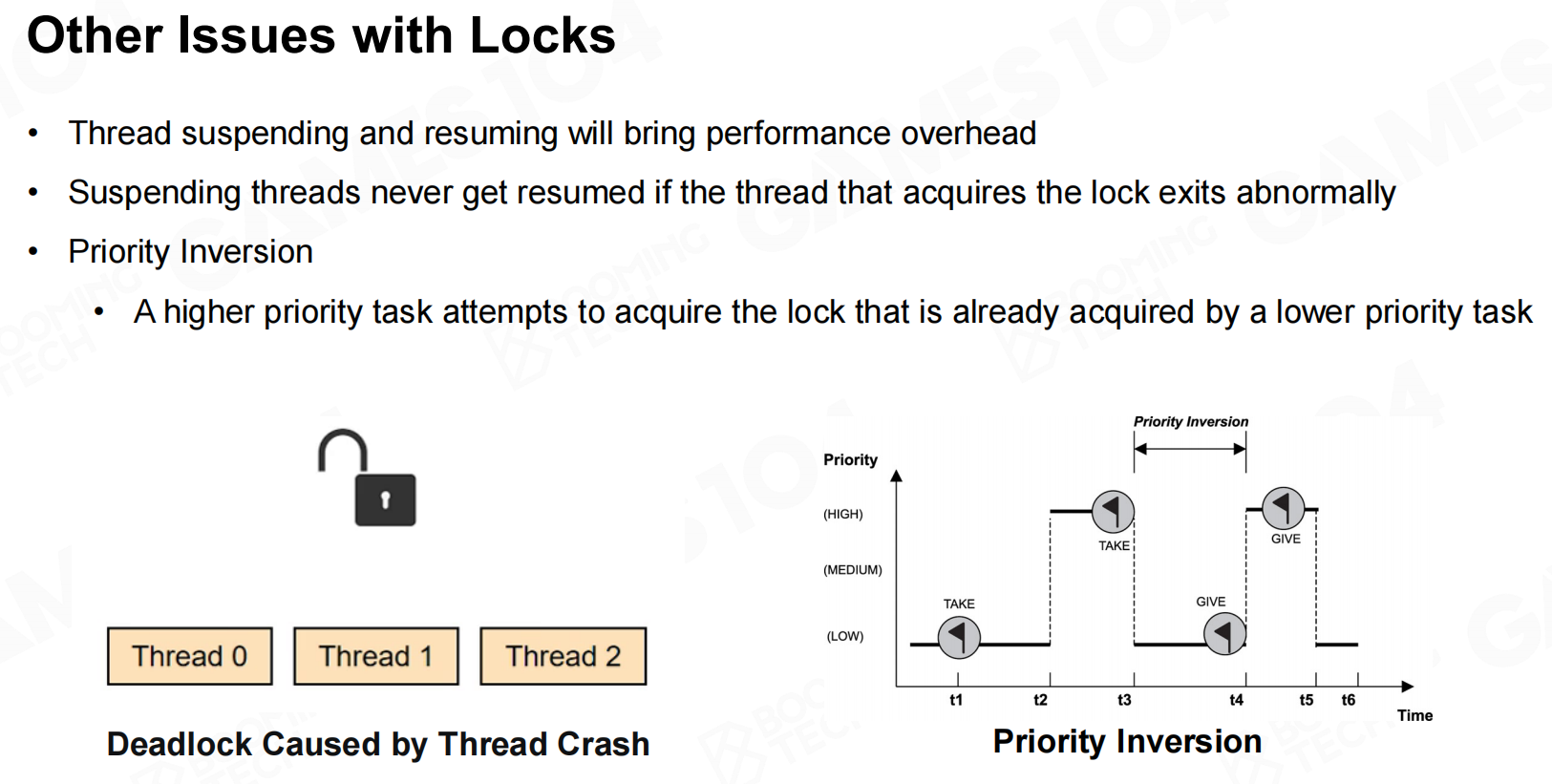 锁的其他问题
锁的其他问题
原子操作(Atomic Operation)
处理data race的另一种常用方法是使用原子操作(atomic operation)。原子操作是硬件层面实现的最基本操作,它无法同时被多个CPU一起执行。利用原子操作可以实现无锁的程序并行,从而极大地提升运行效率。 原子操作:无锁定编程
原子操作:无锁定编程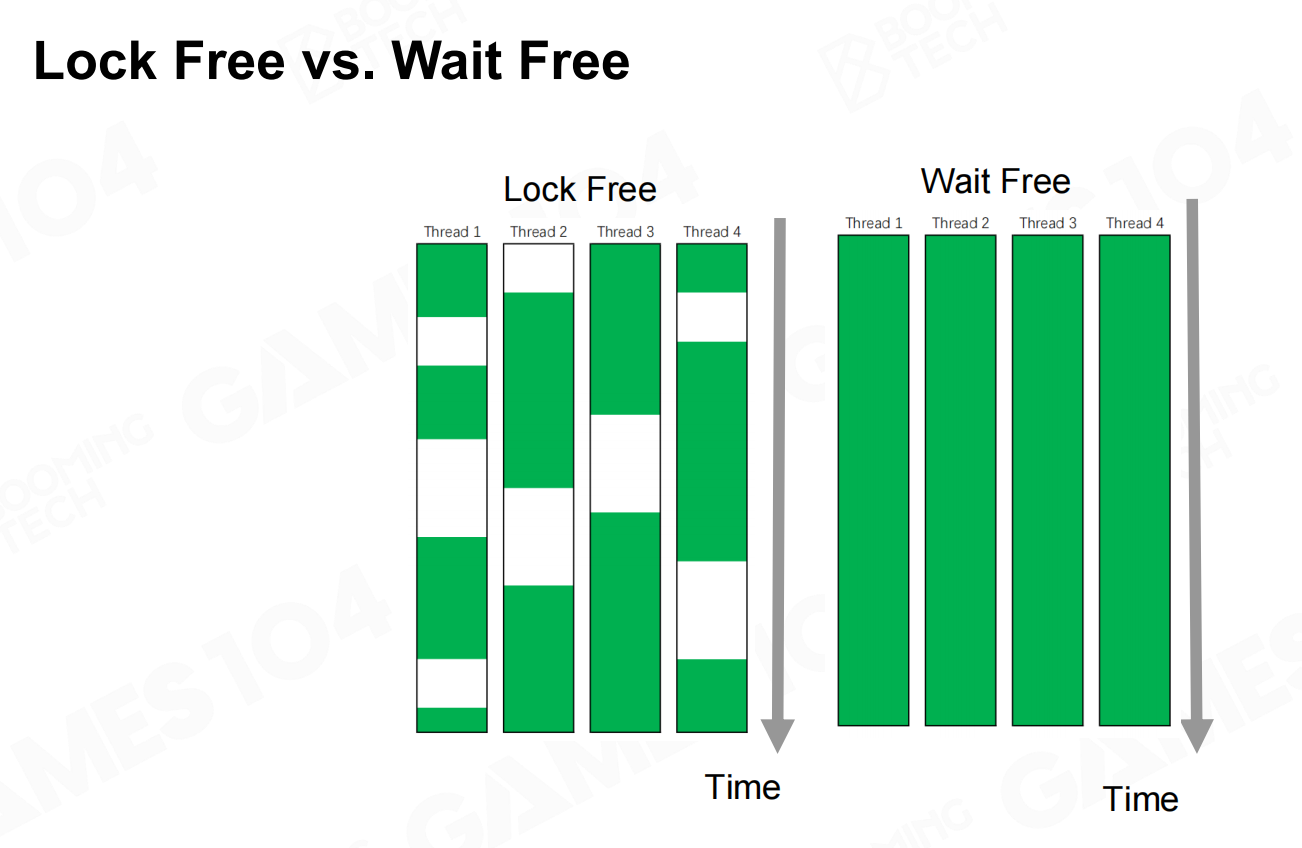 锁定空闲与等待空闲
锁定空闲与等待空闲
更复杂的重新排序优化(Complier Reordering Optimizations)
另一方面需要注意的是现代编译器对于高级语言是可以进行自动优化的。通过调整代码的执行顺序可以提升单线程程序的运行效率,但对于多线程的情况这种调整则可能会导致一些问题。 编译器重新排序优化
编译器重新排序优化 内存重排序问题
内存重排序问题
实际上很多的现代芯片出于种种方面的考虑都无法保证多线程情况下编译后代码的执行顺序。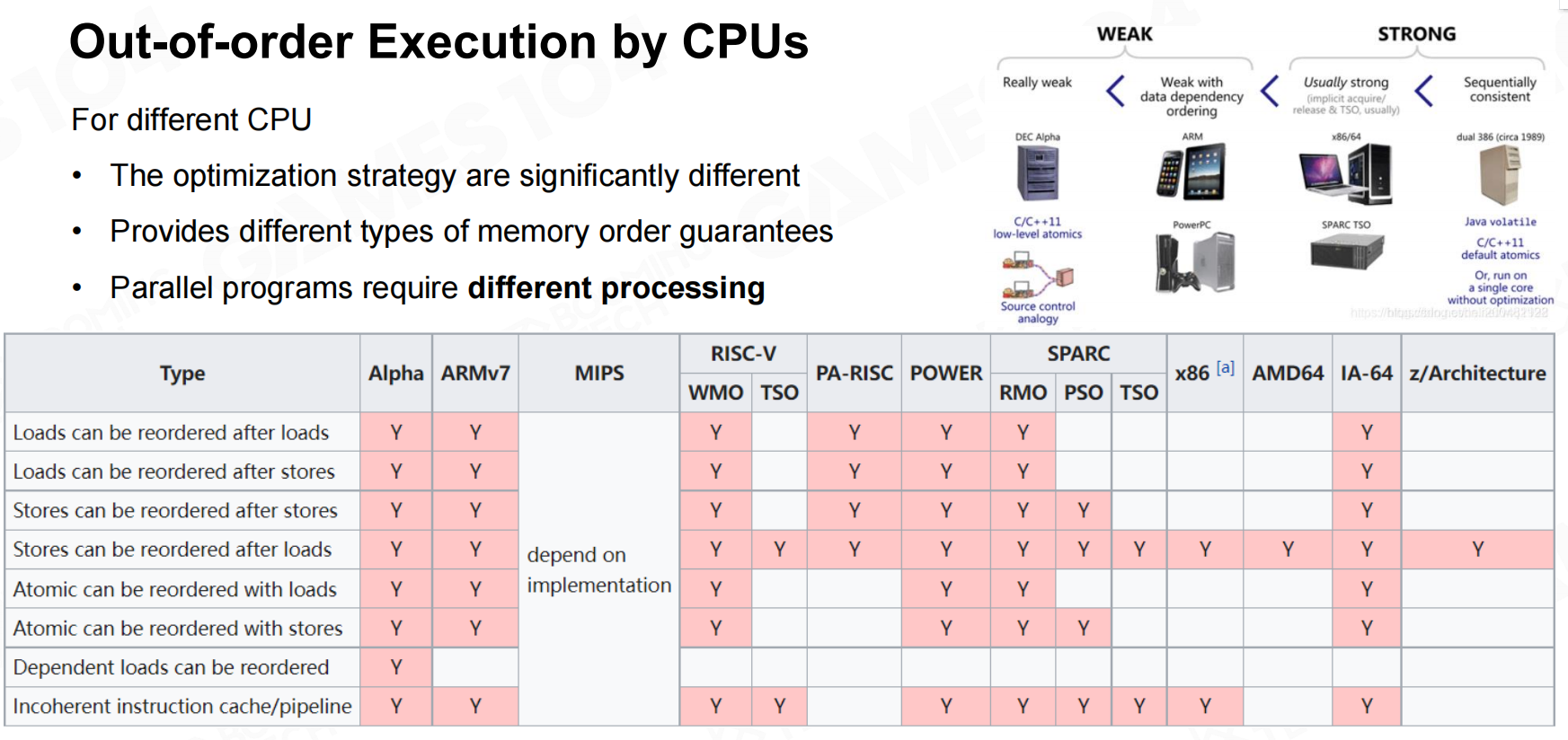 cpu的无序执行
cpu的无序执行
游戏引擎并行架构(Parallel Framework of Game Engine)
固定多线程(Fixed Multi-Thread)
游戏引擎在使用多线程时最经典的架构是fixed multi-thread,此时引擎中的每个系统都各自拥有一个线程。在每一帧开始时会通过线程间的通信来交换数据,然后各自执行自己的任务。 固定多线程
固定多线程
fixed multi-thread的一个缺陷在于它很难保证不同线程上负载是一致的。实际上不同线程之间负载的差异往往非常巨大,很多时候一些线程已经完成了自己的任务却必须要等待其它线程结束。这就造成了计算资源的浪费。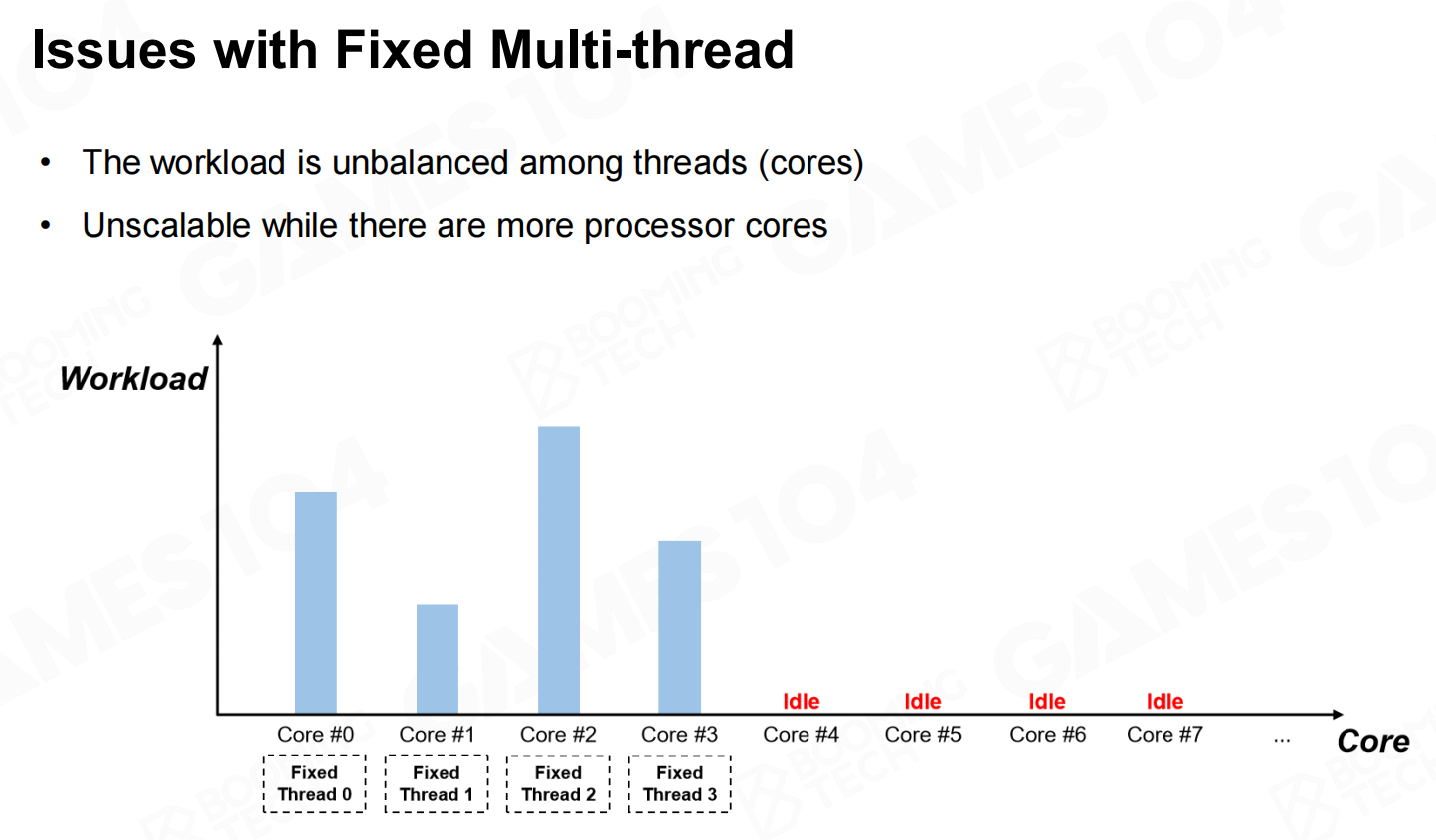 固定多线程的问题
固定多线程的问题
线程分叉连接(Thread Fork-Join)
另一种并行处理的方式是fork-join。对于某些负载比较高的系统我们可以实现申请一系列线程,当需要执行计算时通过fork操作把不同的计算任务分配到各个线程中并最后汇总到一起。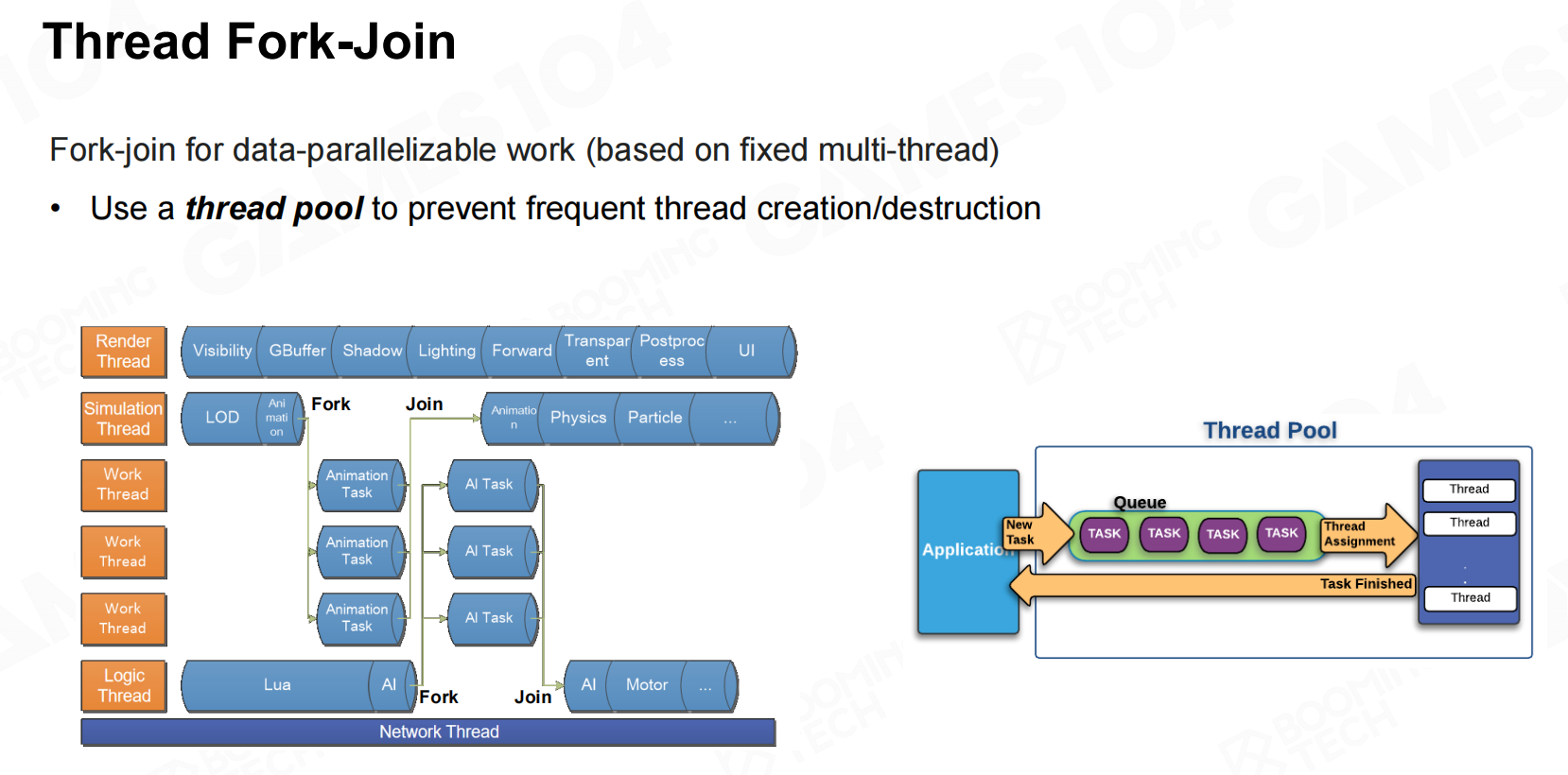 线程分叉连接
线程分叉连接
fork-join的缺陷在于有很多的任务是无法事先预测具体的负载的。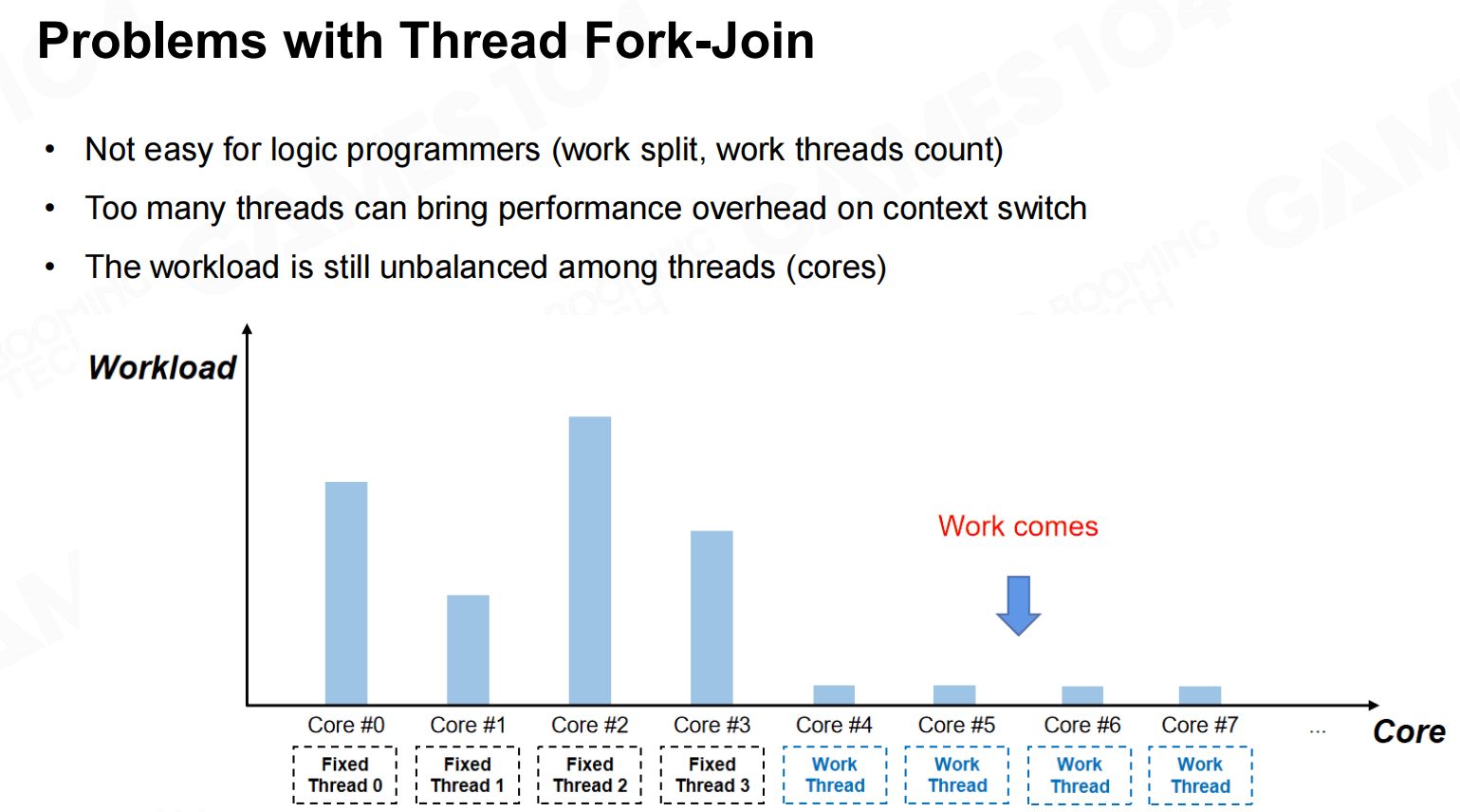 线程分叉连接的问题
线程分叉连接的问题
在虚幻引擎中设计了name thread和worker thread两种类型的线程。其中name thread对应引擎中的不同系统,而worker thread则是系统中具体计算任务的线程。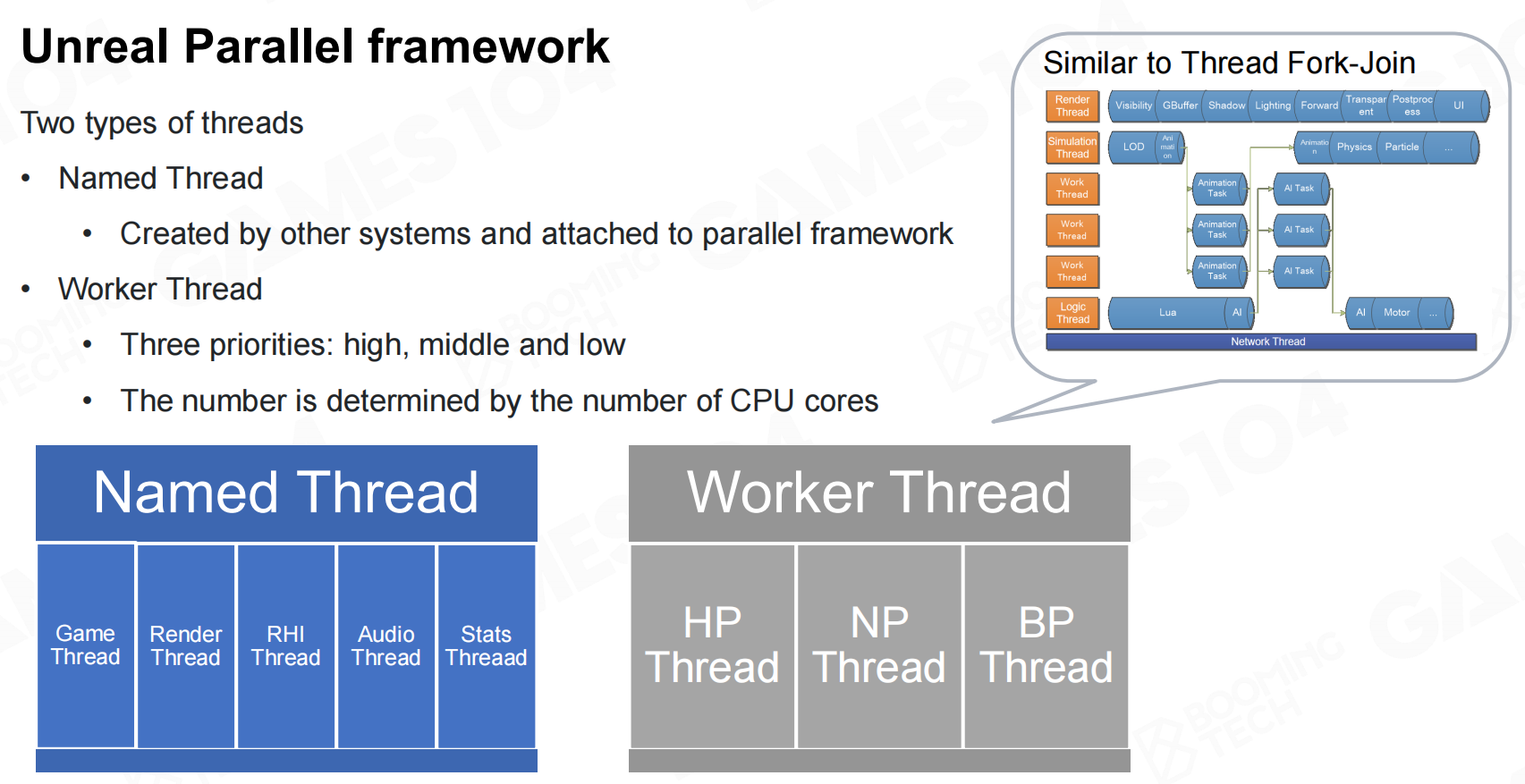 虚幻并行框架
虚幻并行框架
任务图(Task Graph)
除此之外还可以使用task graph来处理多线程,task graph会根据不同任务之间的依赖性来决定具体的执行顺序以及需要进行并行的任务。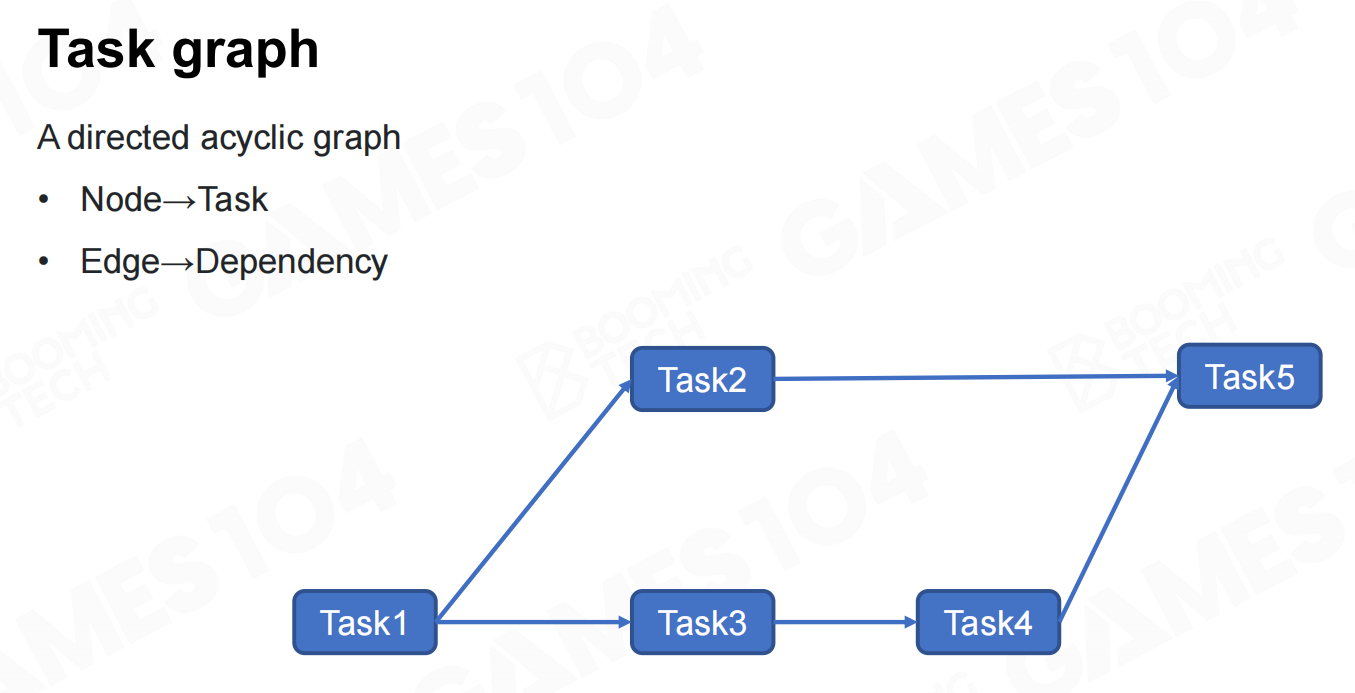 任务图
任务图 按链接构建任务图
按链接构建任务图
任务系统(Job System)
协程(Coroutine)
协程(coroutine)是一种轻量的线程上下文切换机制,它允许函数在执行过程中临时切换到协程上然后再切换回来。和线程相比,协程无需硬件层面上的数据切换,可以由程序自己进行定义,也不需要进入系统内核执行interruption。因此协程要比线程切换高效的多。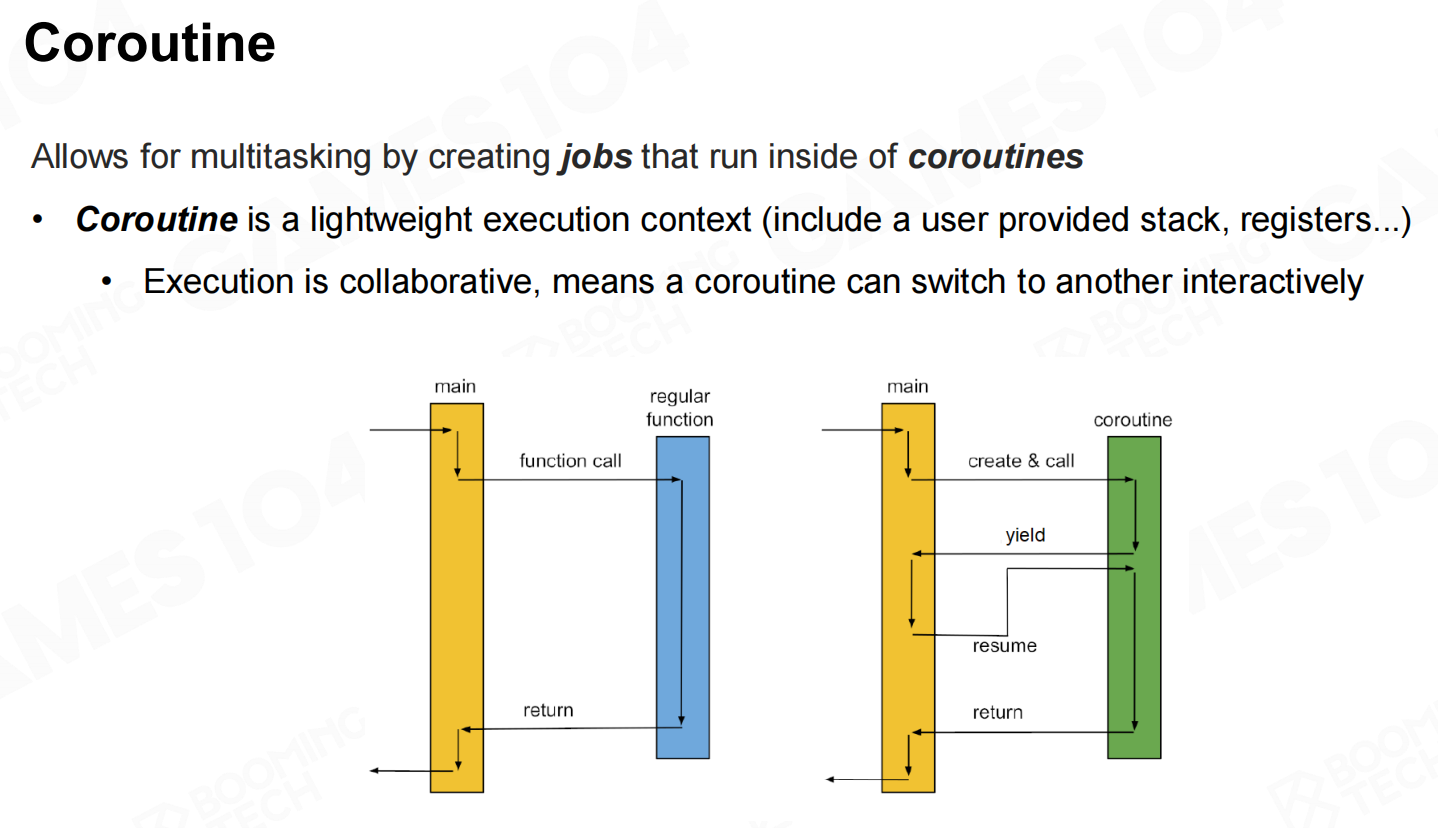 协程
协程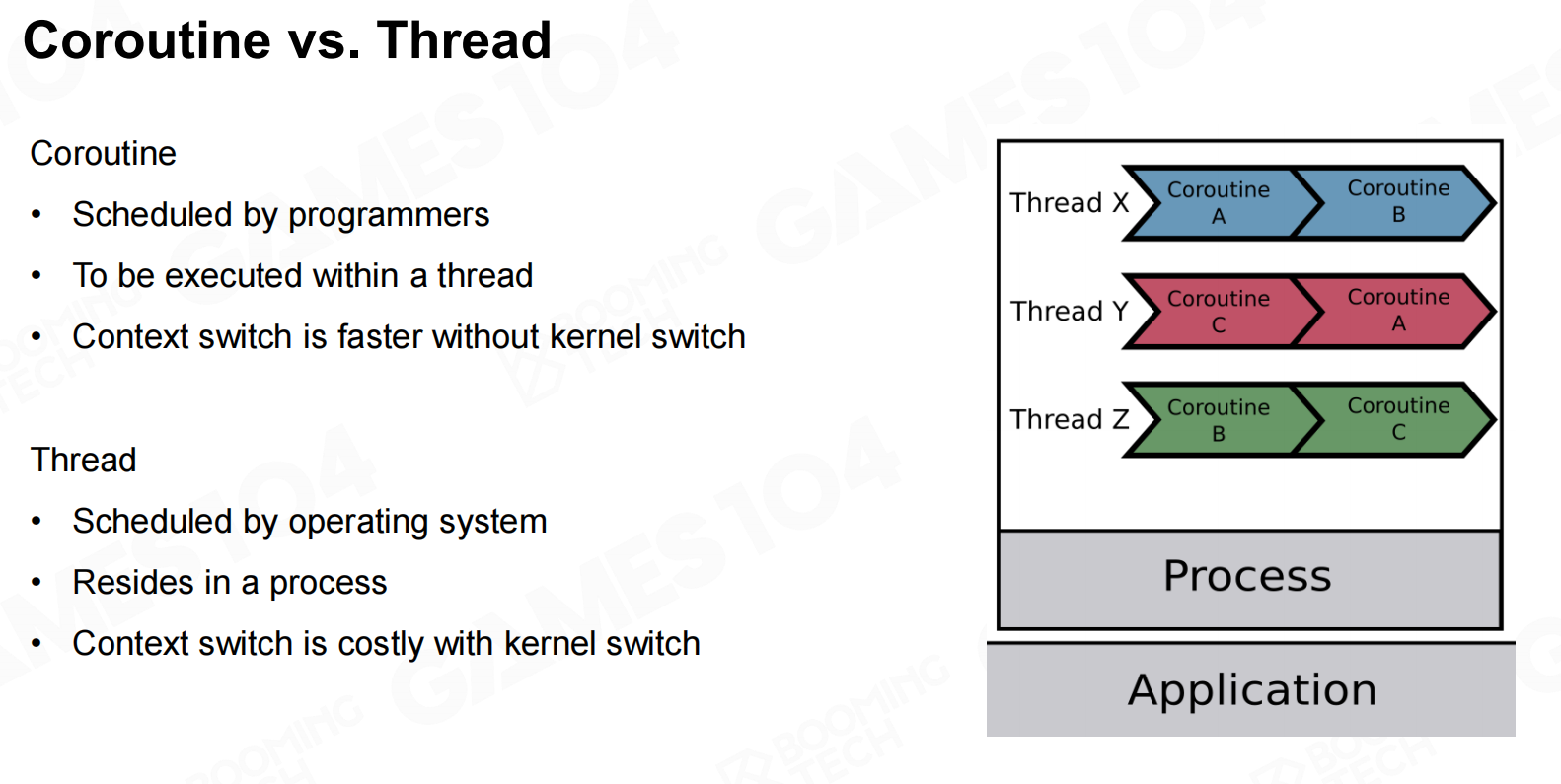 协程VS线程
协程VS线程
堆叠协程(Stackful Coroutine)
协程有两种实现方式。首先是使用栈来保存函数切换时的状态,当协程切换回来后根据栈上的数据来恢复之前的状态。 堆栈协程
堆栈协程
无堆叠协程(Stackless Coroutine)
另一种实现方式是不保存函数切换时的状态,当协程切换回来后按照当前的状态继续执行程序。 无堆叠协程
无堆叠协程
在实践中一般推荐使用基于栈来实现的协程。尽管它在进行切换时的开销要稍微多一些,但可以避免状态改变导致的各种问题。 堆栈协程VS无堆叠协程
堆栈协程VS无堆叠协程
基于管线的任务系统(Fiber-Based Job System)
基于协程的思想可以实现fiber-based job system。在这种任务系统中job会通过fiber来进行执行,在线程进行计算时通过fiber的切换来减少线程调度的开销。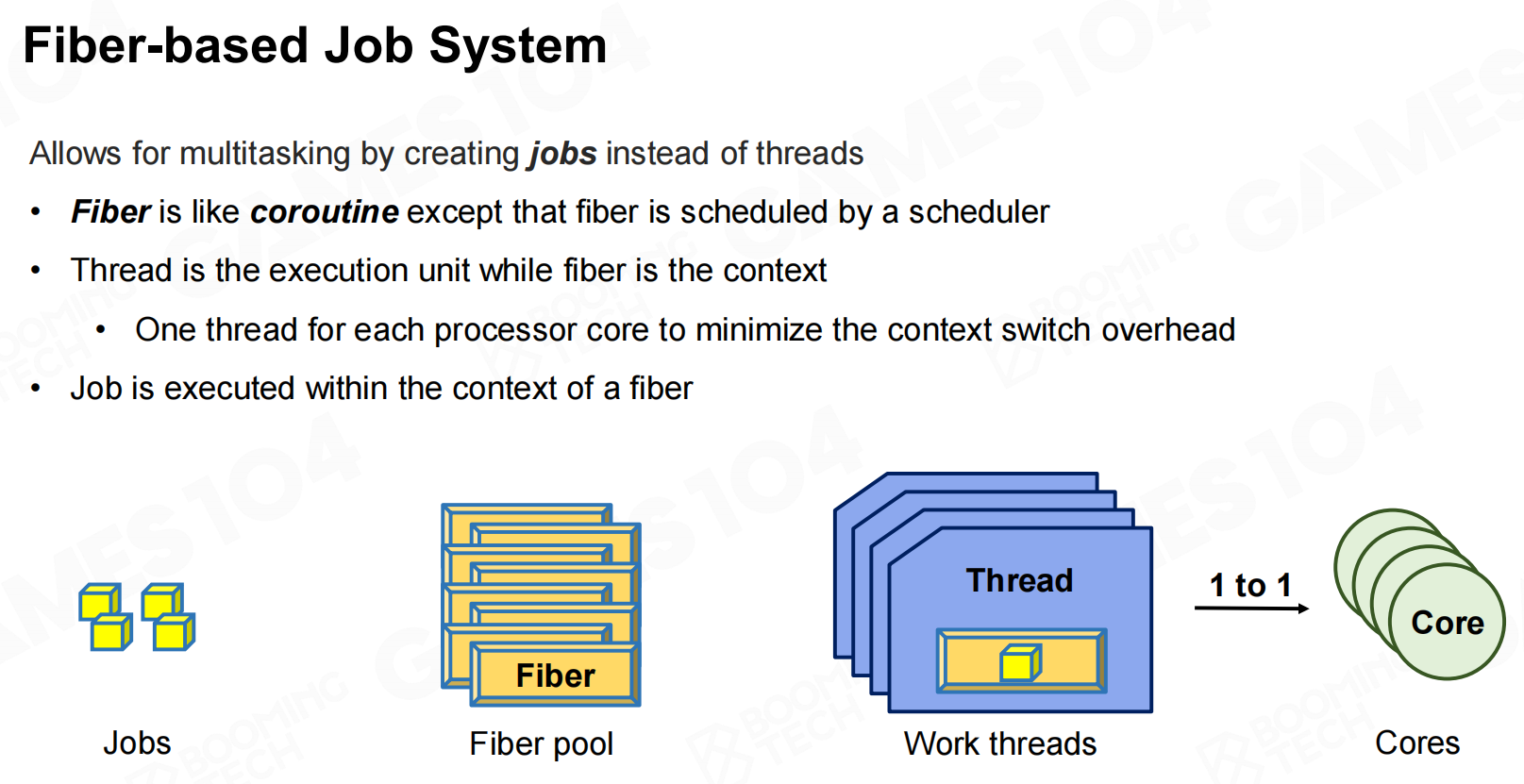 基于管线的任务系统
基于管线的任务系统
对于多核的情况我们希望尽可能保证一个线程对应一个核(包括逻辑核),这样可以进一步减少线程切换带来的额外开销。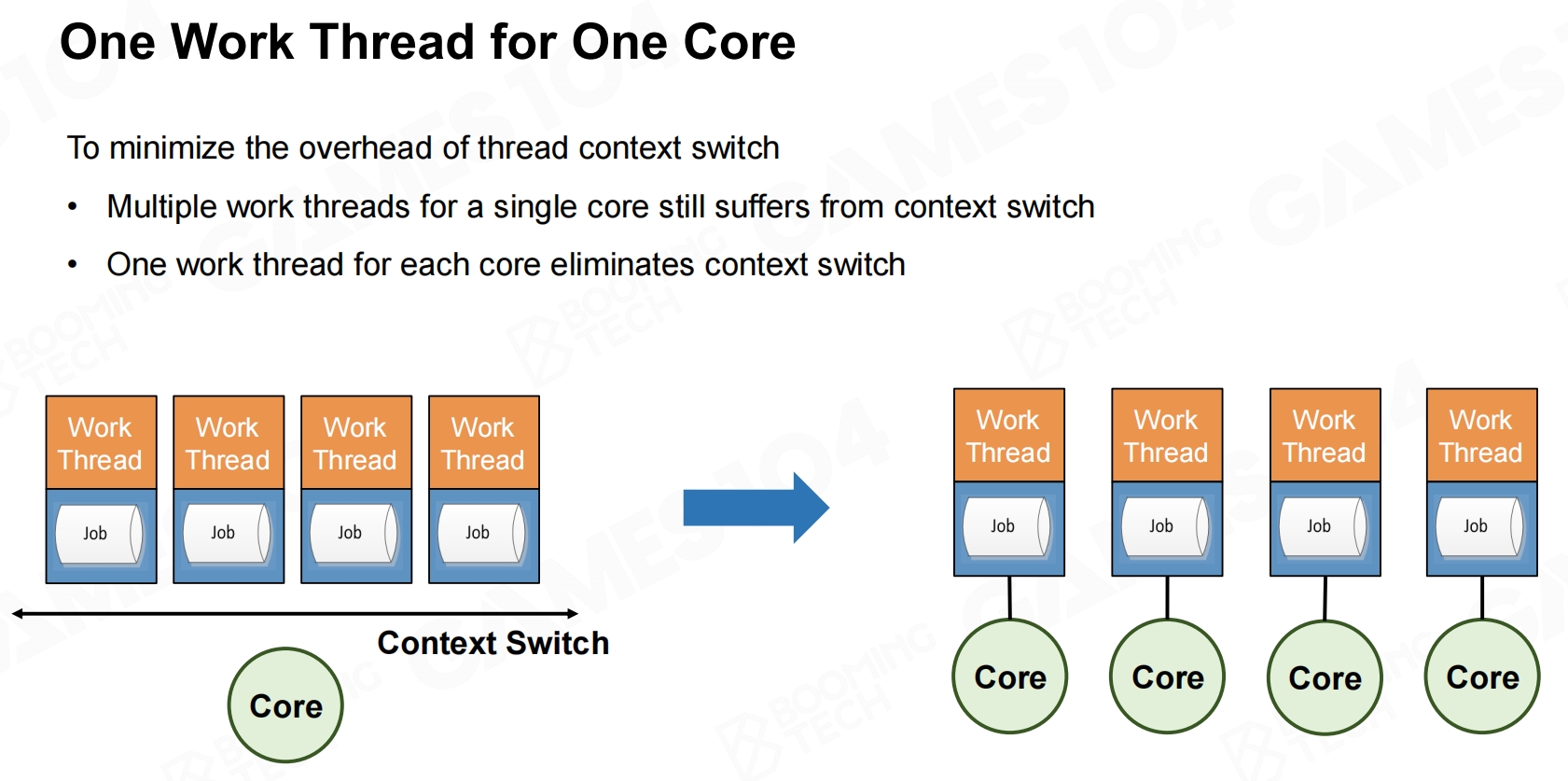 为一个核心的一个工作线程
为一个核心的一个工作线程
在执行计算时根据程序的需要生成大量的job,然后调度器根据线程负载分配到合适的线程以及线程上的fiber中。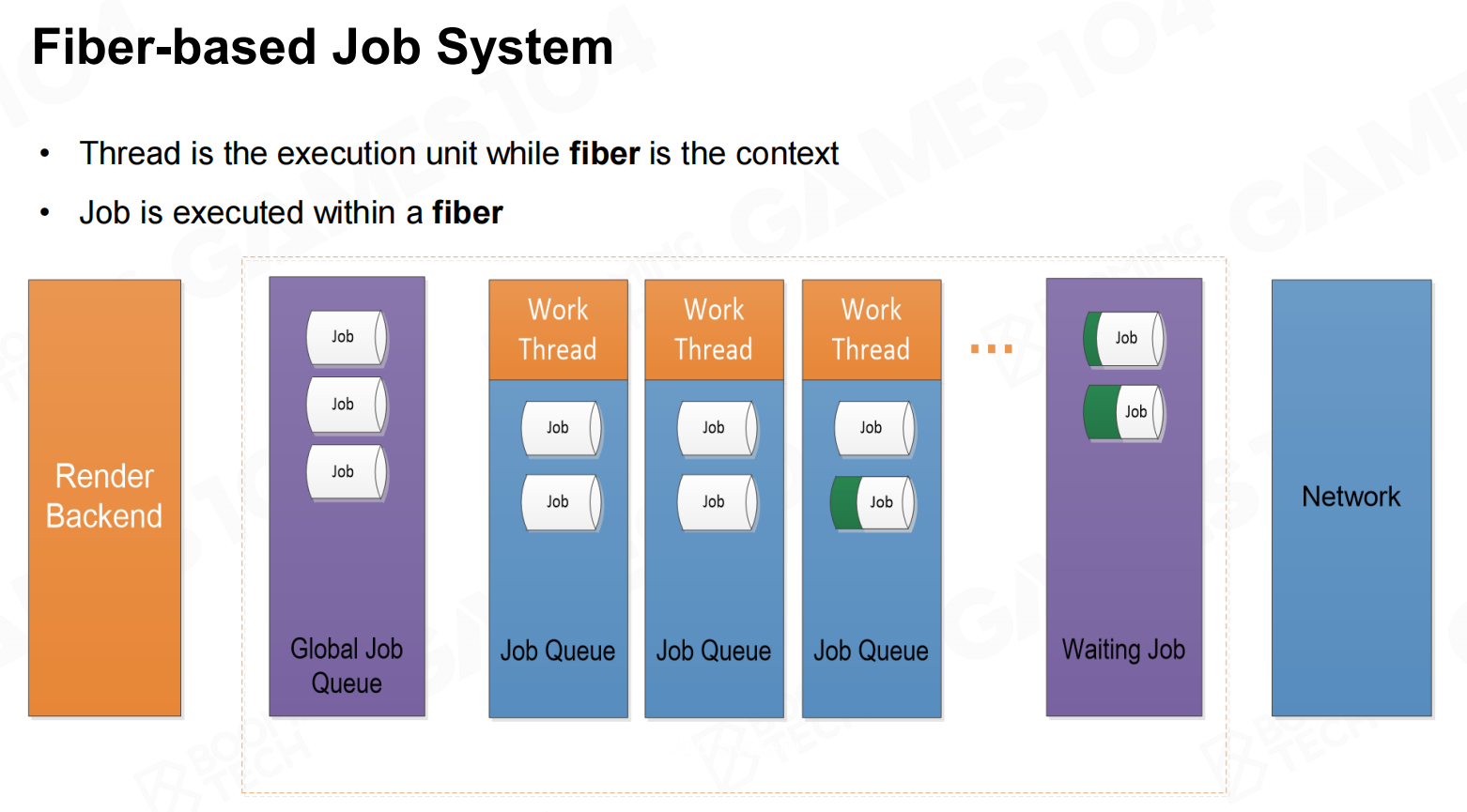 基于管线的任务系统2
基于管线的任务系统2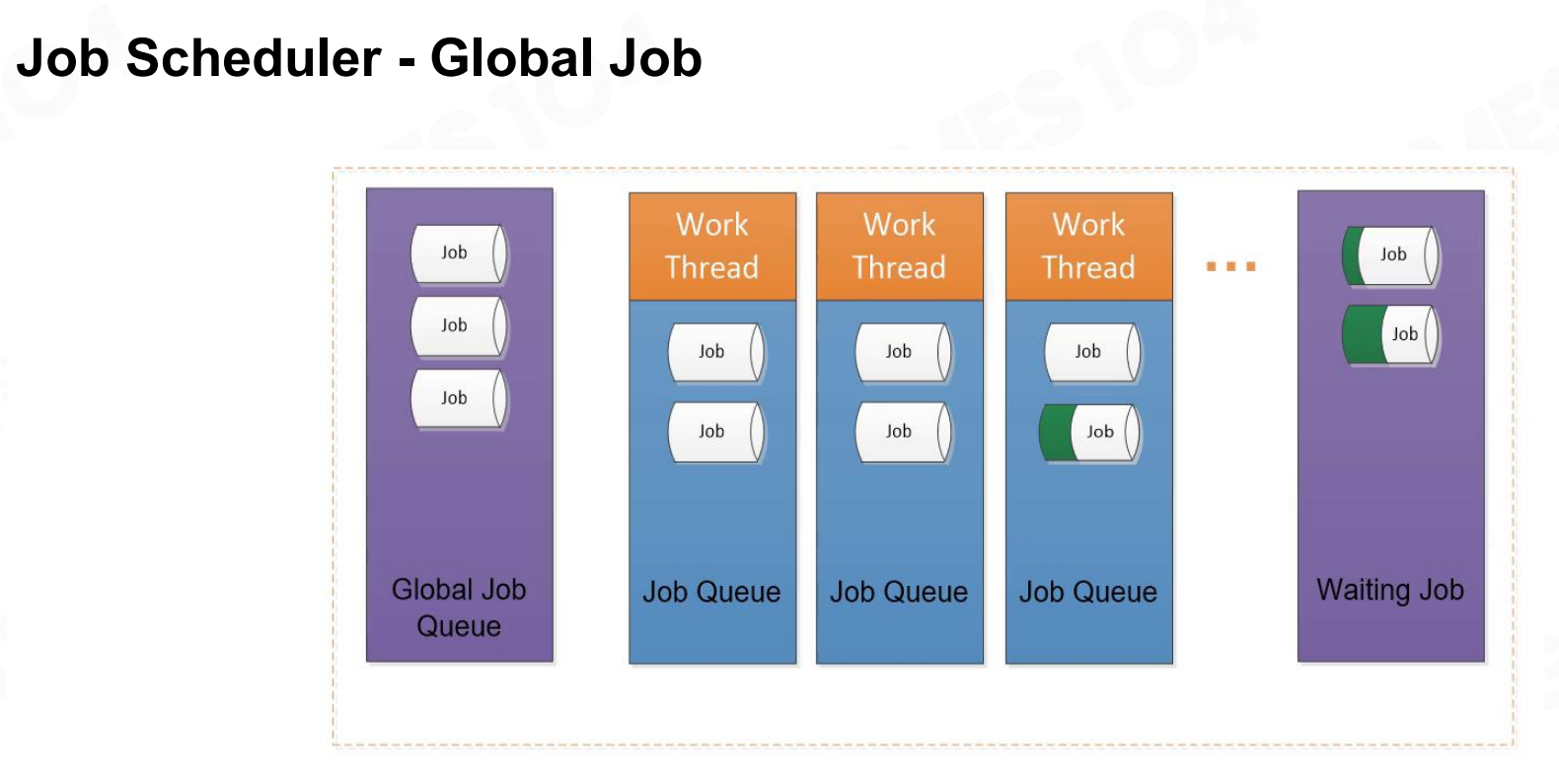 任务调度程序-全局任务
任务调度程序-全局任务
在执行job时根据计算顺序可以分为FIFO以及LIFO两种模式,在实践工程中一般会选择LIF。 先进先出和先进后出模式
先进先出和先进后出模式
当job出现依赖时会把当前的job移动到等待区然后执行线程中的下一个job。这样的方式可以减少CPU的等待,提高程序效率。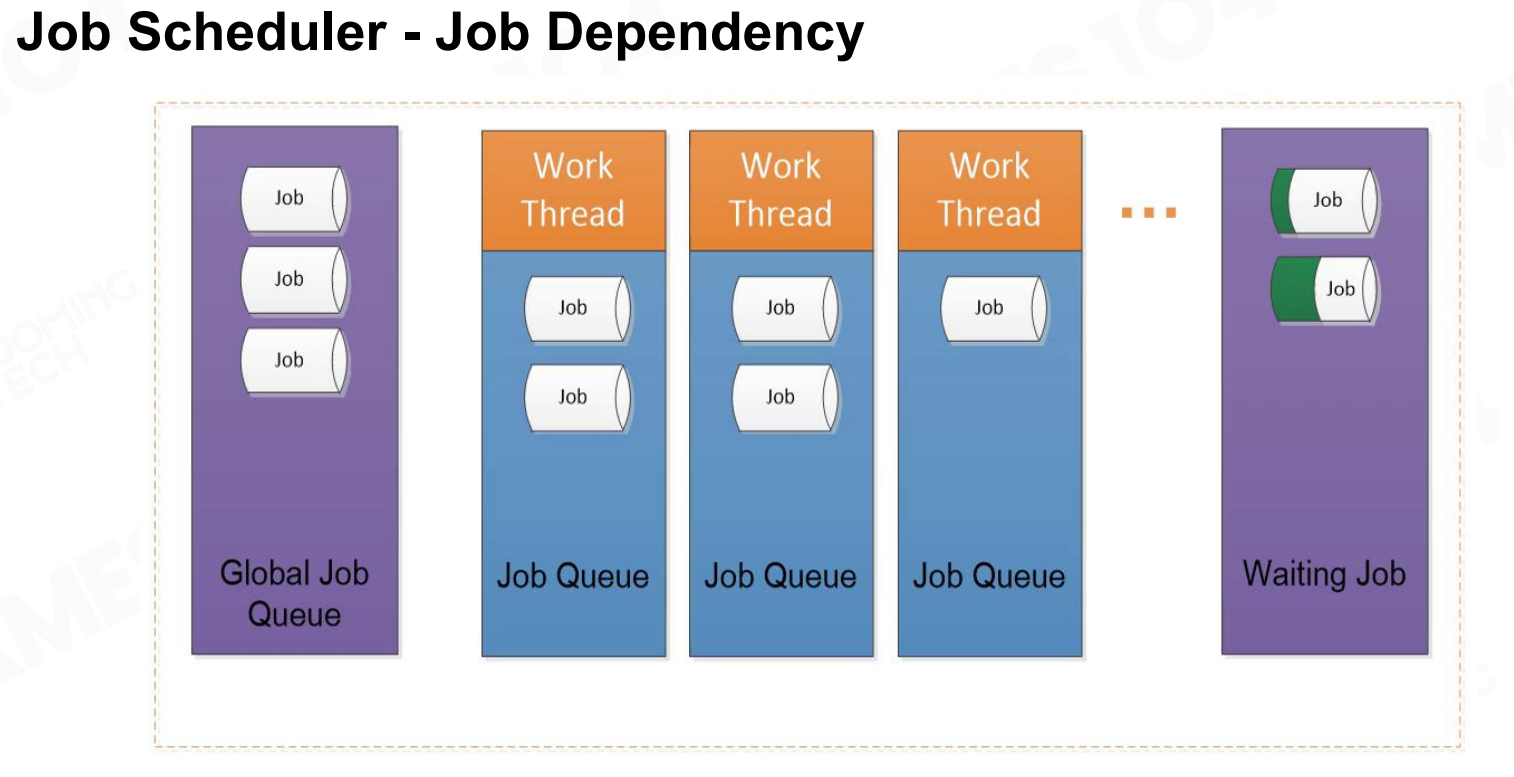 任务调度程序-任务依赖性
任务调度程序-任务依赖性
如果出现了线程闲置的情况,调度器会把其他线程中的job移动到闲置线程中进行计算。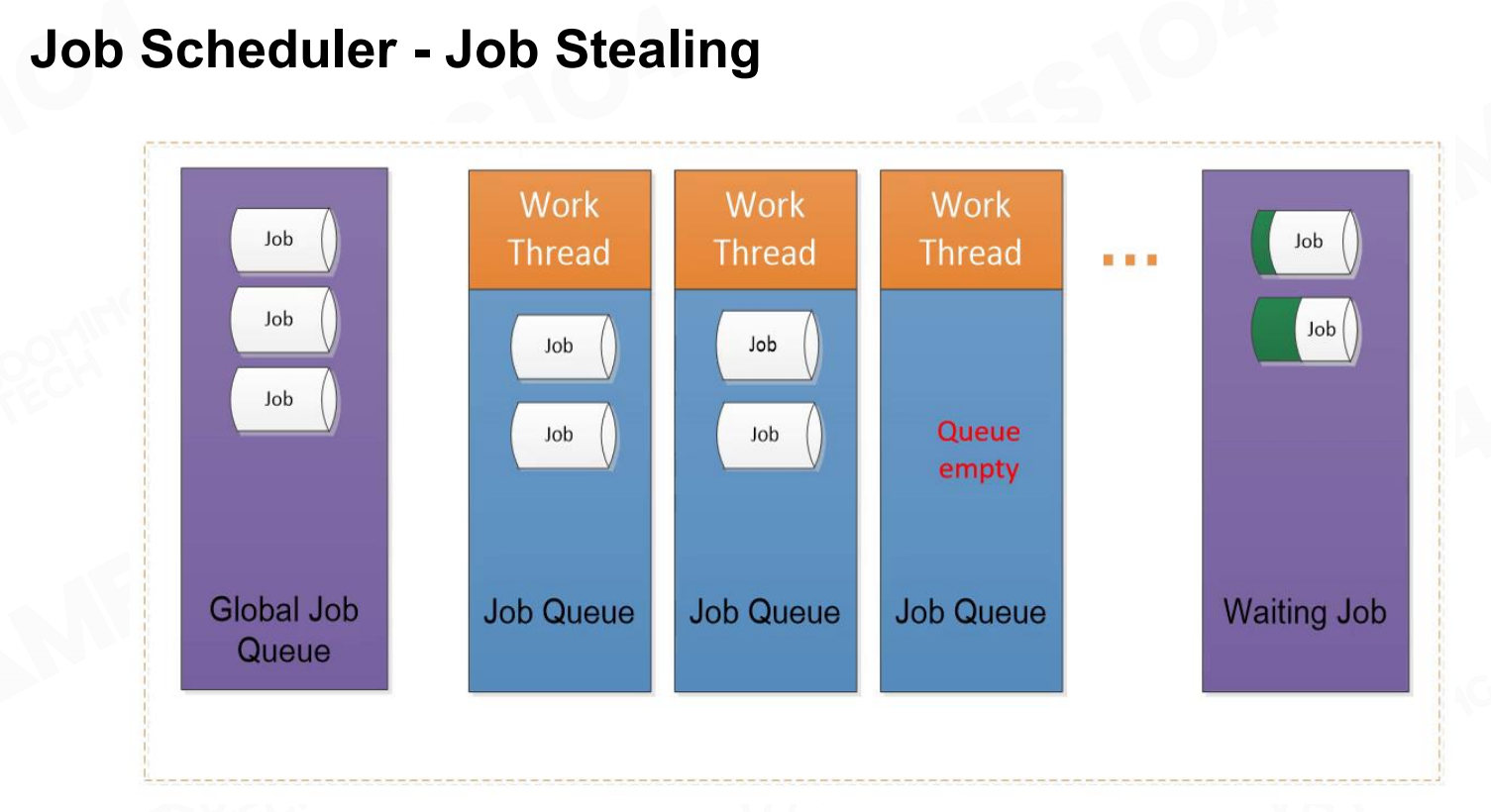 任务调度程序-任务拉取
任务调度程序-任务拉取
和上面介绍过的多线程方法相比,任务系统可以更好地利用多核并且避免线程切换从而提升计算性能。不过目前原生C++暂不支持协程,而且在不同的操作系统中任务系统的实现往往是不同的。 任务系统的利与弊
任务系统的利与弊
编程规范(Programming Paradigms)
除了硬件之外,编程范式(programming paradigms)对于程序的性能也会有一定的影响。在游戏引擎中我们会使用各种类型的编程范式来实现各种各样的功能。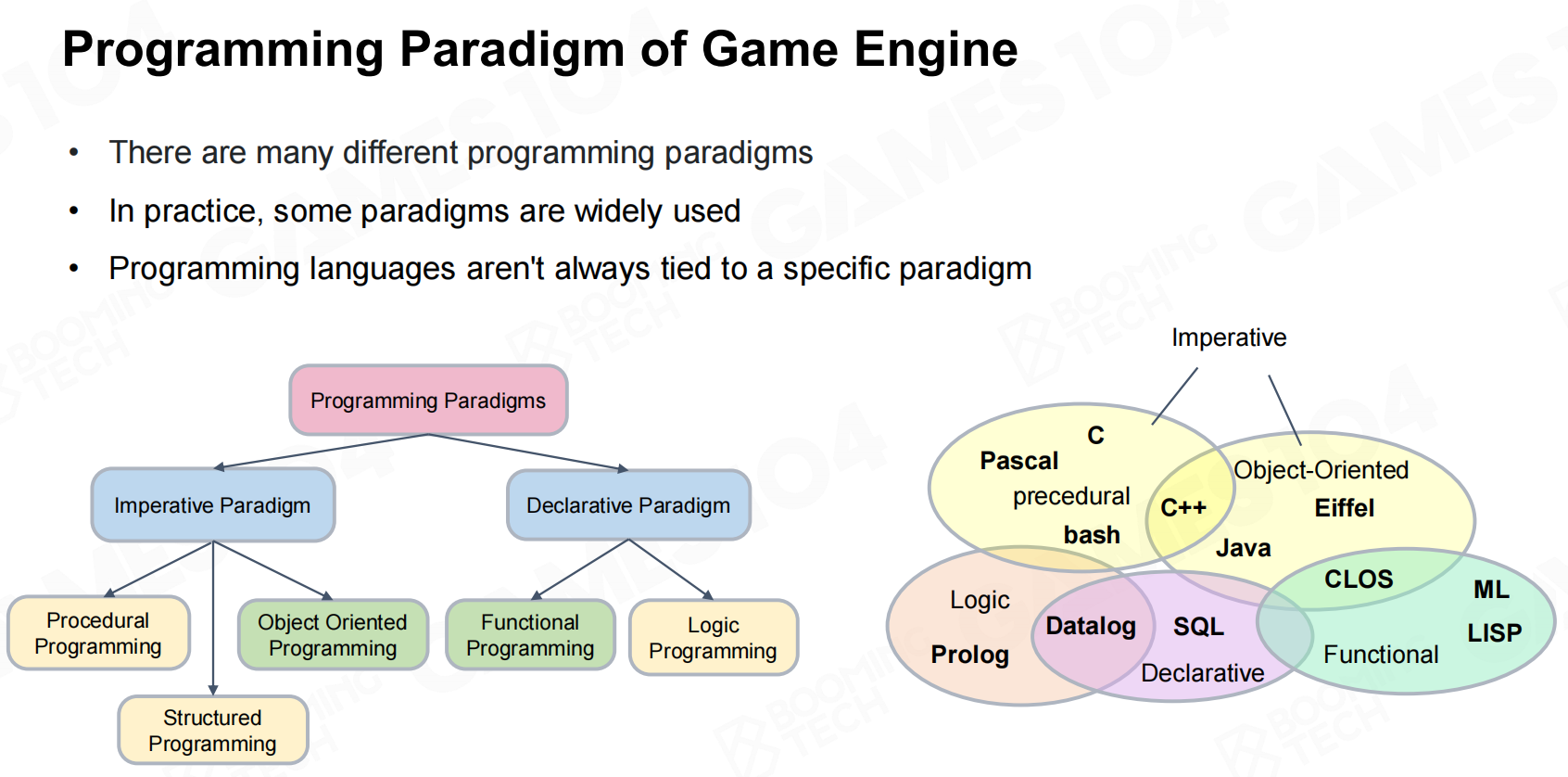 游戏引擎的编程规范
游戏引擎的编程规范
面向过程的程序设计(Procedural-Oriented Programming - POP)
早期的游戏一般是使用面向过程编程(procedural-oriented programming, POP)来实现的。 面向过程的程序设计
面向过程的程序设计
面向对象编程(Object-Oriented Programming - OOP)
随着游戏系统变得不断复杂,面向对象编程(object-oriented programming, OOP)的思想在现代游戏引擎中起着越来越重要的作用。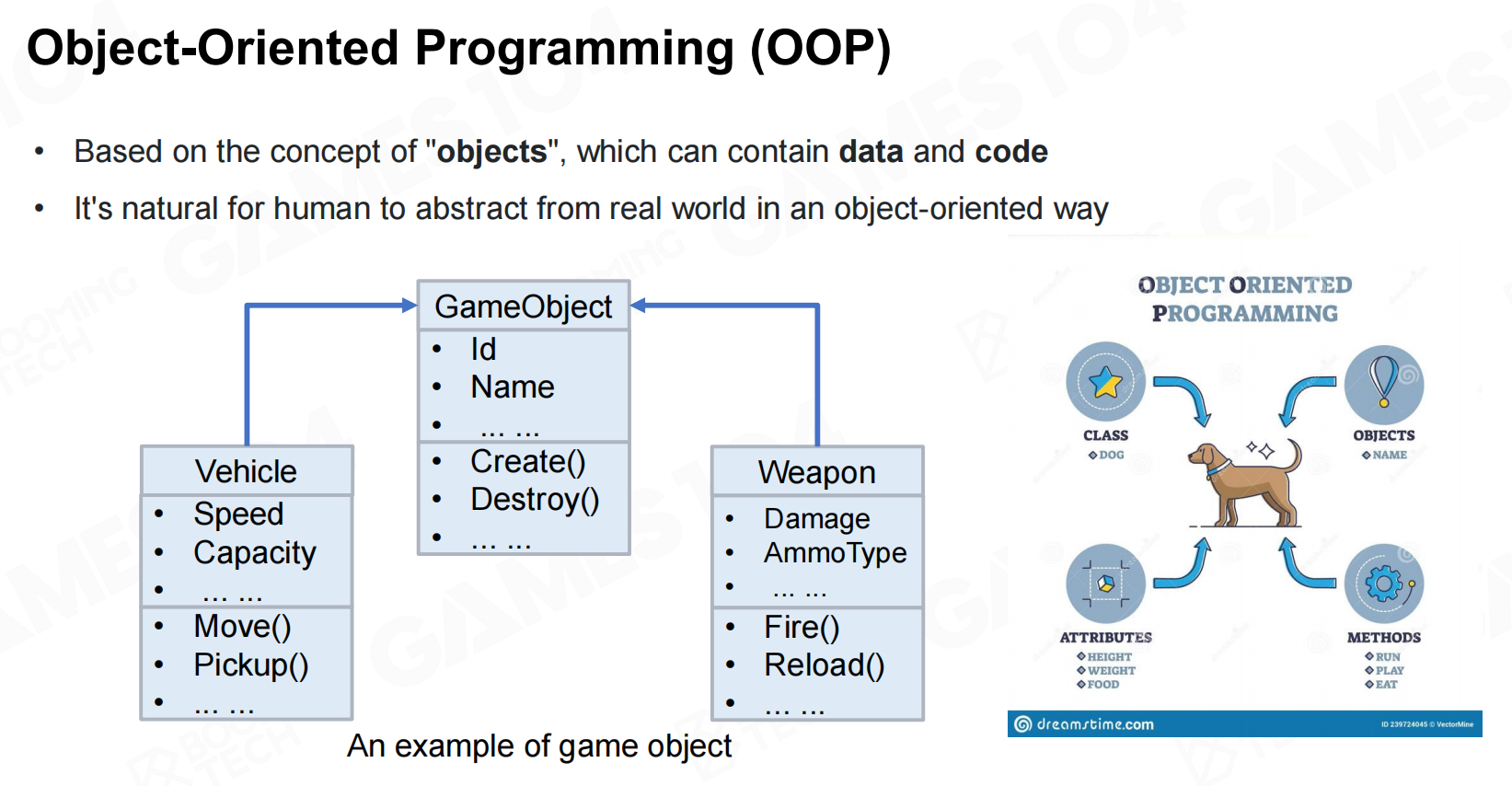 面向对象编程
面向对象编程
OOP的问题(Problems of OOP)
然而在大量的实践中人们发现OOP也不是完美的,一个最常见的问题是OOP存在二义性:角色的攻击行为既可以写在角色身上,也可以写在被攻击者身上。 OOP的问题:将代码放在哪里?
OOP的问题:将代码放在哪里?
同时OOP中存在大量的继承关系,有时很难去查询对象的方法具体是在那个类中实现的。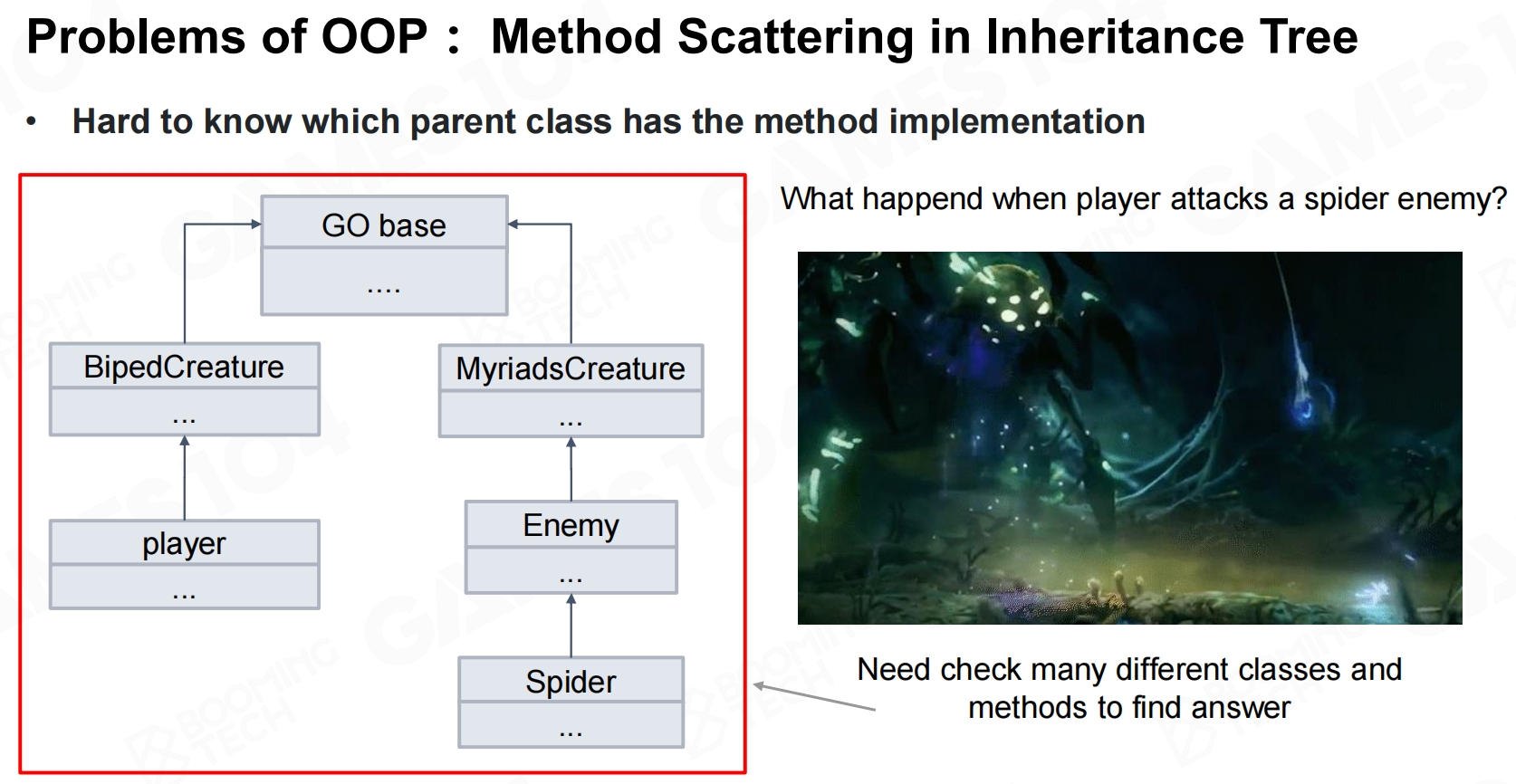 OOP的问题:继承树中的方法散射
OOP的问题:继承树中的方法散射
另外OOP中的基类往往需要提供非常多的功能,对于很多派生子类来说这样的基类实在过于臃肿了。 OOP的问题:混乱的的继承类
OOP的问题:混乱的的继承类
OOP最大的问题在于它的性能可能是很低的。尽管OOP很符合人的认识,但对象的数据往往分布在不同的内存区域上。这就导致程序运行时会浪费大量的时间来读取数据。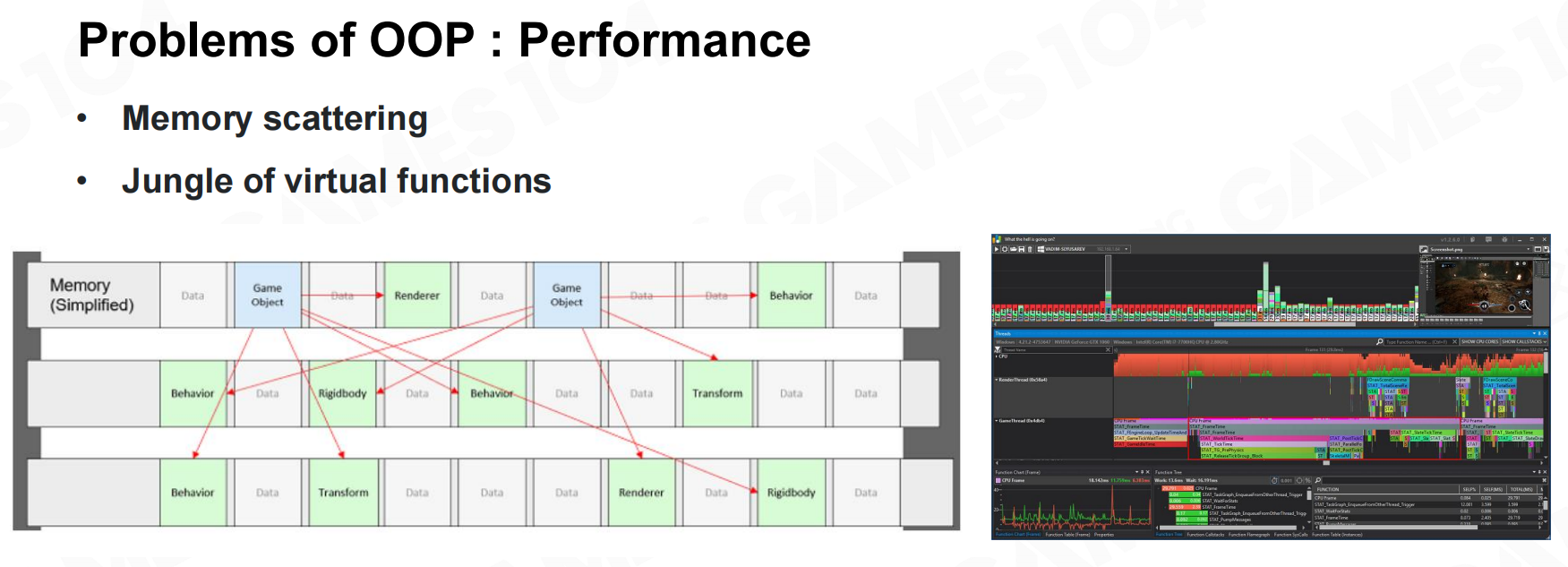 OOP的问题:性能
OOP的问题:性能
最后,OOP的可测试性非常差。当我们想要去测试对象的某个方法是否按照我们的期望运作时,往往需要从头创建出整个对象,这与单元测试的思想是相违背的。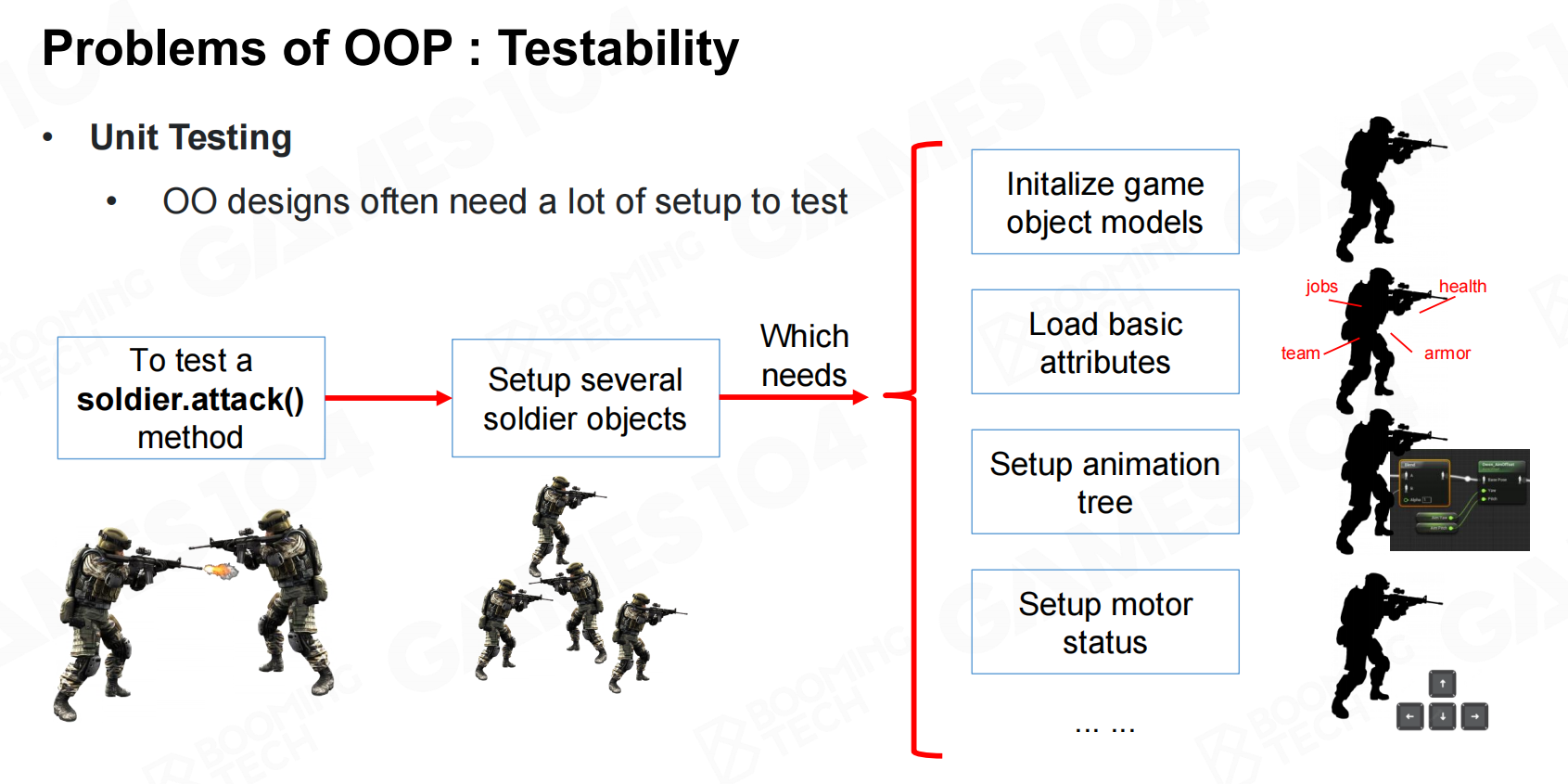 OOP的问题:可检验性
OOP的问题:可检验性
面向数据编程(Data-Oriented Programming - DOP)
面向数据编程(data-oriented programming, DOP)是现代游戏引擎中越来越流行的一种编程范式。现代计算机的发展趋势是CPU运行速度越来越快,但是相对地内存访问的速度却跟不上CPU计算的速度。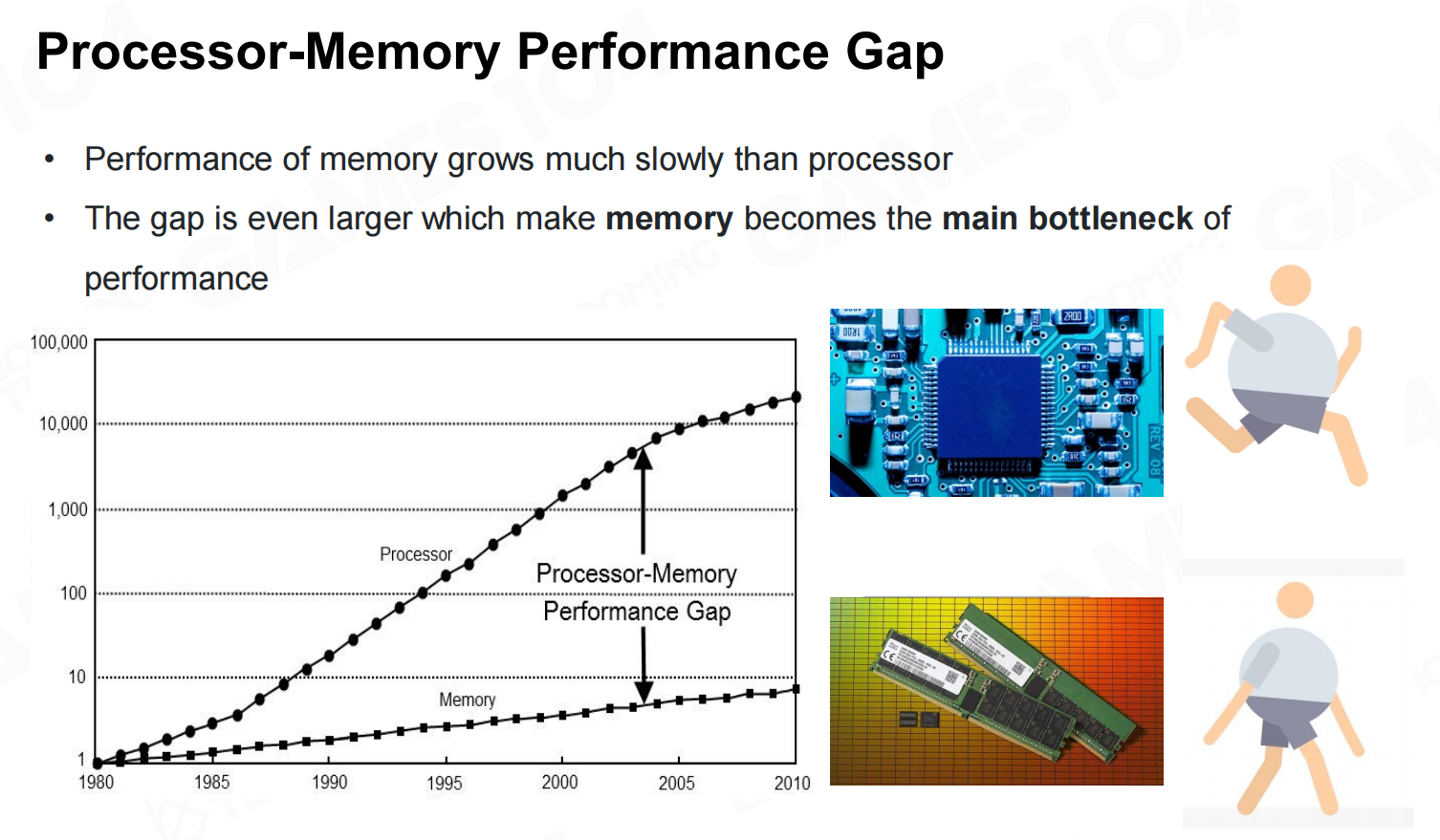 处理器内存性能差距
处理器内存性能差距
缓存(Cache)
为了解决的问题人们设计了缓存(cache)这样的机制来加快内存的访问。一般来说现代计算机都有多级缓存系统,越底层的缓存容量越小但访问速度越快。通过缓存机制我们可以把内存中的数据先放到缓存中来加快CPU的访问速度。 内存-高速缓存的演变
内存-高速缓存的演变
局部性原理(Principle of Locality)
利用缓存机制进行编程时就需要考虑数据的locality。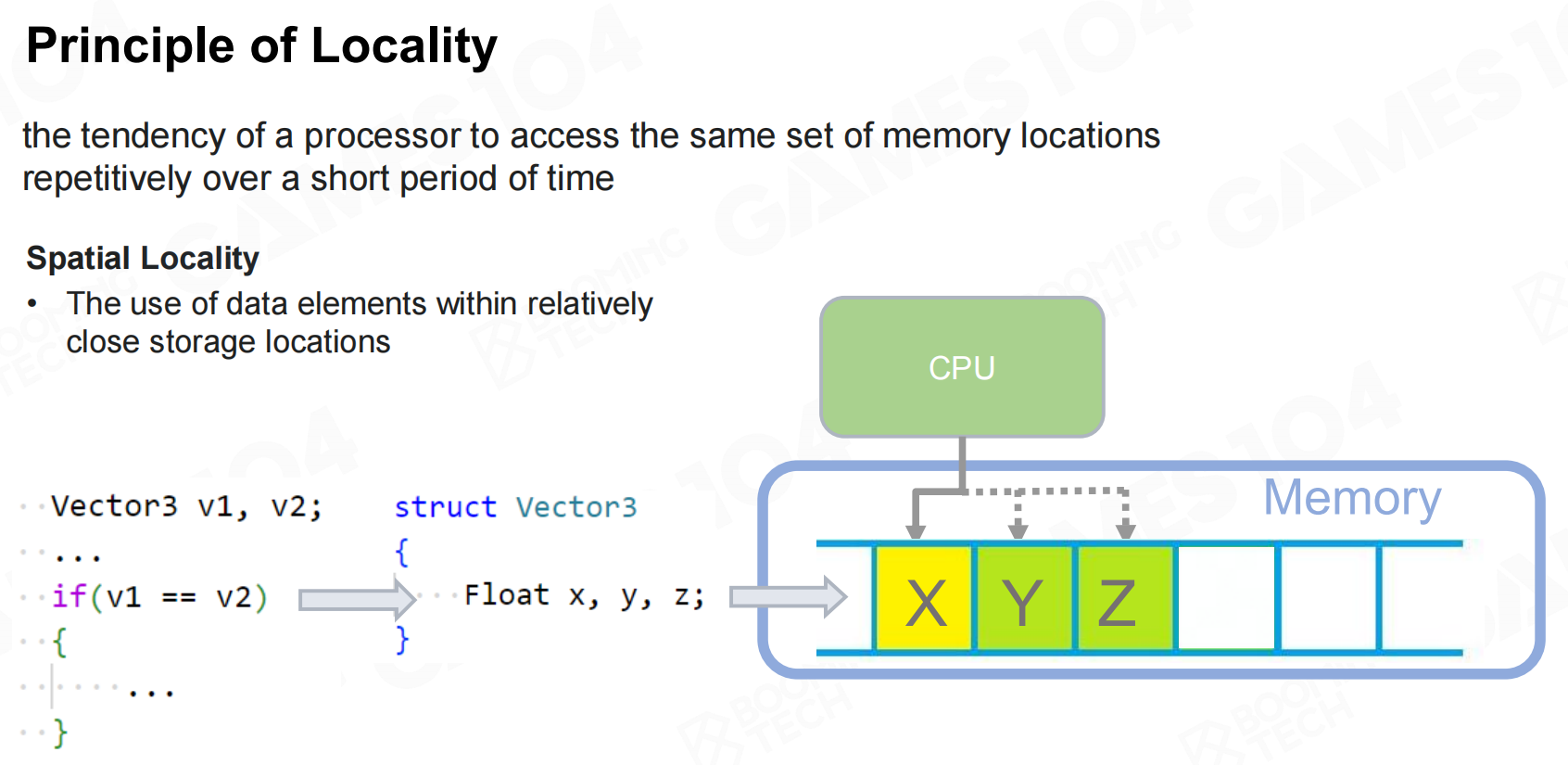 内存-高速缓存的演变
内存-高速缓存的演变
单指令多数据(Single Instruction Multiple Data - SIMD)
SIMD是利用缓存机制实现高性能编程的经典案例。现代CPU基本都实现了SIMD机制,这样可以在一个指令中同时处理4个操作。因此我们可以把数据尽可能组织成SIMD的格式来对程序进行加速。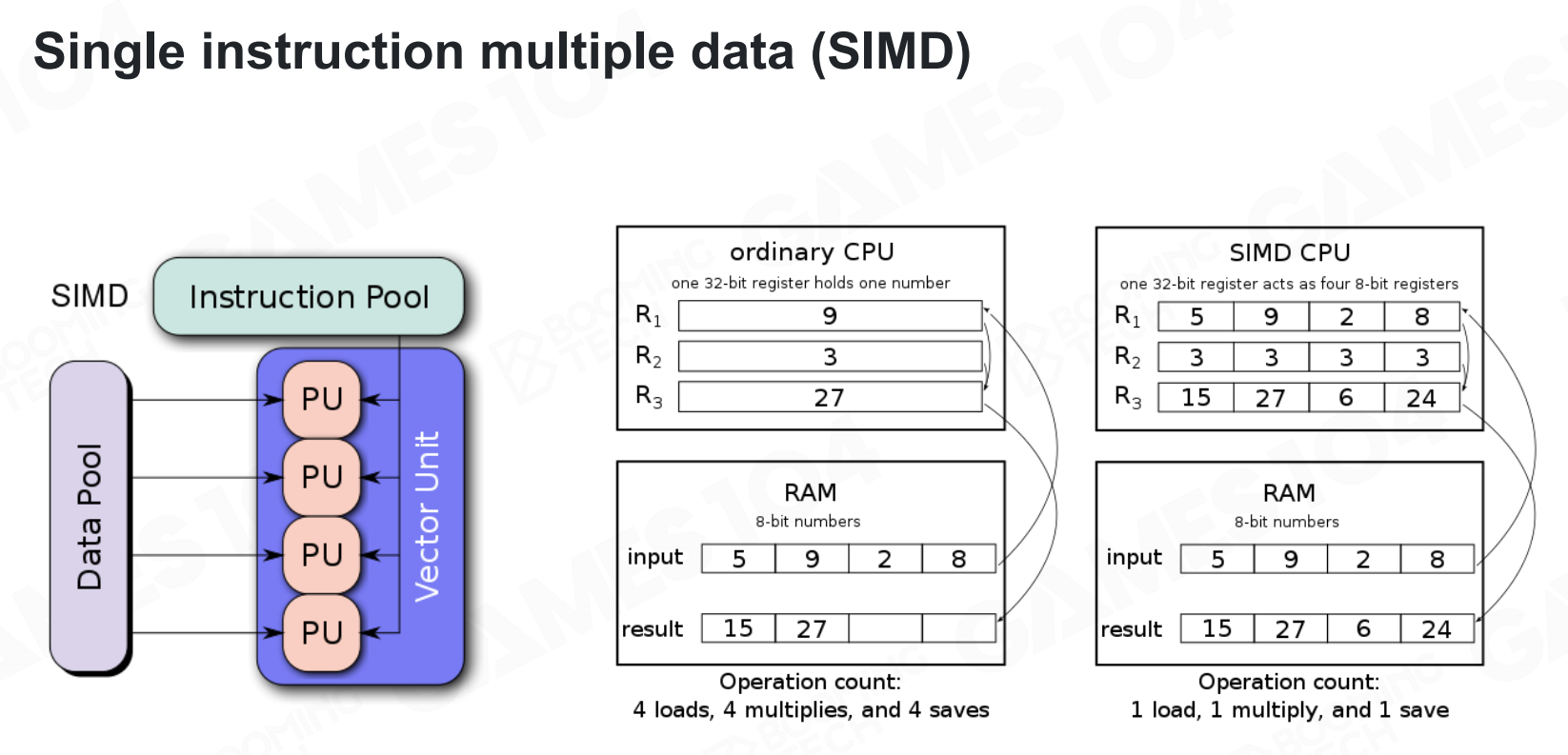 单指令多数据
单指令多数据
最近最少使用(Least Recently Used - LRU)
LRU同样是高性能编程中的常用的技巧。当缓存满了后系统会把最不常用的数据置换出去,只留下近期用过的数据从而提升缓存的利用率。在实践中也会采用随机丢弃数据的策略,可以证明这样的策略拥有更好的性能。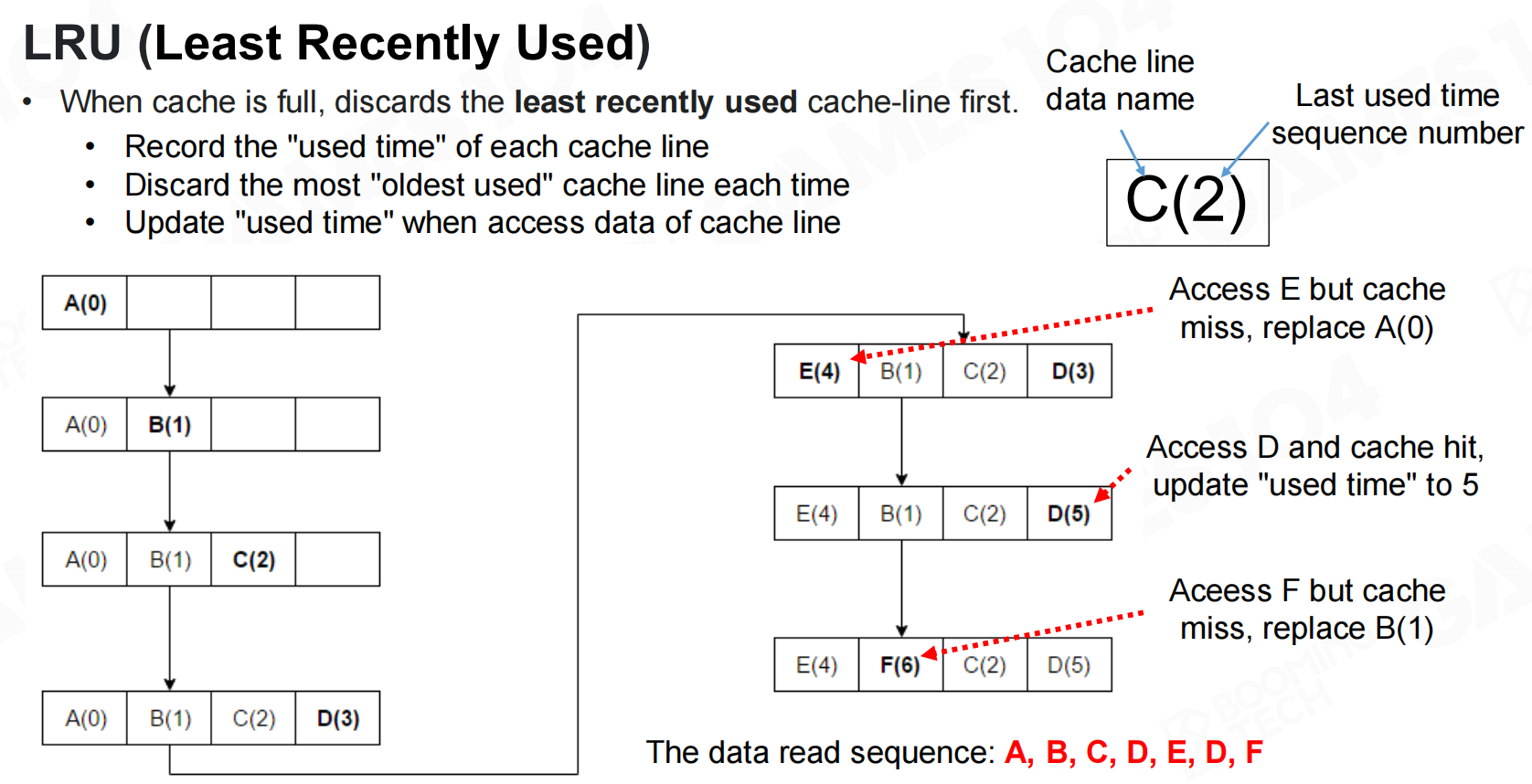 最近最少使用
最近最少使用
超高速缓冲存储器线(Cache Line)
当缓存中的数据进行读写时,不是对单个数据进行操作而是直接读写一条cache line上的全部数据(一般是64 byte)。实际上CPU的读写操作都是以cache line作为单位来执行的,因此需要操作系统来保证CPU读写缓存以及内存数据时的顺序和一致性。 超高速缓冲存储器线
超高速缓冲存储器线
因此我们在设计数据的存储形式时就可以利用cache line的机制来加速访问。以矩阵这种数据格式为例,按照行来进行存储的矩阵往往要比按照列来存储的有更高的读写效率。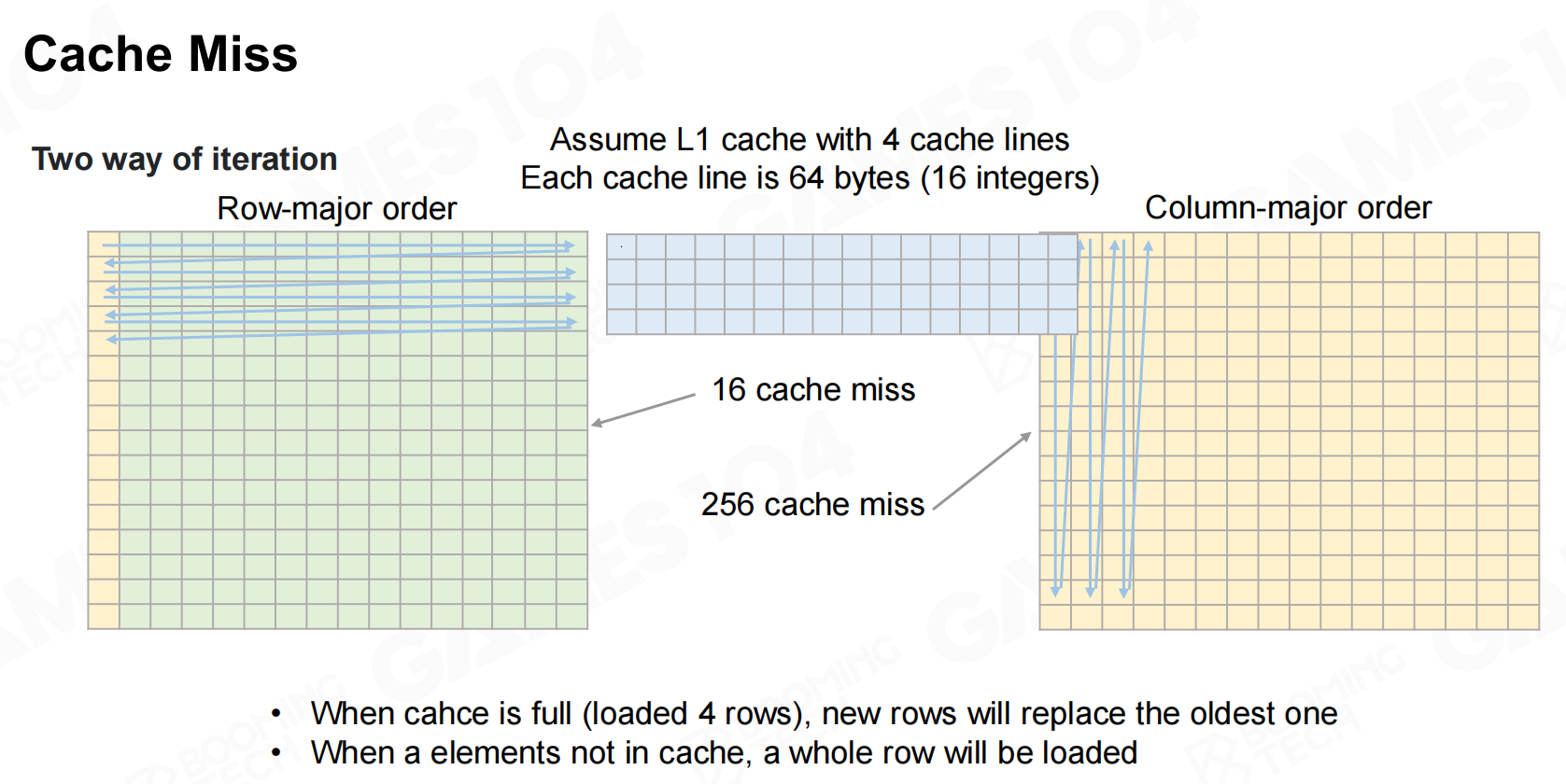 高速缓存未命中
高速缓存未命中
面向数据的程序设计(Data-Oriented Programming - DOP)
DOP的核心思想在于把游戏世界(包括代码)认为是数据的集合,在编写程序时要尽可能利用缓存同时避免cache miss。 面向数据的程序设计
面向数据的程序设计 指令也是数据
指令也是数据
因此在DOP中我们会把数据和代码看做一个整体,同时使它们在缓存中的分布尽可能地集中。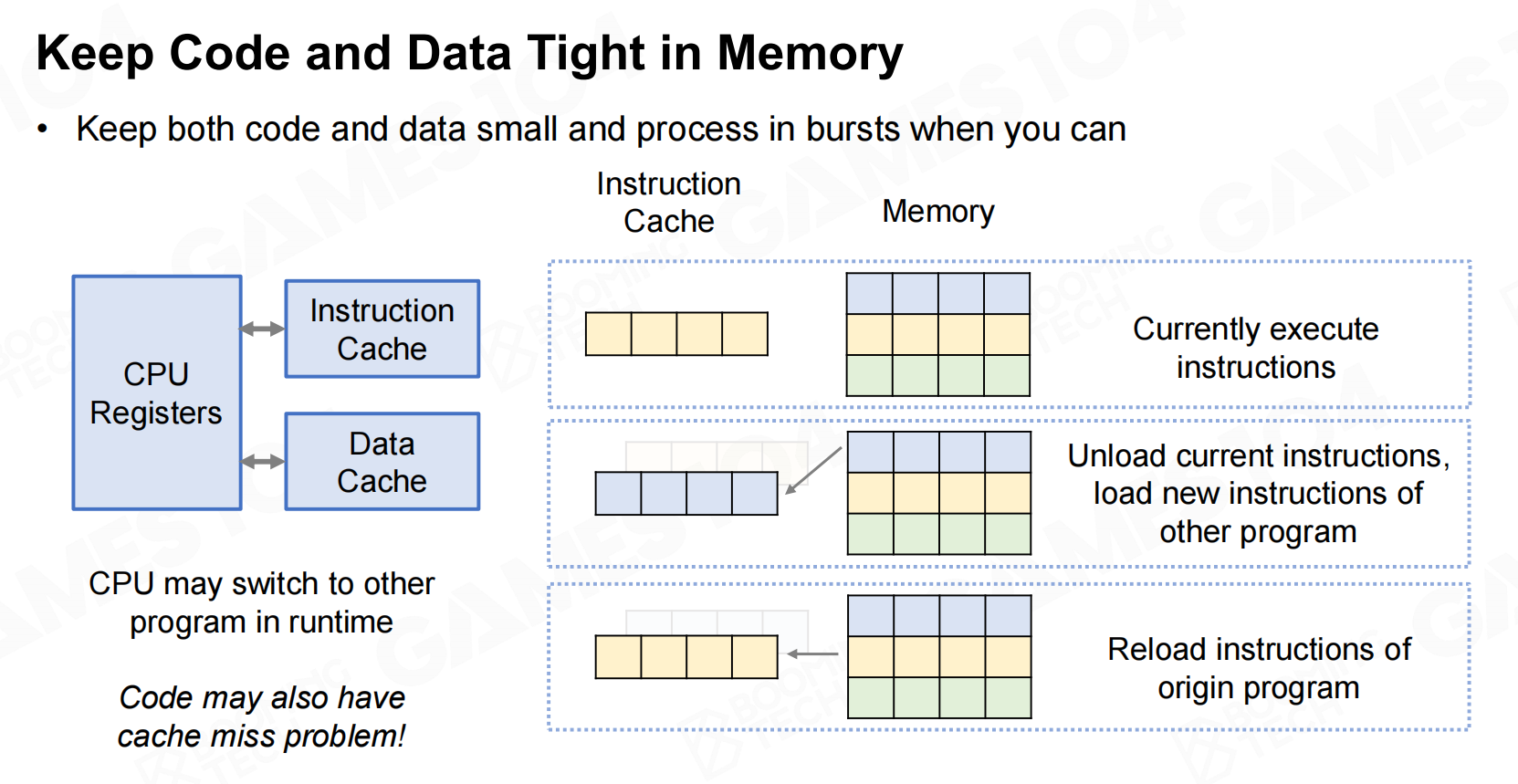 保持代码和数据在内存中
保持代码和数据在内存中
性能敏感编程(Performance-Sensitive Programming)
减少顺序相关性(Reducing Order Dependency)
那么如何基于DOP的思想来设计高性能的程序呢?首先我们需要避免程序对于代码执行顺序的依赖。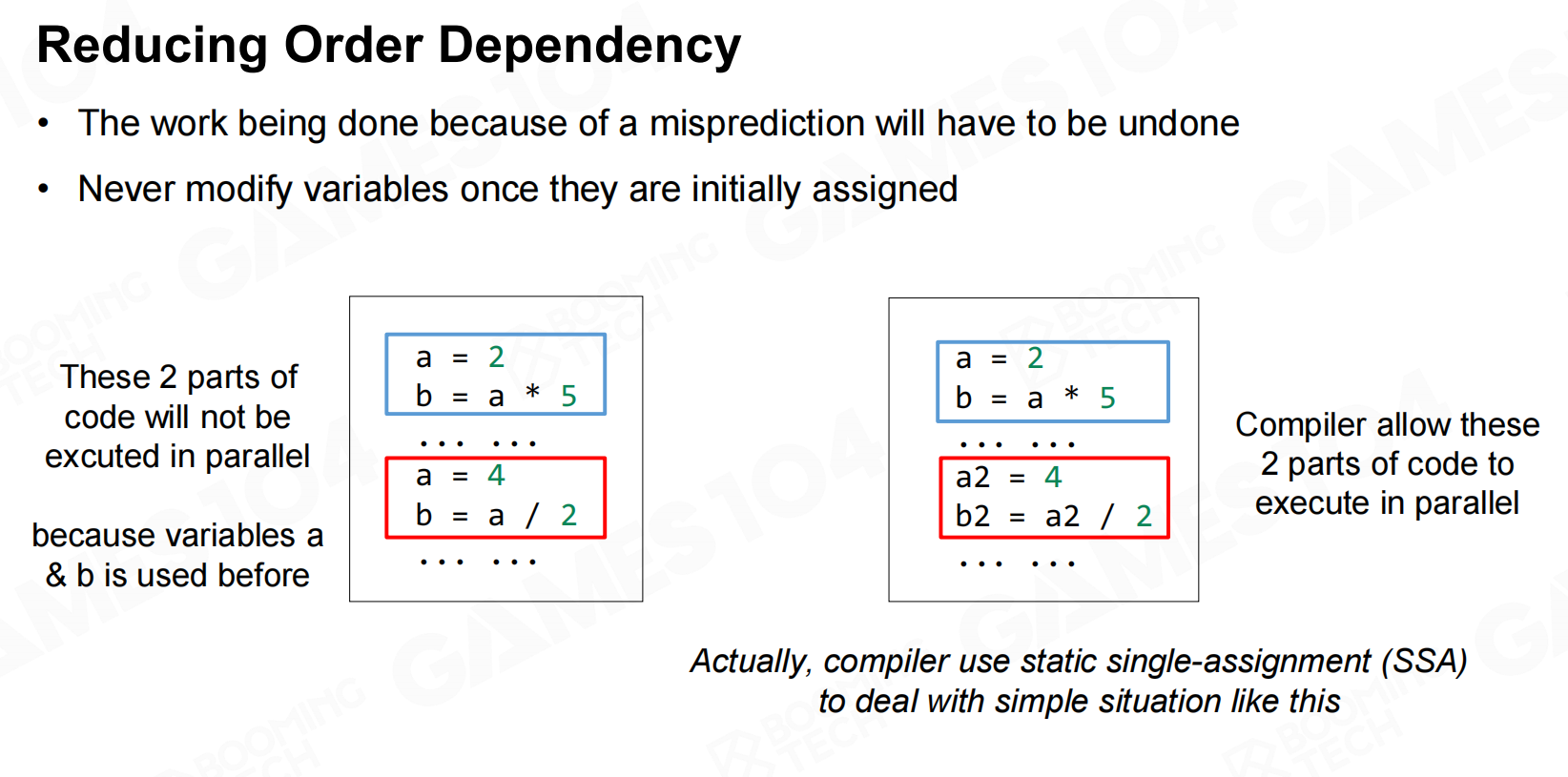 减少顺序相关性
减少顺序相关性
在高速缓存行中的错误共享(False Sharing in Cache Line)
对于多线程的程序要避免两个线程同时访问同一块数据,我们希望不同的线程之间尽可能地相互独立。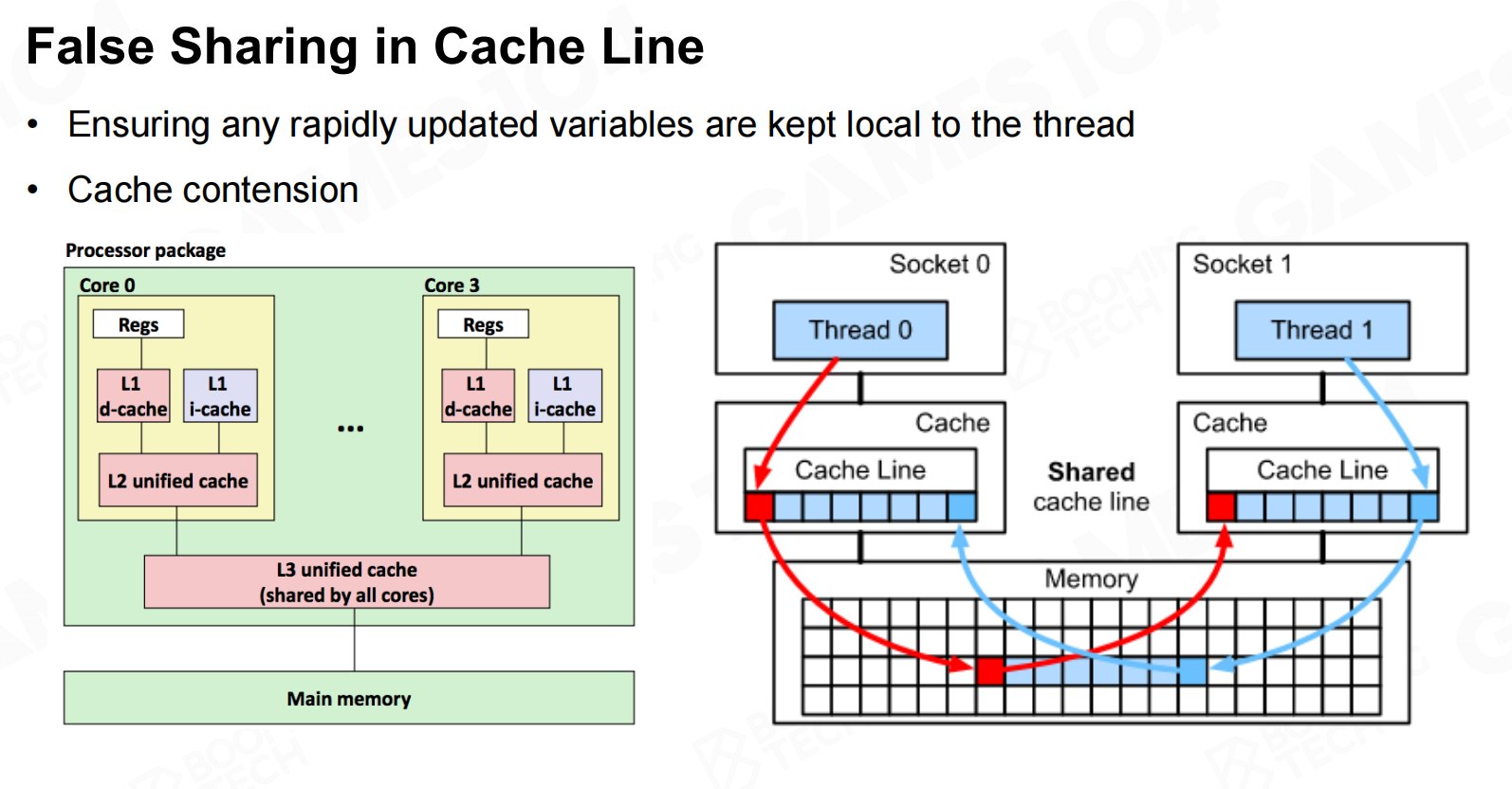 在高速缓存行中的错误共享
在高速缓存行中的错误共享
分支预测(Branch Prediction)
对于包含分支的程序,CPU会对程序可能选择的分支进行预测并把最有可能直线的指令提前送到缓存中,如果程序选择了不常见的分支则往往需要从内存中重新读取相应的指令从而降低程序性能。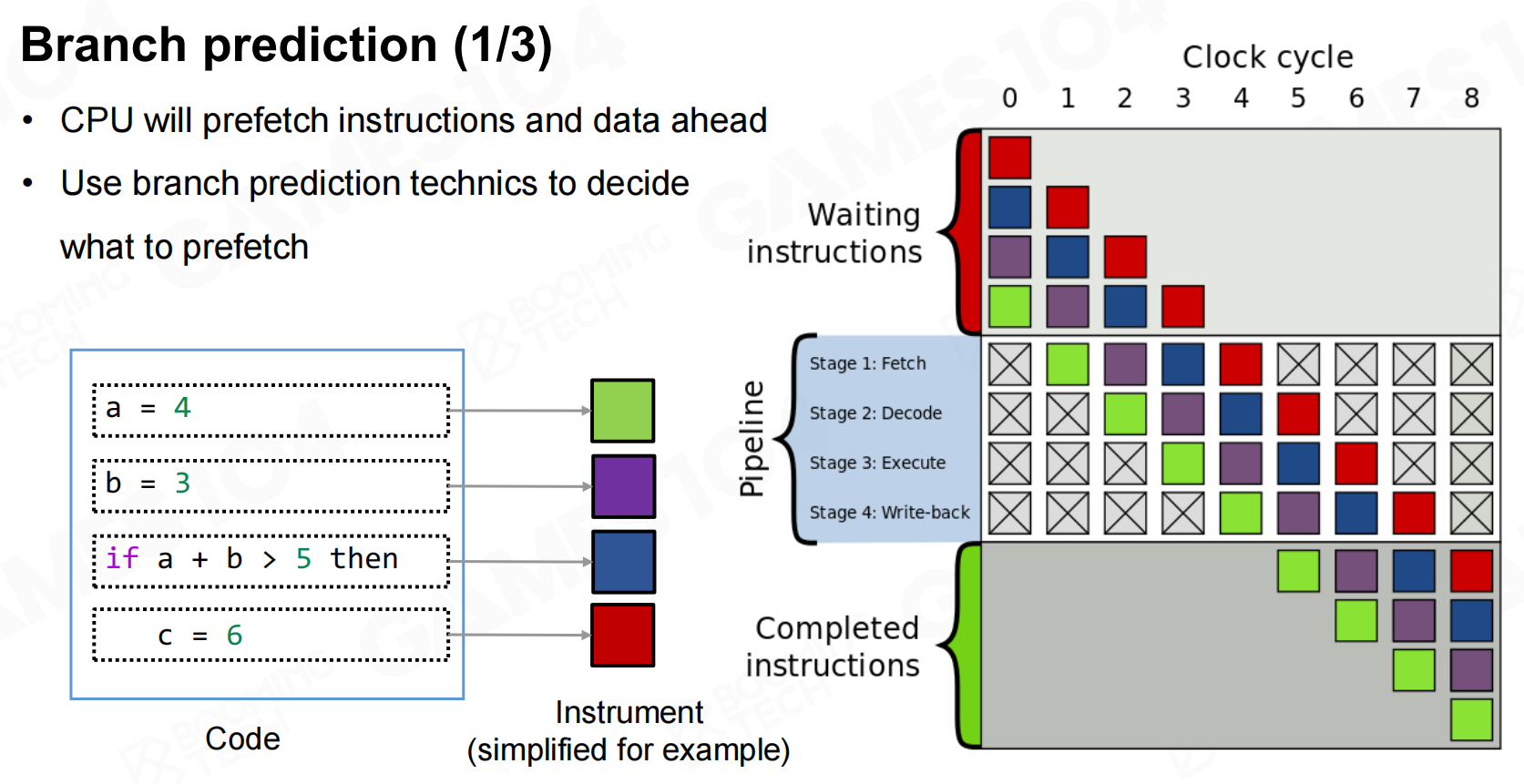 分支预测
分支预测
因此在设计程序时要尽可能保证具有相同分支的程序在一起执行,比如说可以通过对数据进行排序的方式来避免错误的分支预测。 分支预测2
分支预测2 分支预测3
分支预测3
更通用的方法是按照业务逻辑对数据进行分组,每一组中只使用相同的函数进行处理。这样可以完全避免分支判断从而极大地提升程序性能。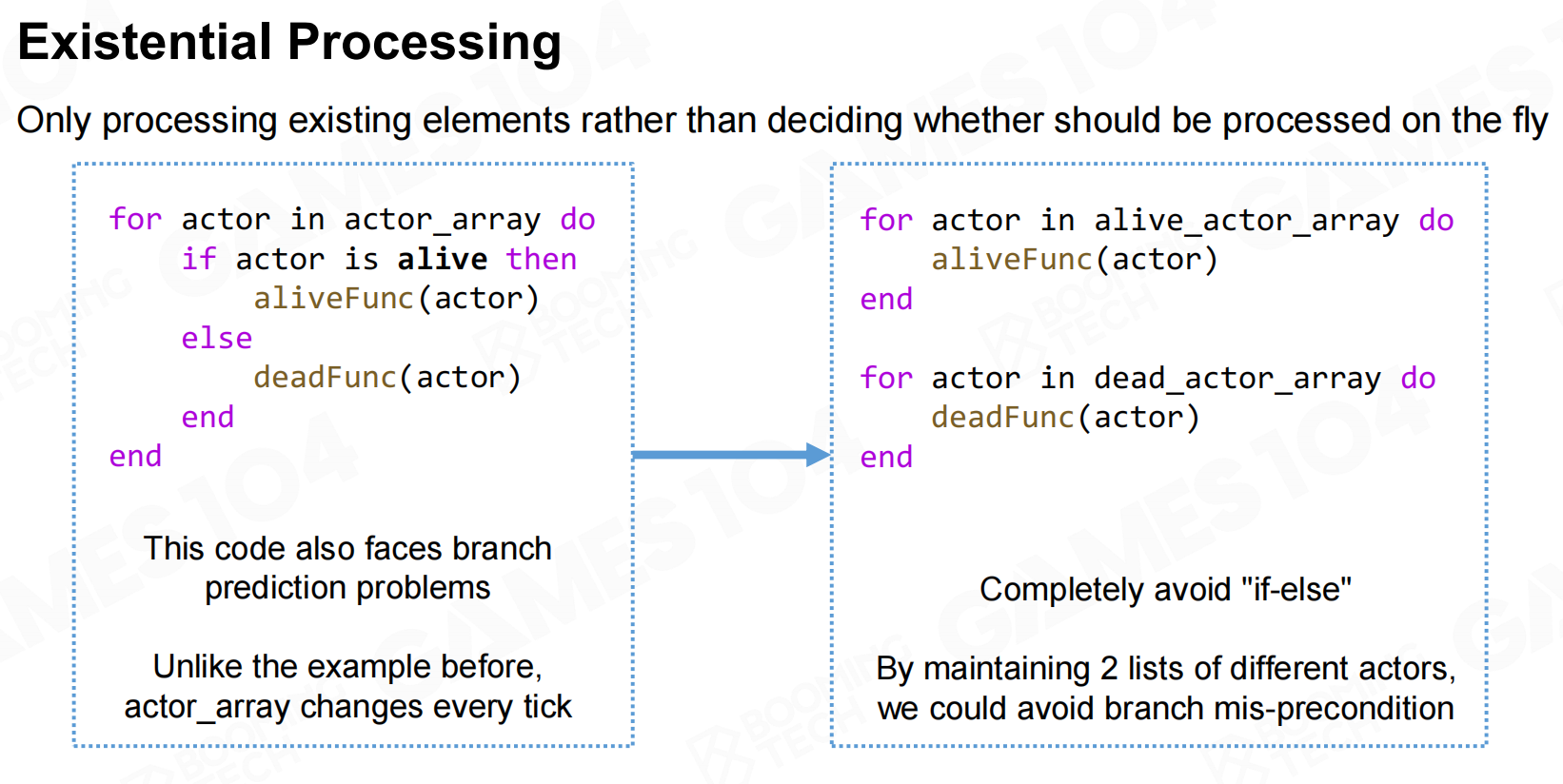 程序处理
程序处理
性能敏感数据组织(Performance-Sensitive Programming)
当然数据的组织方式对于程序性能也有巨大的影响。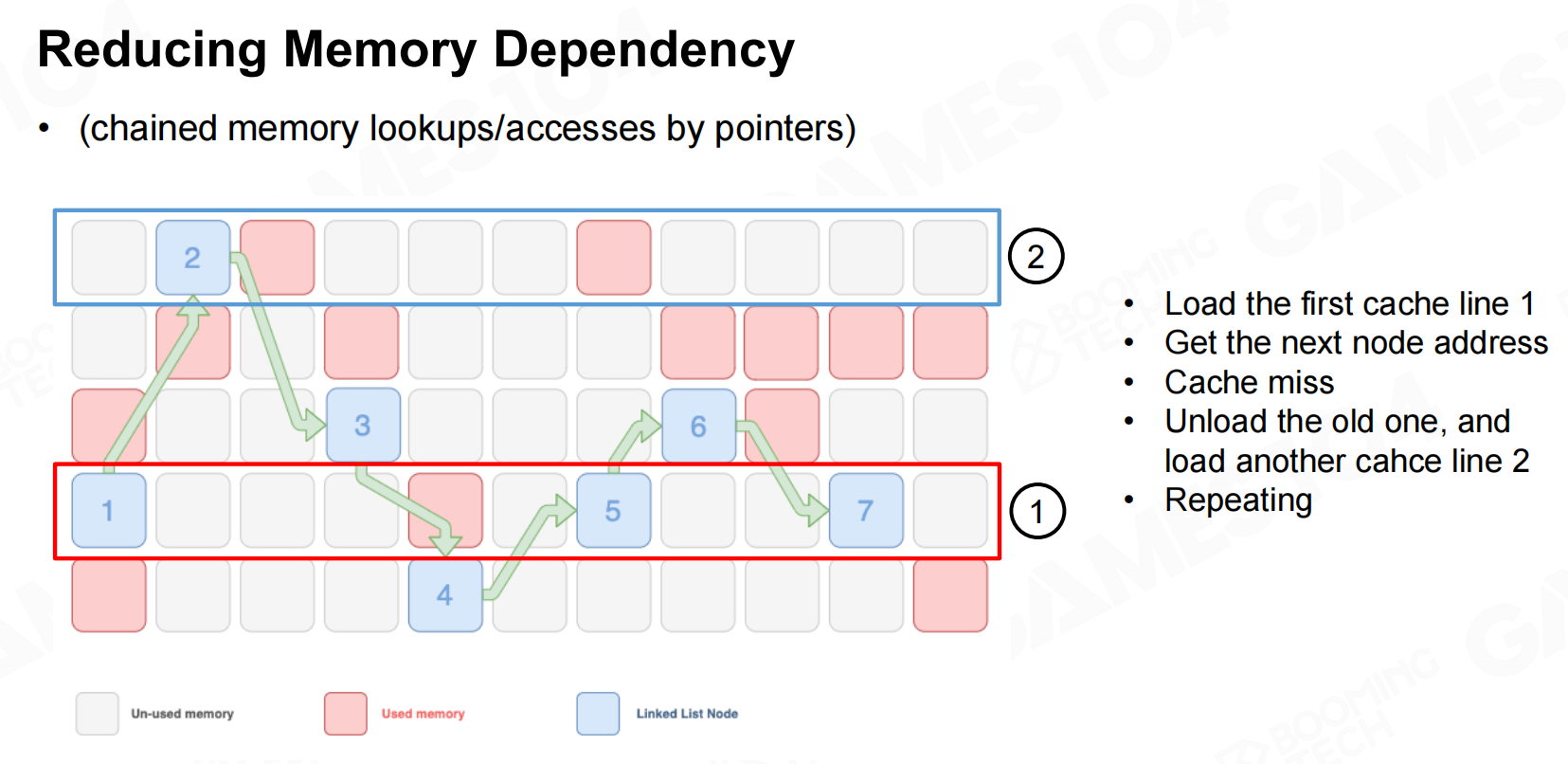 减少内存依赖性
减少内存依赖性
一个经典的案例是AOS和SOA。根据OOP的思想,我们可以把数据封装到不同对象中然后使用一个数组作为这些对象的容器,这种组织方式称为AOS(array of structure);或者直接对数据进行封装把所有数据放到一个巨大的对象中,称为SOA(structure of array)。当程序需要对数据进行访问时AOS往往会产生大量的cache miss,因此在高性能编程中更推荐使用SOA的组织方式。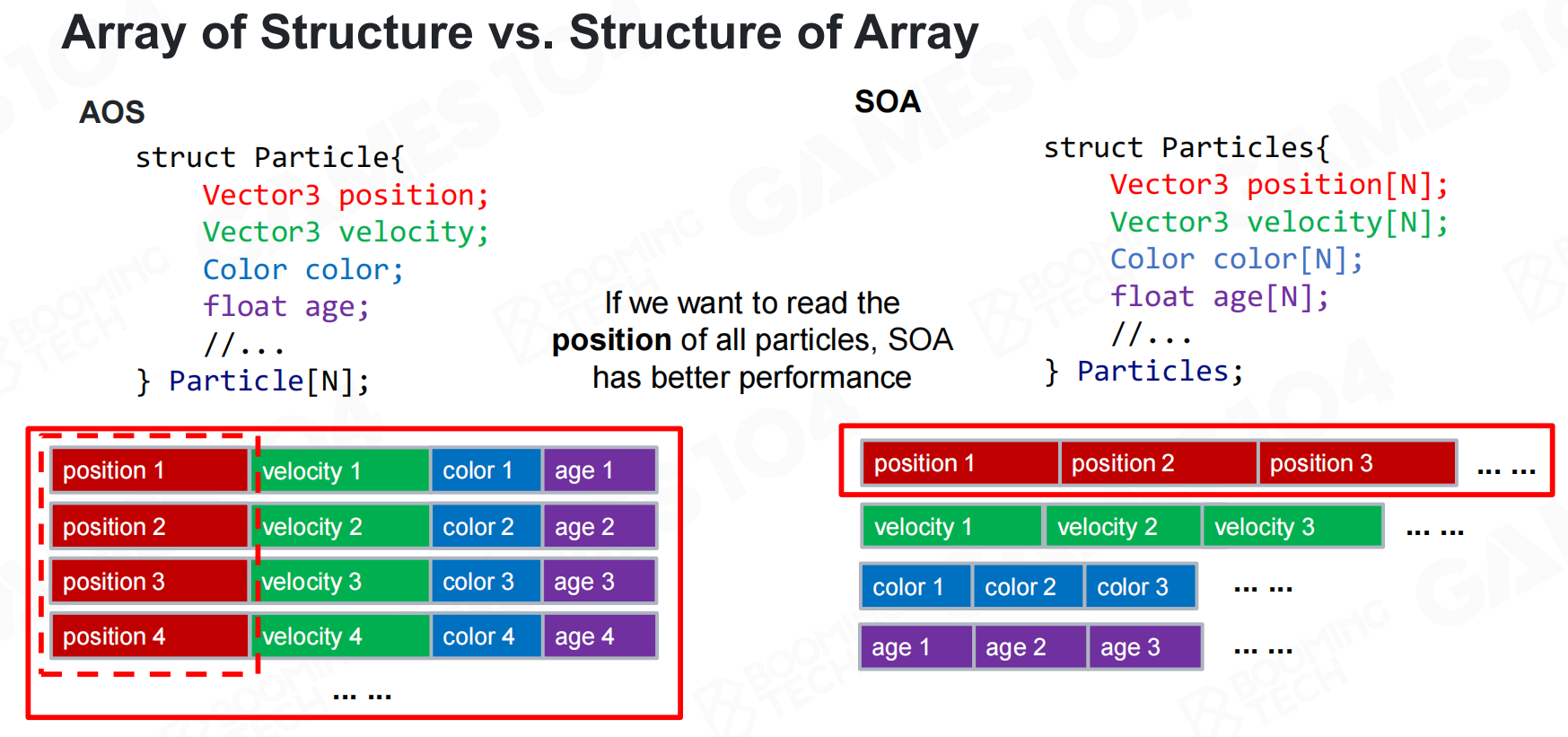 结构阵列vVS阵列结构
结构阵列vVS阵列结构
ECS架构(Entity Component System - ECS)
本节课最后介绍了现代游戏引擎中的ECS架构(entity component system)。回忆在前面的课程中我们介绍过基于OOP来对组件进行编程,然后通过继承的方式来实现具体的GO。就像前面介绍过的那样,这种编程范式是相对低效的。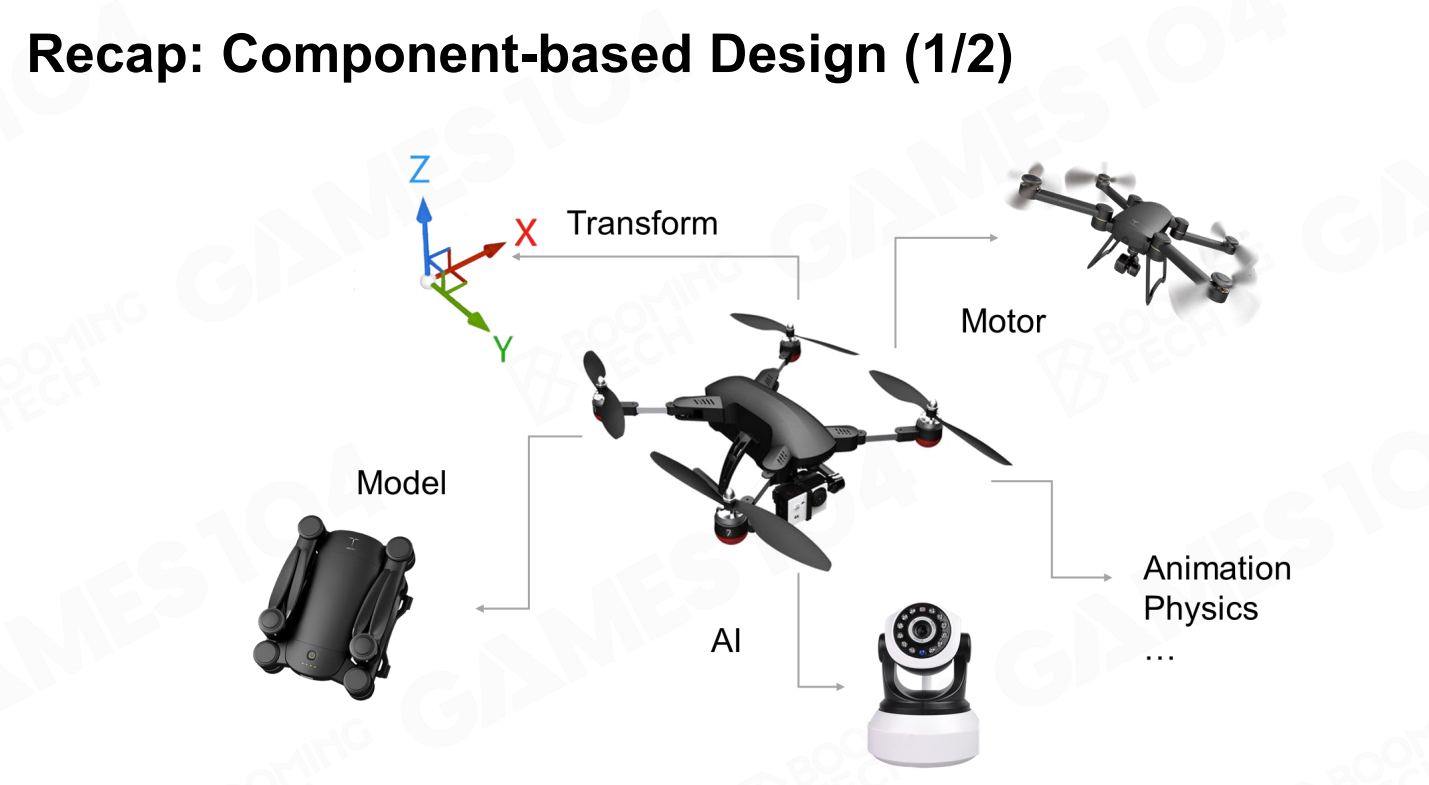 概述:基于组件的设计
概述:基于组件的设计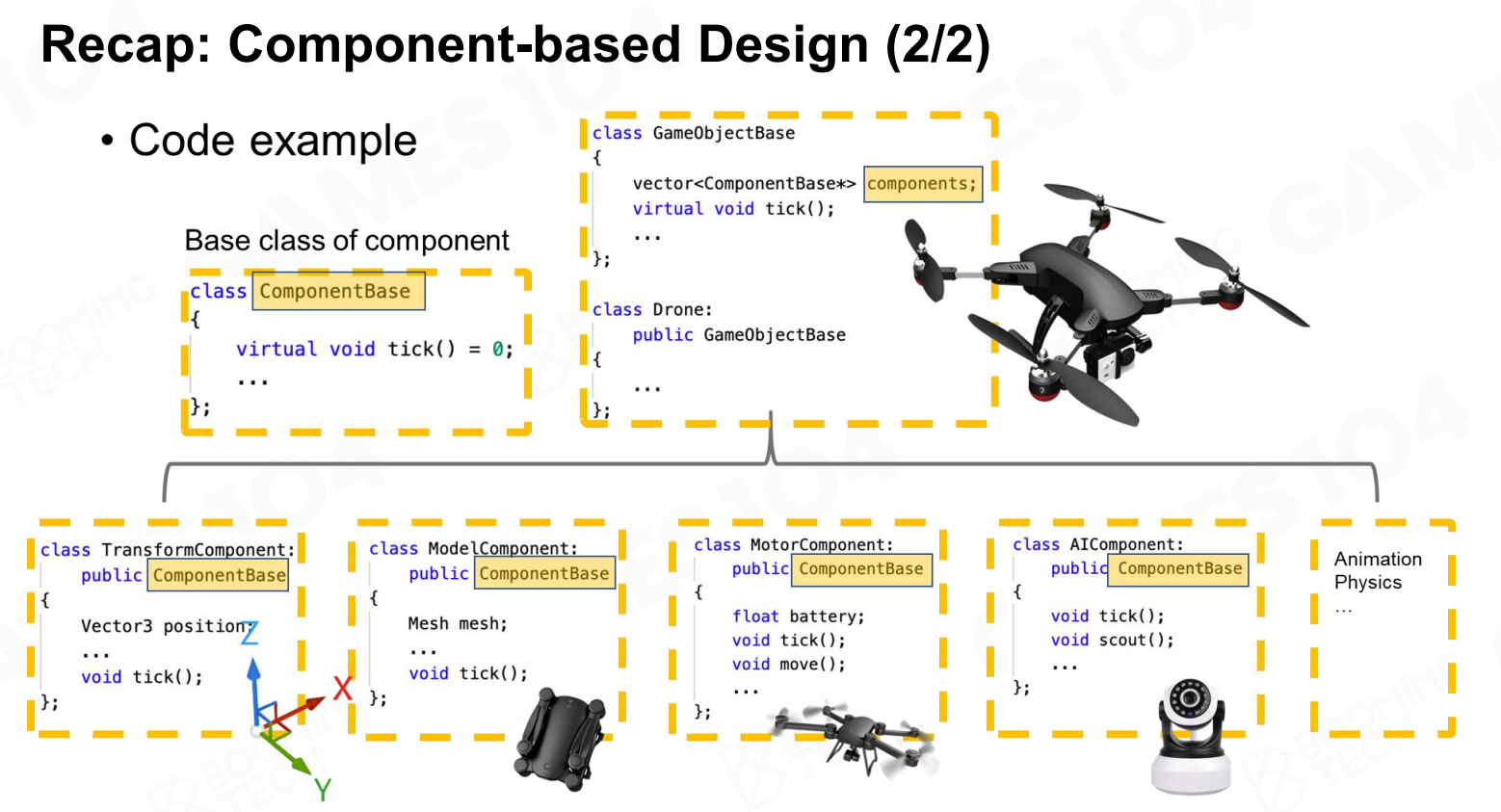 概述:基于组件的设计2
概述:基于组件的设计2
而在ECS架构中则使用了entity的概念将不同的组件组织起来。entity实际上只是一个ID,用来指向一组component。而ECS架构中的component则只包括各种类型的数据,不包含任何具体的业务逻辑。当需要执行具体的计算和逻辑时则需要调用system来修改component中的数据。这样游戏中的数据可以集中到一起进行管理,从而极大地提升数据读写的效率。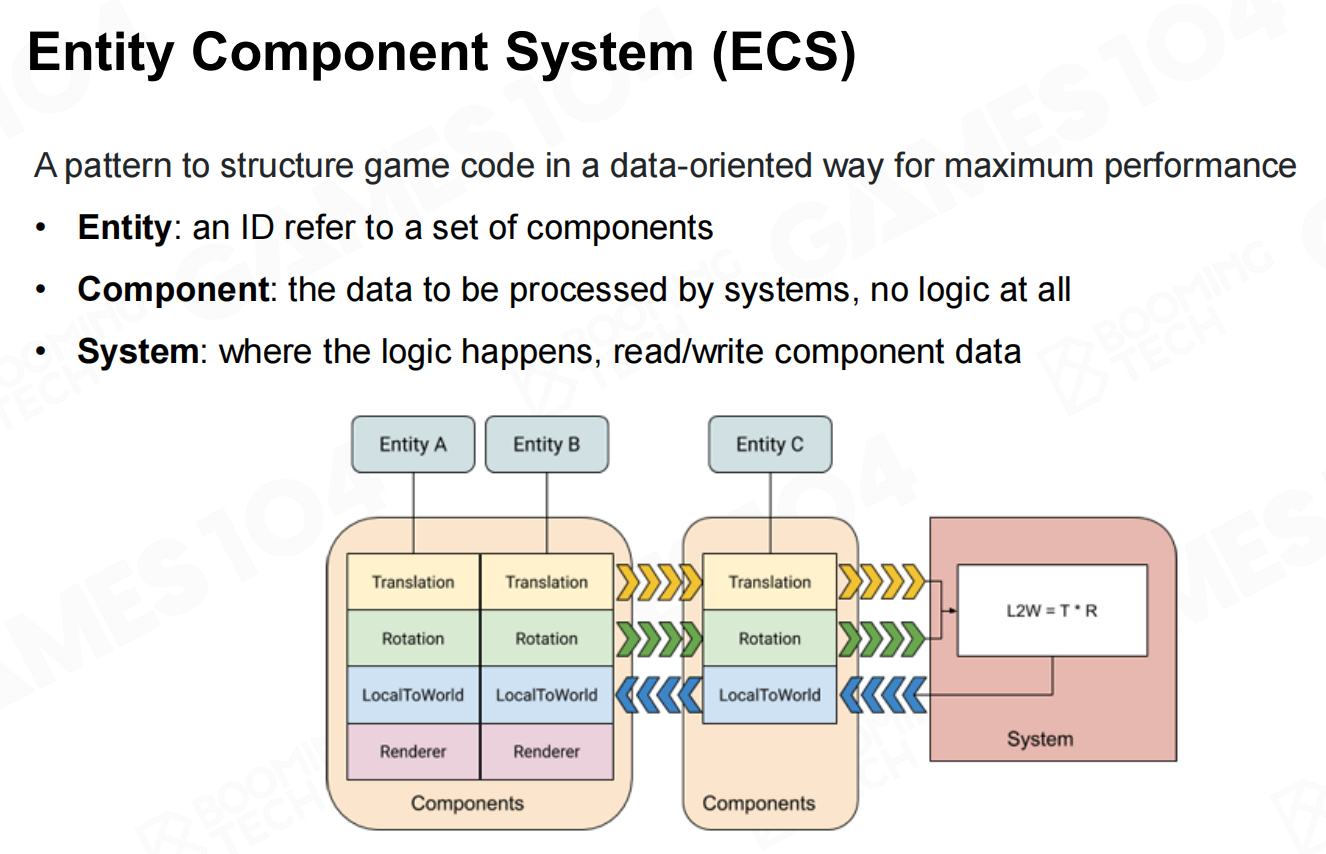 ECS架构
ECS架构
Unity中的面向数据技术栈的系统(Unity Data-Oriented Tech Stacks)
unity中的DOTS系统(data-oriented tech stacks)就是基于ECS架构来实现的,同时它还结合了C#任务系统用来进行并行化以及设计了burst编译器来优化代码。 DOTS系统
DOTS系统
在unity的ECS架构中设计了archetype来对不同类型的entity进行抽象,这样具有相似功能的entity可以组织到一起方便管理。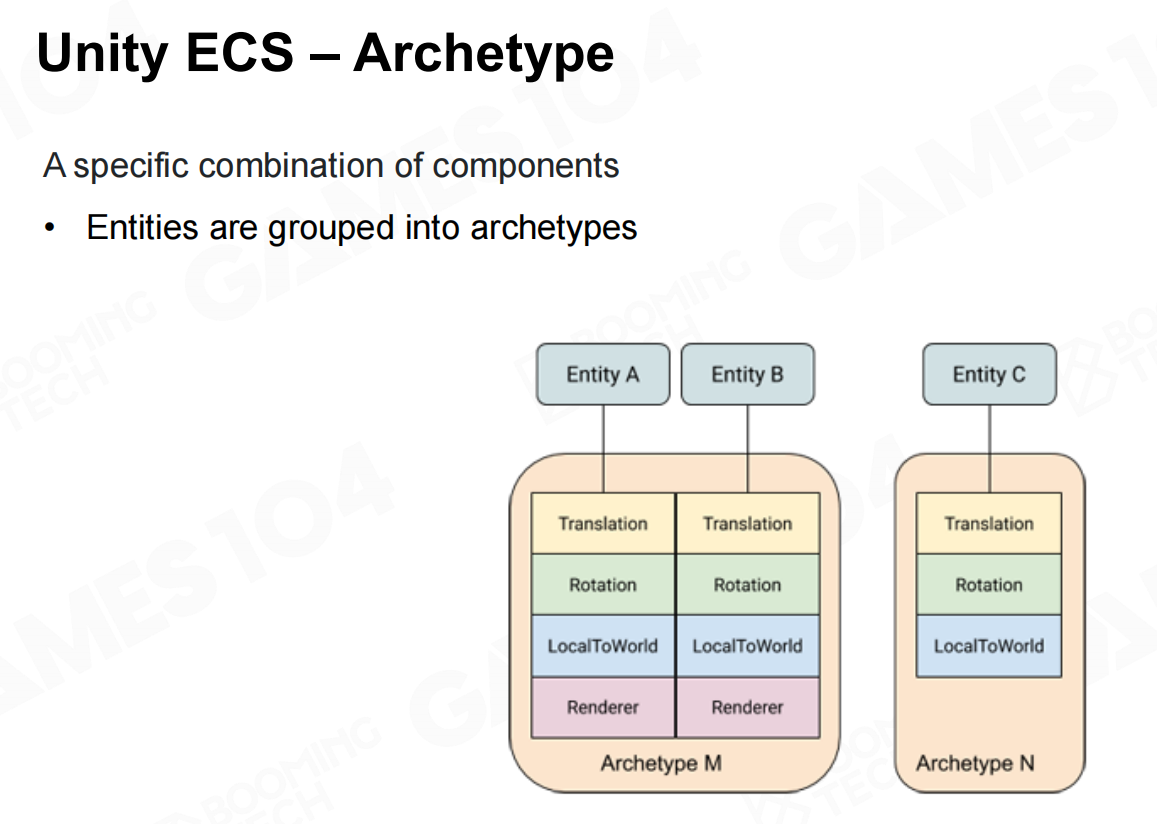 Unity ECS-原型
Unity ECS-原型
在内存中系统会为不同的archetype分配不同大小的存储空间,称为chunk。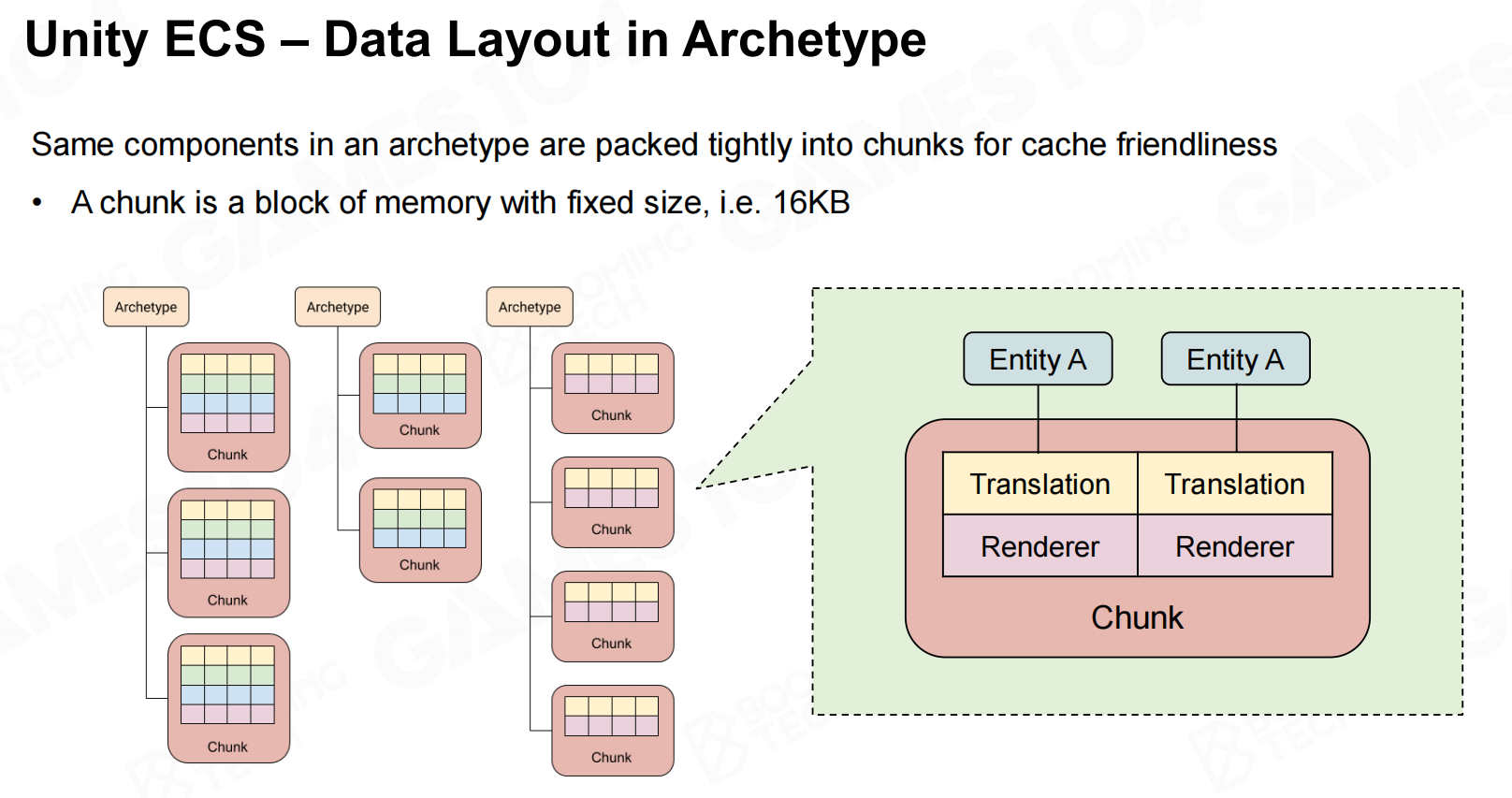 Unity ECS-原型中的数据布局
Unity ECS-原型中的数据布局
对于system而言只需要一次性更新chunk中的相关数据即可。 Unity ECS-系统
Unity ECS-系统
而为了支持这样的高性能架构还需要native级别的任务系统、容器以及安全检查,也因此unity需要定制编译器来把C#代码编译成更底层的代码。 Unity C# 任务系统
Unity C# 任务系统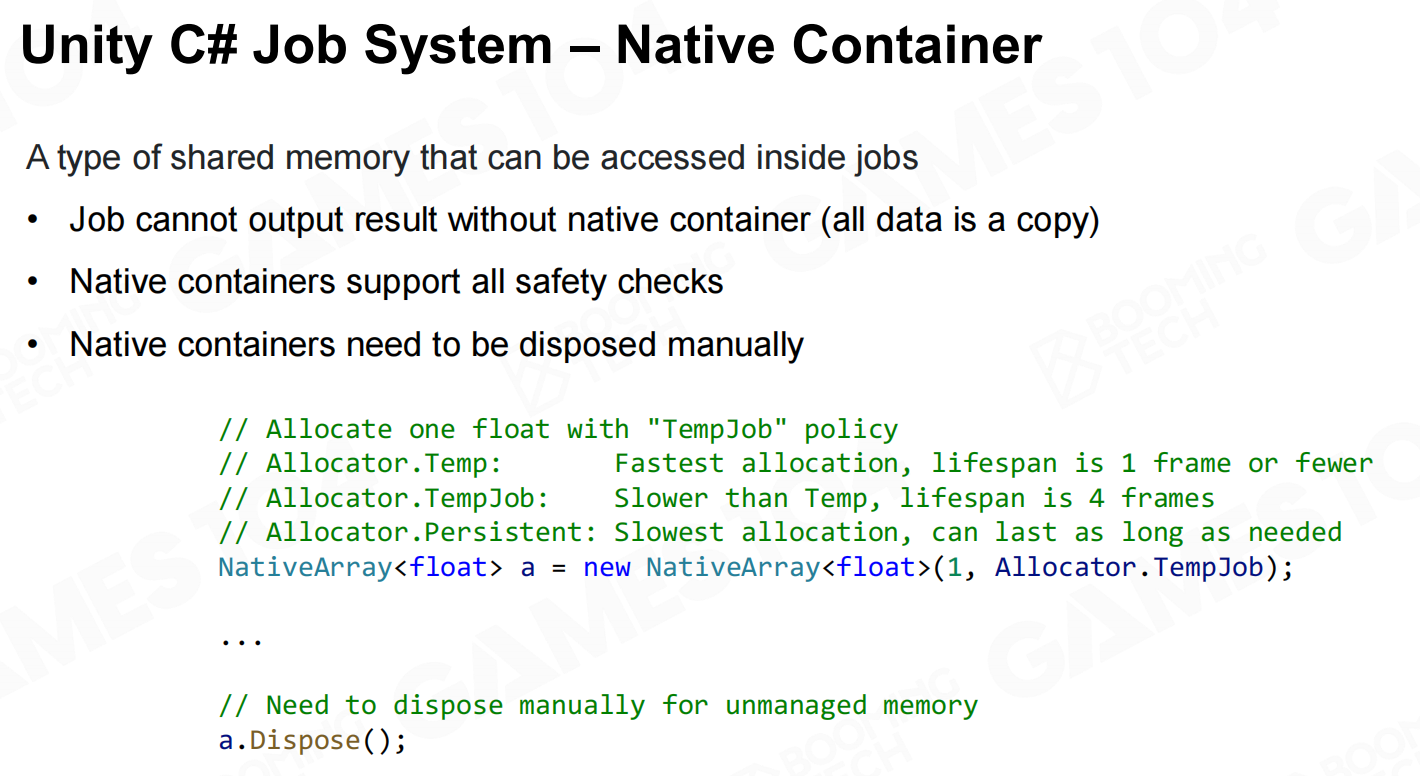 Unity C# 任务系统-本地容器
Unity C# 任务系统-本地容器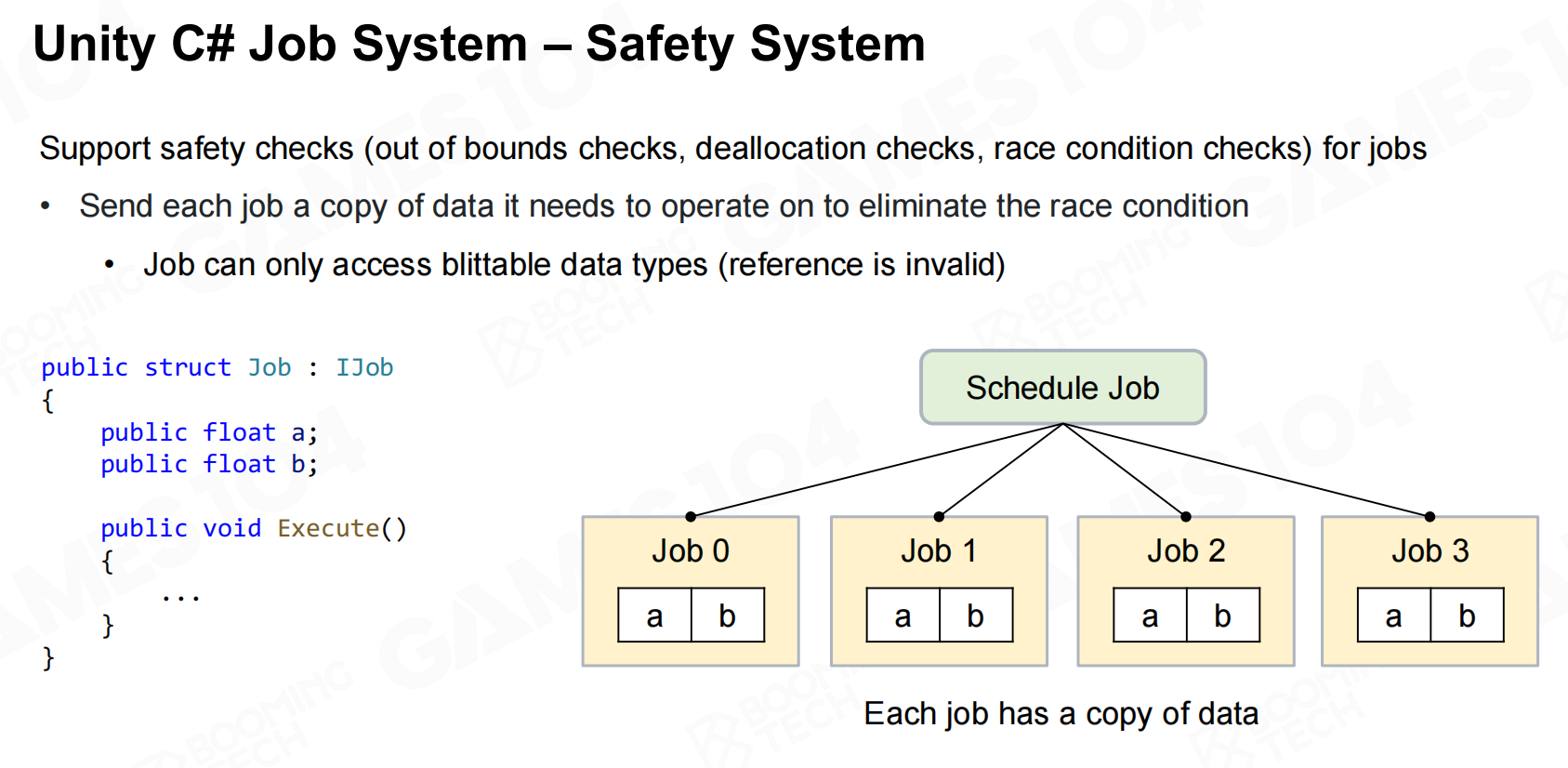 Unity C# 任务系统-安全系统
Unity C# 任务系统-安全系统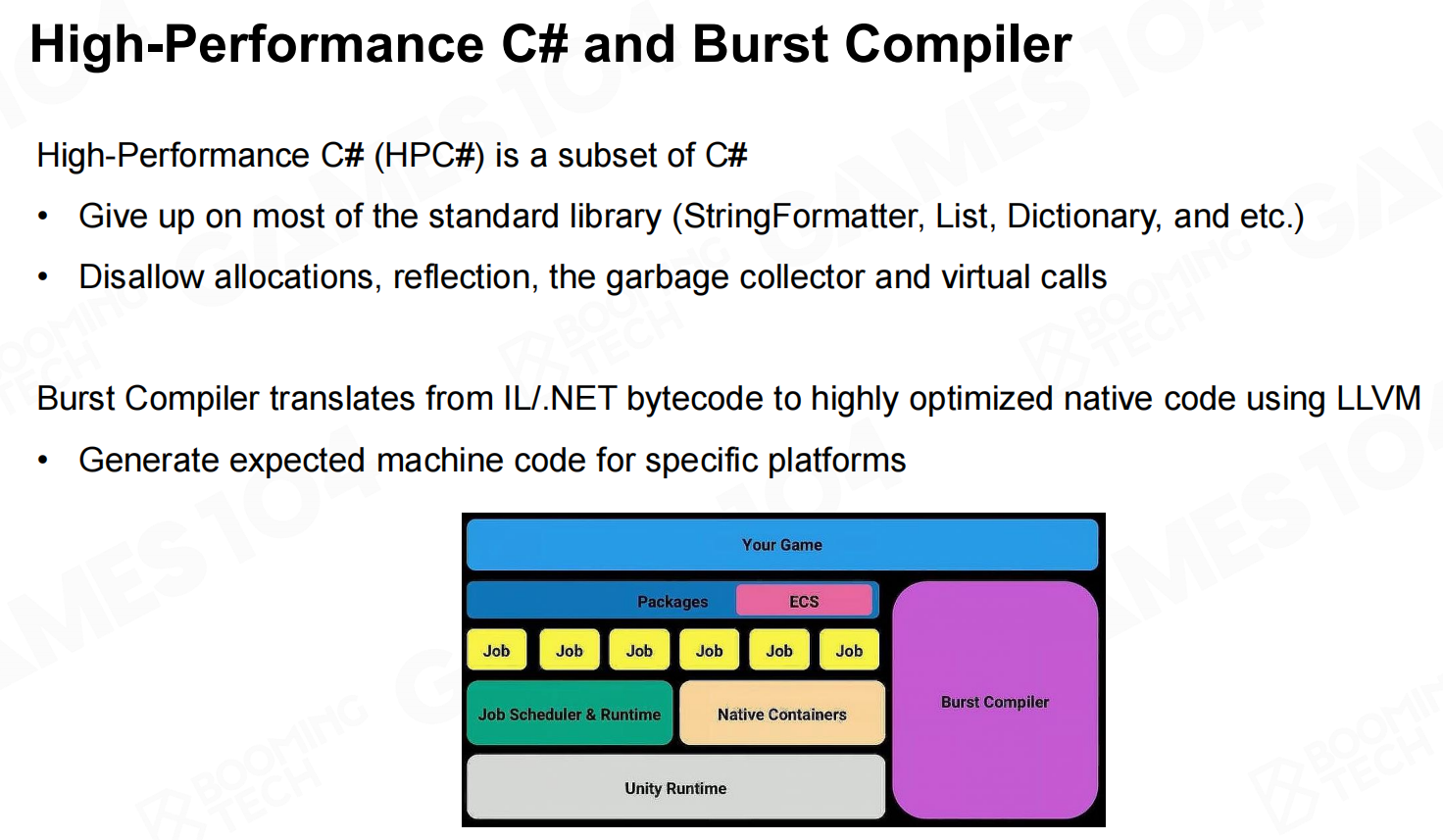 高性能的C#和Burst编译器
高性能的C#和Burst编译器
虚幻质量系统(Unreal Mass System)
虚幻引擎中使用了Mass系统来实现ECS架构。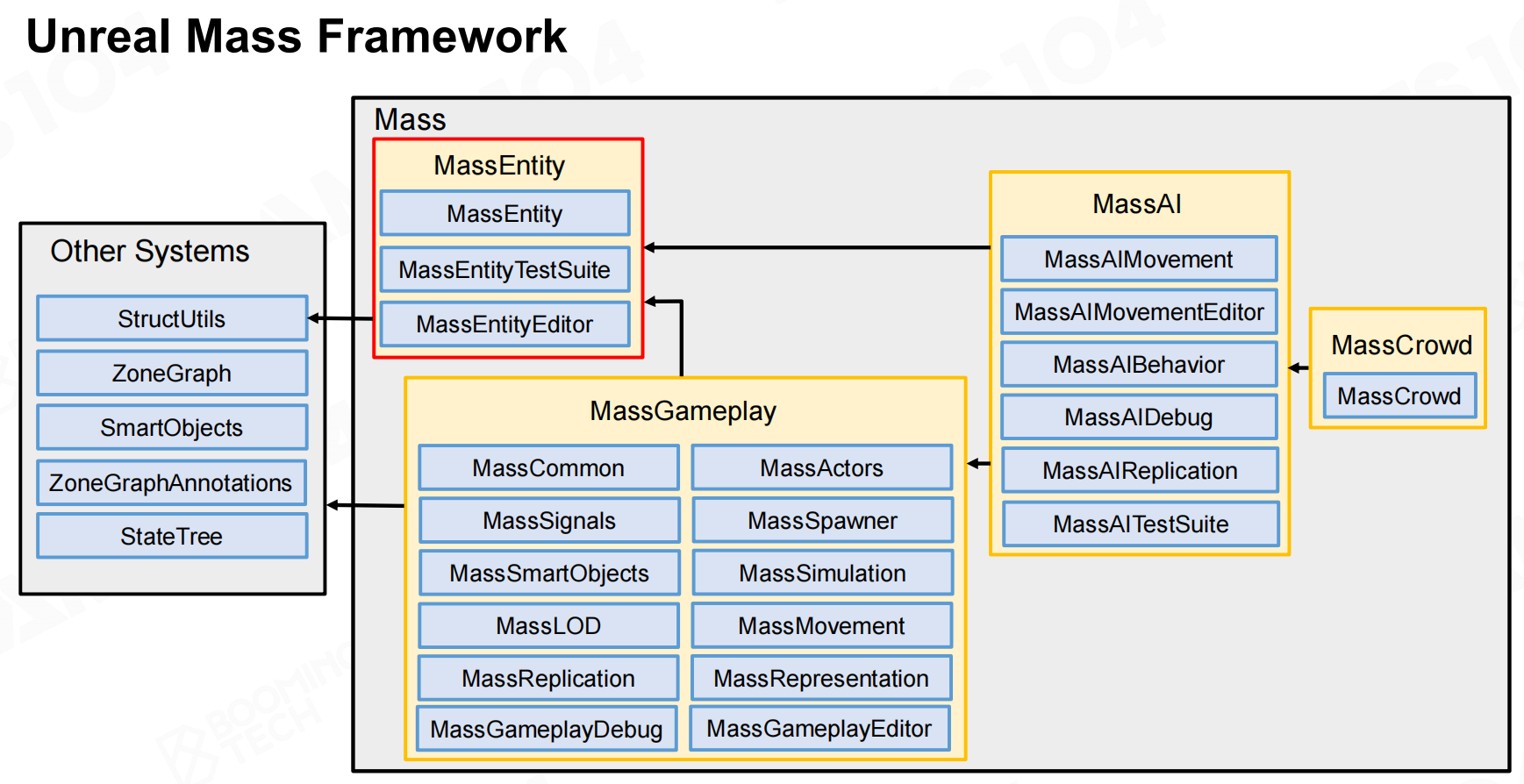 虚幻Mass框架
虚幻Mass框架
Mass系统与DOTS非常类似,都使用了entity作为component的索引ID。 Mass实体
Mass实体
Mass系统中的component称为fragment,用来强调它只具有数据的属性。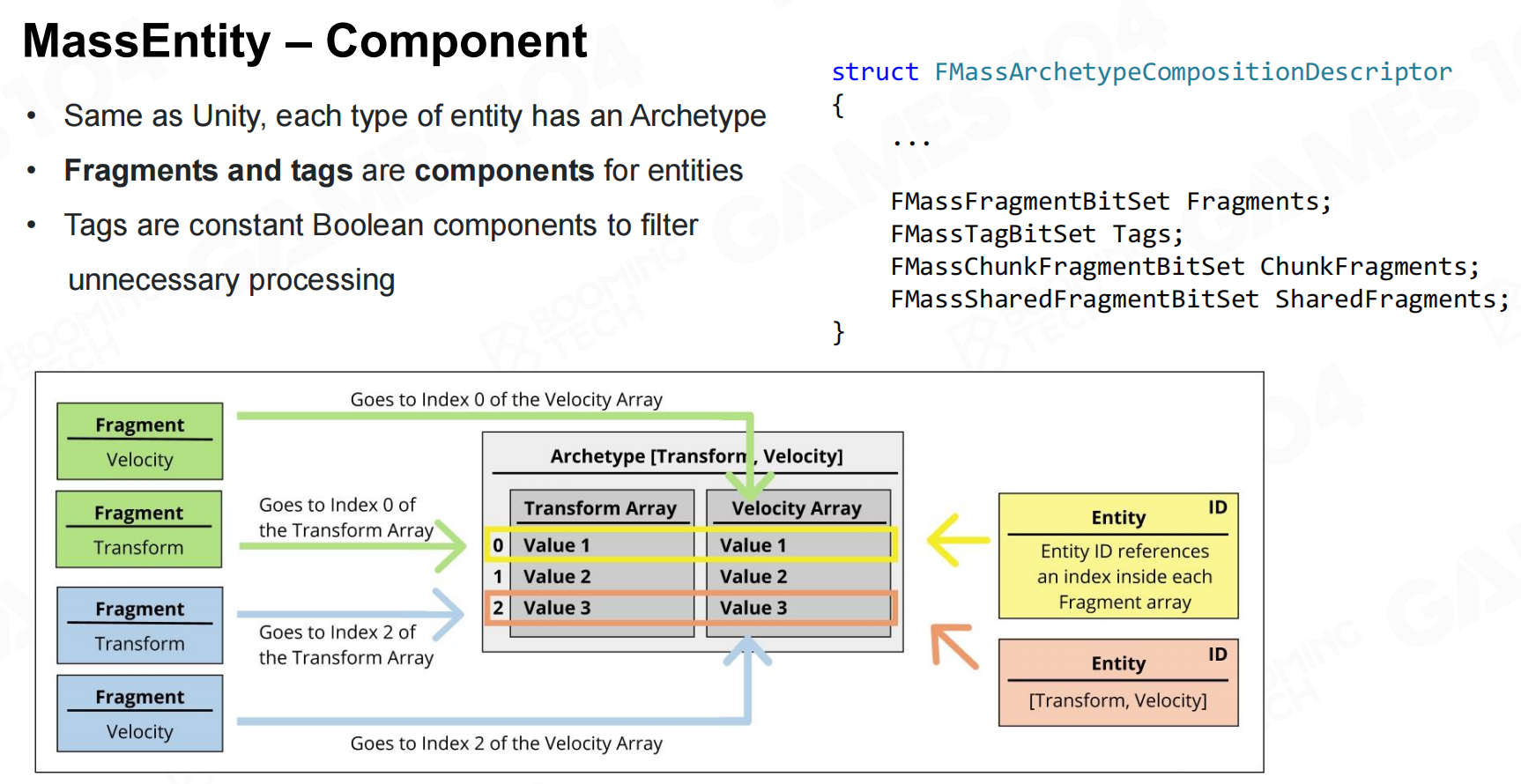 Mass实体-组件
Mass实体-组件
而system则称为processor,这表示它只承担业务逻辑的功能。 Mass实体-系统
Mass实体-系统
processor需要实现query和excute两个接口。前者表示在内存中选出所需的entity,而后者则是不同system执行的逻辑。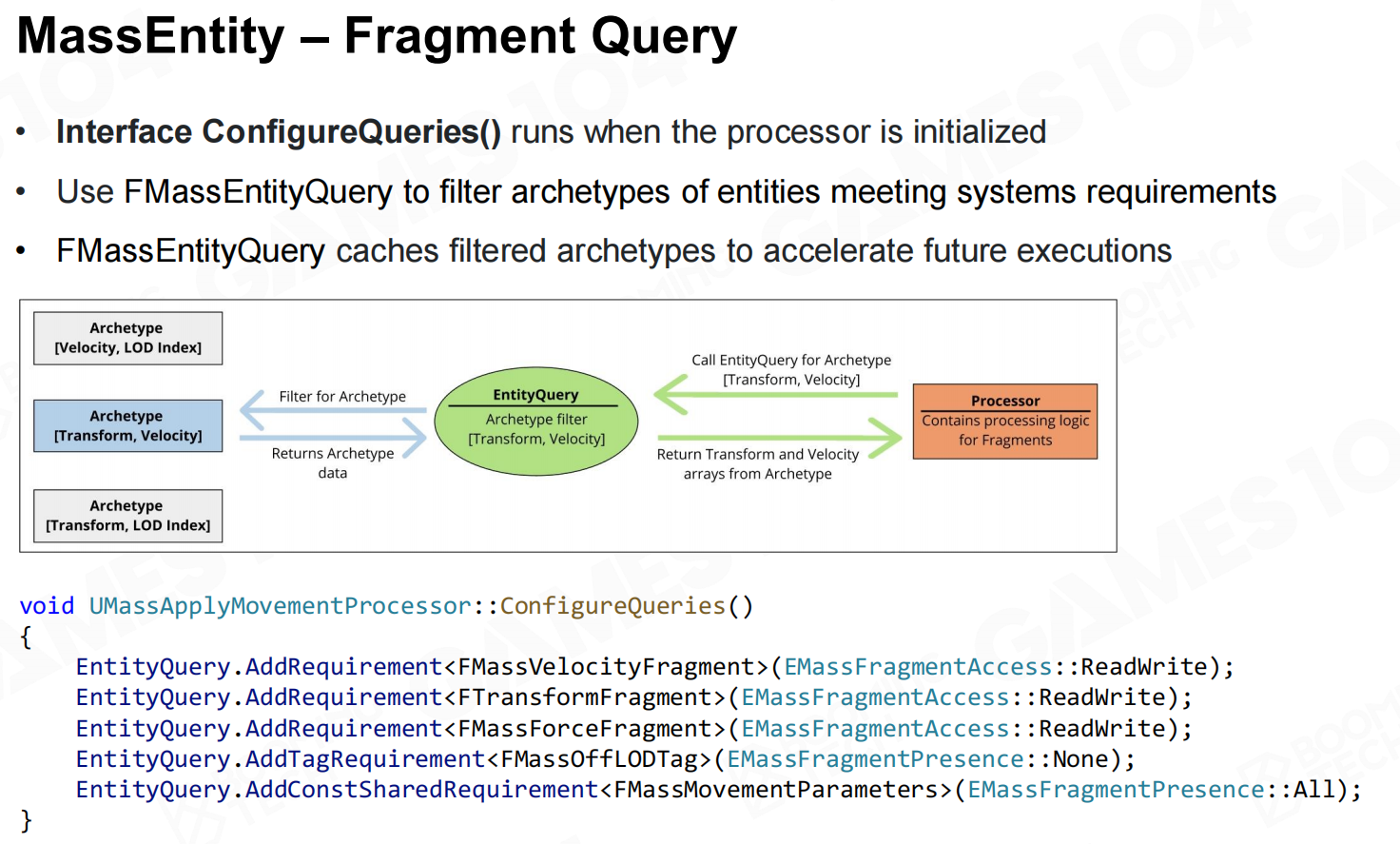 Mass实体-片段查询
Mass实体-片段查询 Mass实体-执行
Mass实体-执行 所有你需要知道的关于性能的东西
所有你需要知道的关于性能的东西
引用
- 本文作者:樱白 - Cherry White
- 本文链接:https://cherry-white.github.io/posts/8a707622.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!
☕ 如果这篇文章对你有帮助
欢迎请我喝杯咖啡,支持持续创作