
现代游戏引擎 - 游戏引擎中的渲染实践:网格、材质与可见性裁剪(四)
渲染概述
渲染是游戏引擎的基础,而渲染的理论基础是计算机图形学。但计算机图形学与游戏渲染存在一些区别:
- 计算机图形学面对的问题是明确单一的。
- 计算机图形学更多关注算法的正确性。
- 计算机图形学没有严格的性能需求。
游戏渲染面对的挑战:
- 游戏融合了大量渲染效果,复杂度很高
- 游戏需要面对硬件处理问题
- 游戏在不同的场景下需要有稳定的帧率
- 游戏CPU端大量的计算需要分配给GamePlay
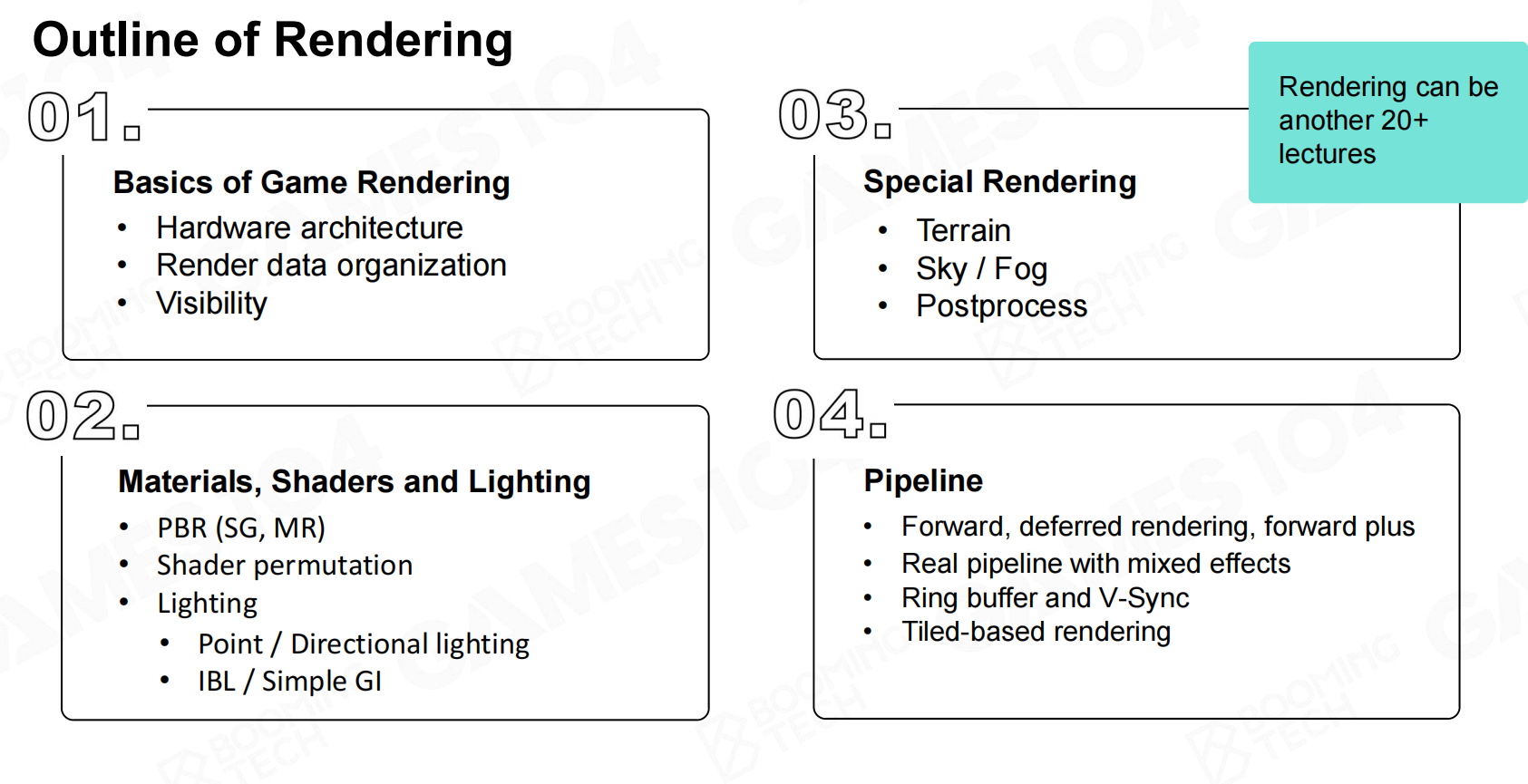 渲染大纲
渲染大纲
渲染系统的对象
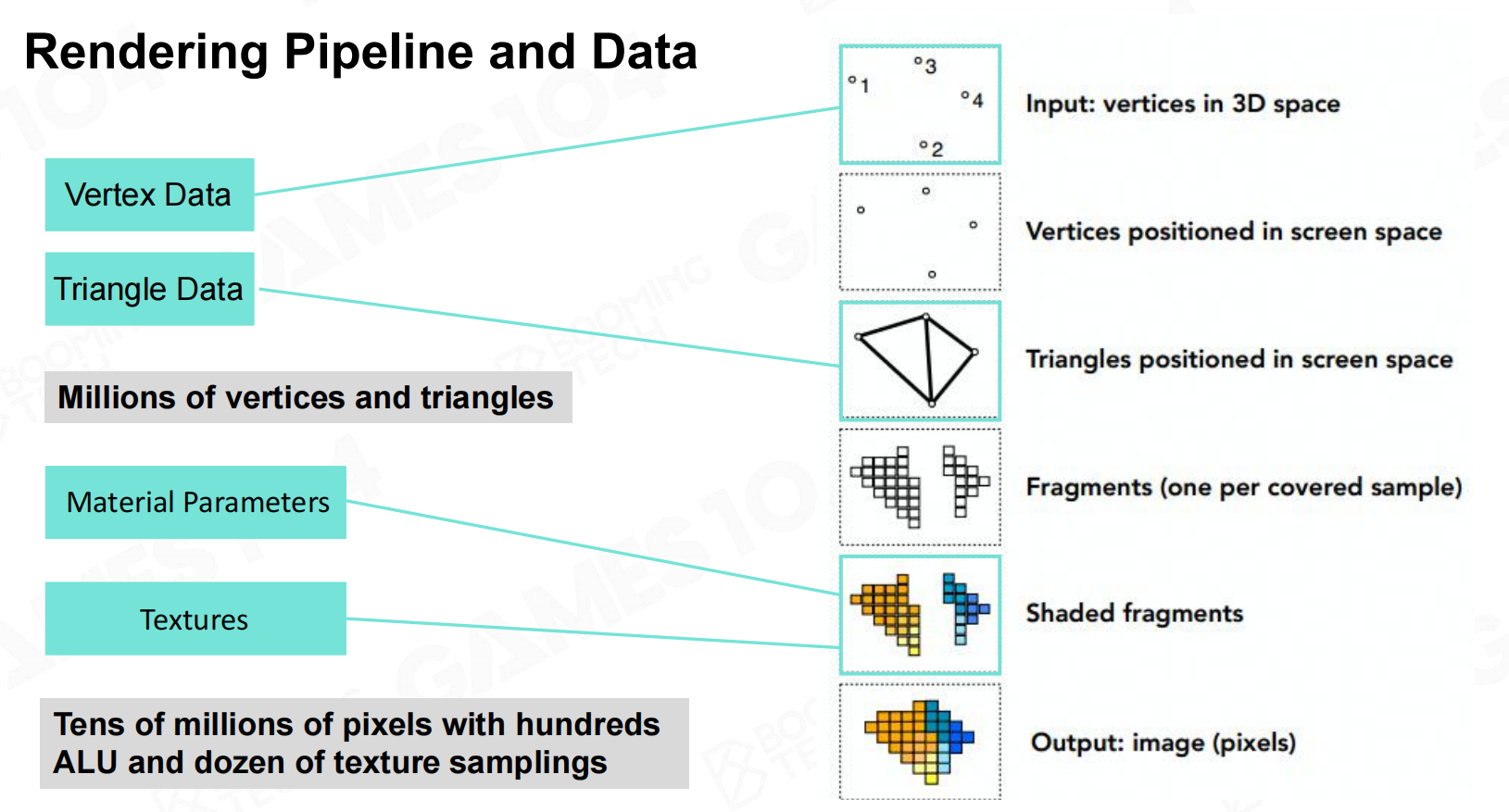 渲染管道和数据
渲染管道和数据
现代游戏渲染是通过CPU+GPU合作处理模式。CPU准备好数据渲染数据后将其提交到GPU,GPU设置好渲染状态后开始处理CPU所提交的数据。
GPU拿到顶点数据集后,对这些顶点进行空间坐标转换(MVP)投射到屏幕中,并组装成三角面。
现代的显示器通常是栅格化的,因此需要将三角面映射到屏幕中的像素,最终对这些像素进行着色处理。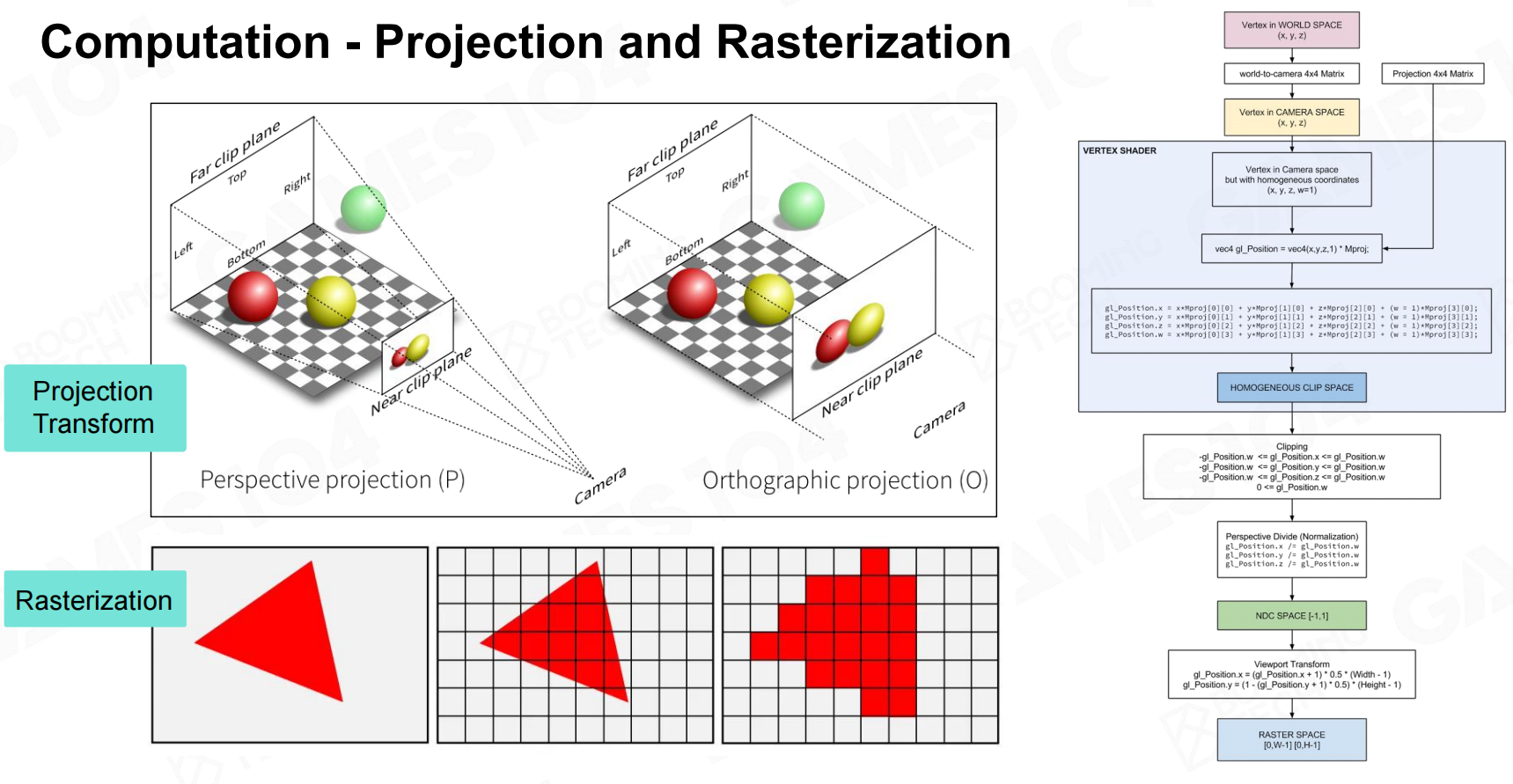 计算投影和光栅化
计算投影和光栅化
Shading涉及到的计算:
- 常量访问,比如需要知道屏幕的长宽,像素个数,需要访问常数
- 数学计算(加减乘除),比如冯模型需要知道法线,光线,眼睛,并计算光有衰减百分比
- 纹理采样
 着色计算类型
着色计算类型
纹理采样其实是rendering过程中非常昂贵的一个环节,当我们在不同距离观察物体的时候,可以看到物体上的一个个或者空间上的像素。
为了避免纹理采样时的锯齿问题,通常会对纹理进行差值处理。当纹理小于采样区域时,可通过双线性插值的方式进行处理;
当纹理区域大于采样区域时,可通过Mipmap、各向异性过滤、EWA过滤等方式处理。
了解GPU
现在CPU中已经广泛使用了SIMD(Single Instruction Multiple Threads)单指令多数据的处理方式,通常为矢量数据。
例如一个32bit位宽的4维向量vec4,一条指令最快就在一个cycle执行完。那SIMT,最快要用4个cycles来完成。
而GPU在多核中使用SIMT指令来实现类似SIMD功能,并且支持分支跳转。在SIMT的架构上,会把vec4分解开,然后一个cycle处理完一个数据。
所以最快需要4个cycle。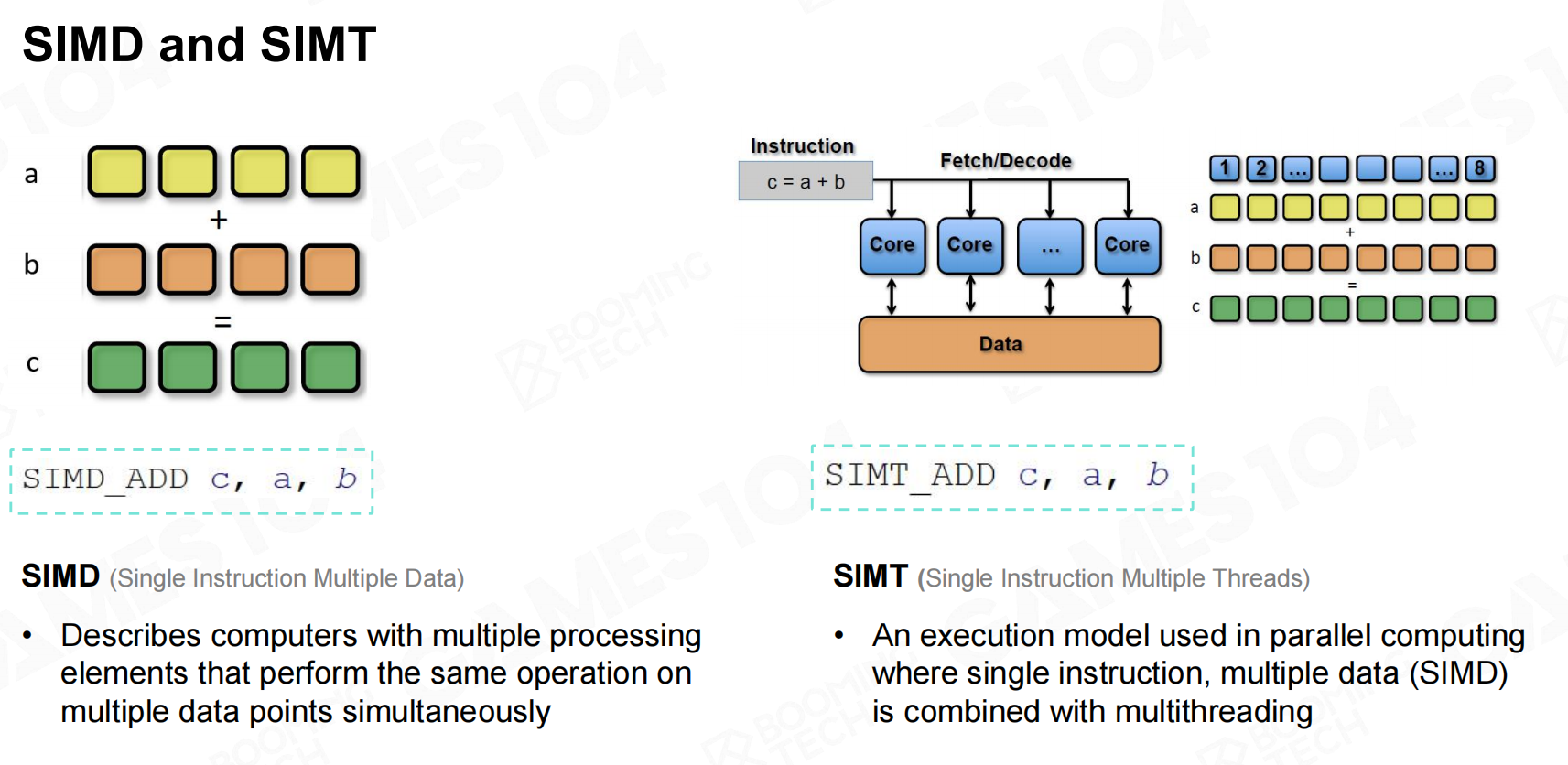 SIMD和SIMT架构
SIMD和SIMT架构
Fermi是第一个完整的GPU计算架构。GPU中分为很多组内核,一组内核称为GPC(Graphics Progressing Cluster)。
GPC中存在很多小的内核,这些内核是指令的直接执行者。Texture Unit进行纹理采样,CUDA Core用于多核之间的数据交换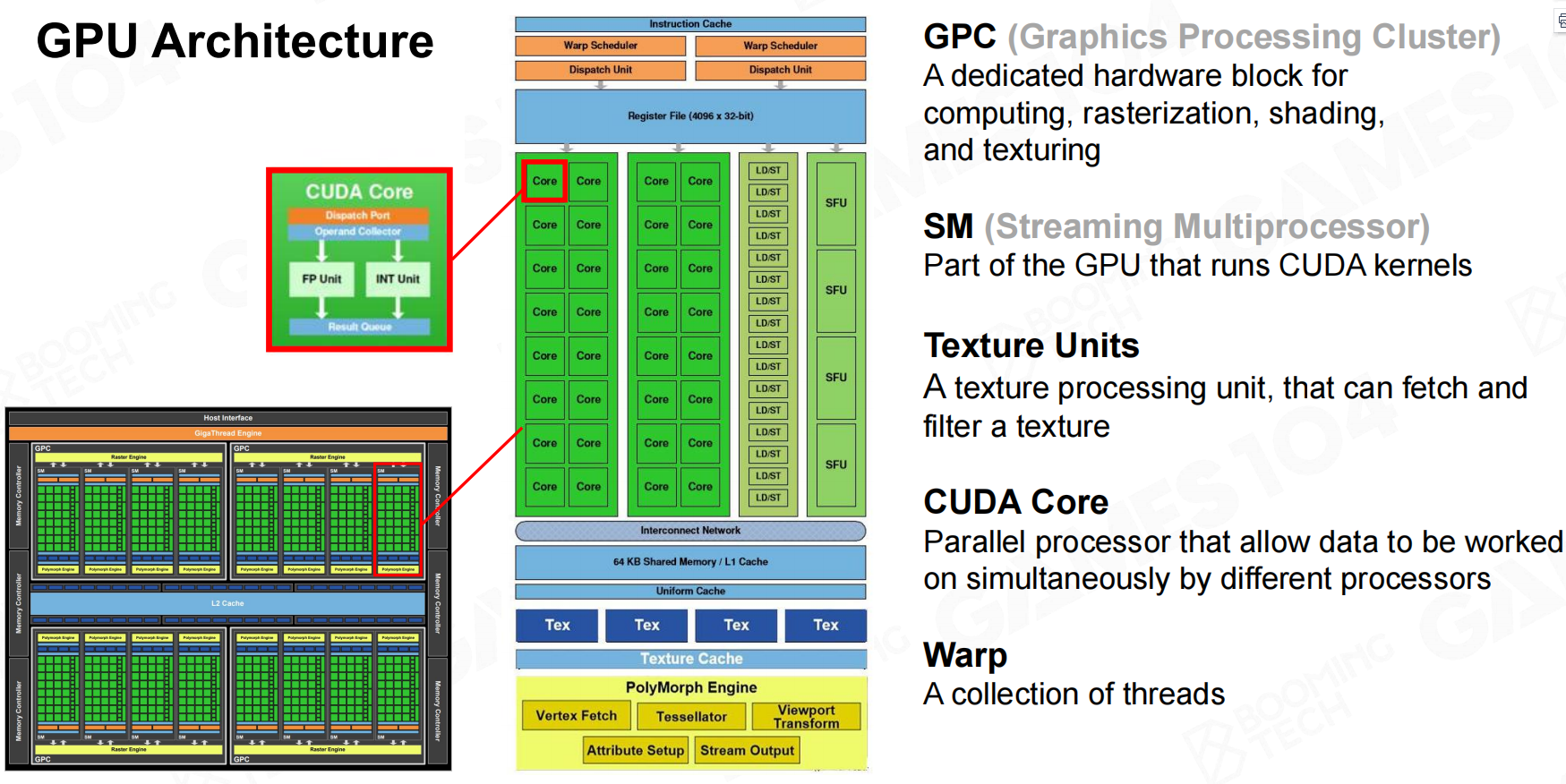 Fermi架构
Fermi架构
CPU和GPU可以看做是独立的机器,两个机器之间的数据传递成本很高。
现代CPU的架构是冯诺依曼架构:数据与计算分离,这种架构的问题就是计算式需要准备好数据。
如果(CPU -> GPU -> CPU)双向传输会存在同步问题导致效率低下,
因此在设计代码时,尽量保证数据的单向传输(CPU -> GPU),避免计算同步问题。
CPU查找数据时,首先从Cache中查找,再从内存中查找,而Cache访问速度是内存访问的100倍。因此我们在处理数据时,尽可能使用连续数据。
- 充分利用硬件并行计算
- 避免冯诺依曼架构瓶颈
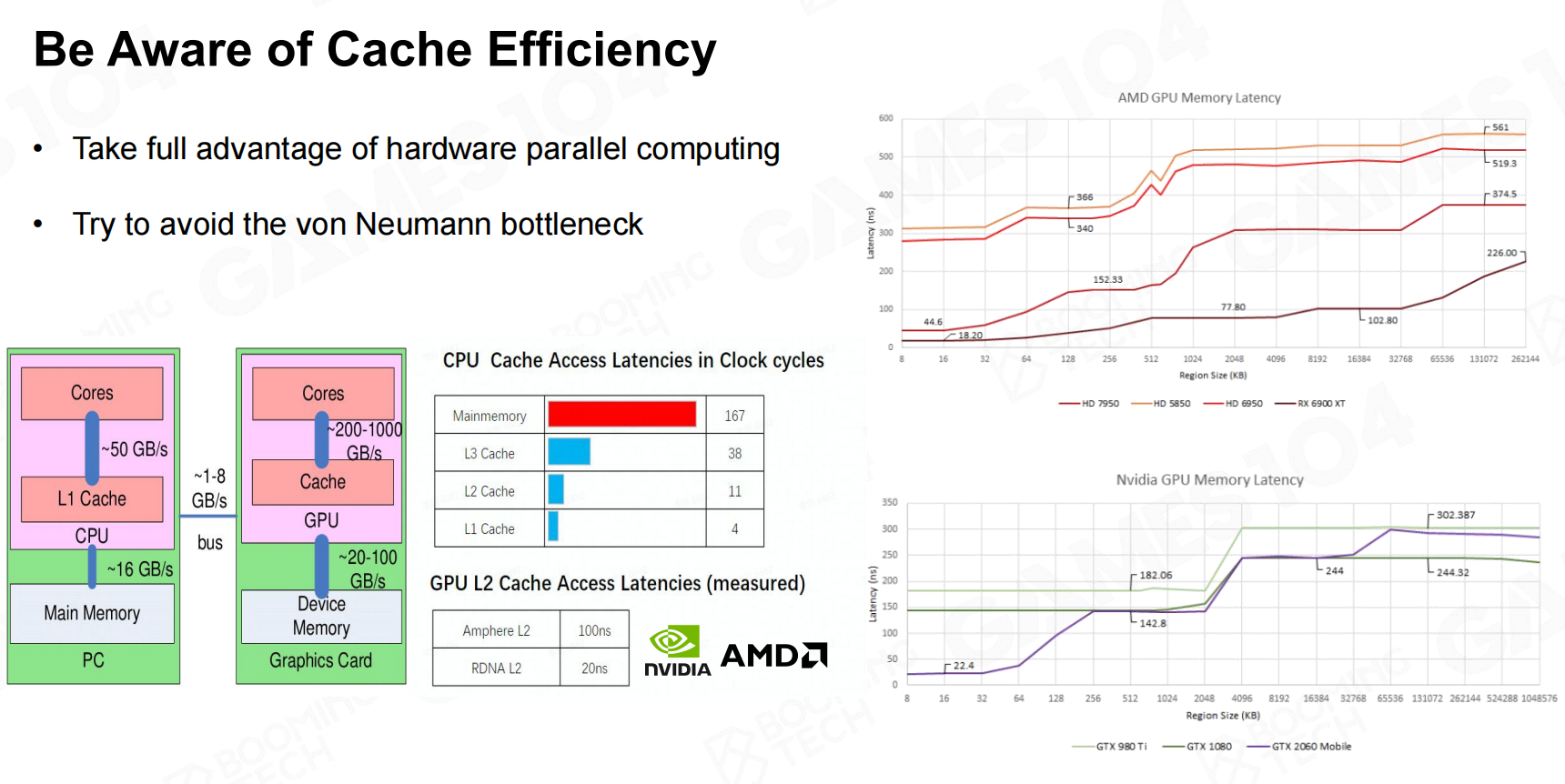 缓存
缓存
主机、PC、手机的GPU架构是不一样的,引擎的架构也是不一样的,引擎架构和硬件架构息息相关。
可渲染物体
Renderable组件中的数据是如何组织的呢?以一个士兵为例,首先很多网格组成对象的框架;
网格的质地各不相同,这就需要材质进行处理;材质中有不同的花纹,需要提供图片数据等。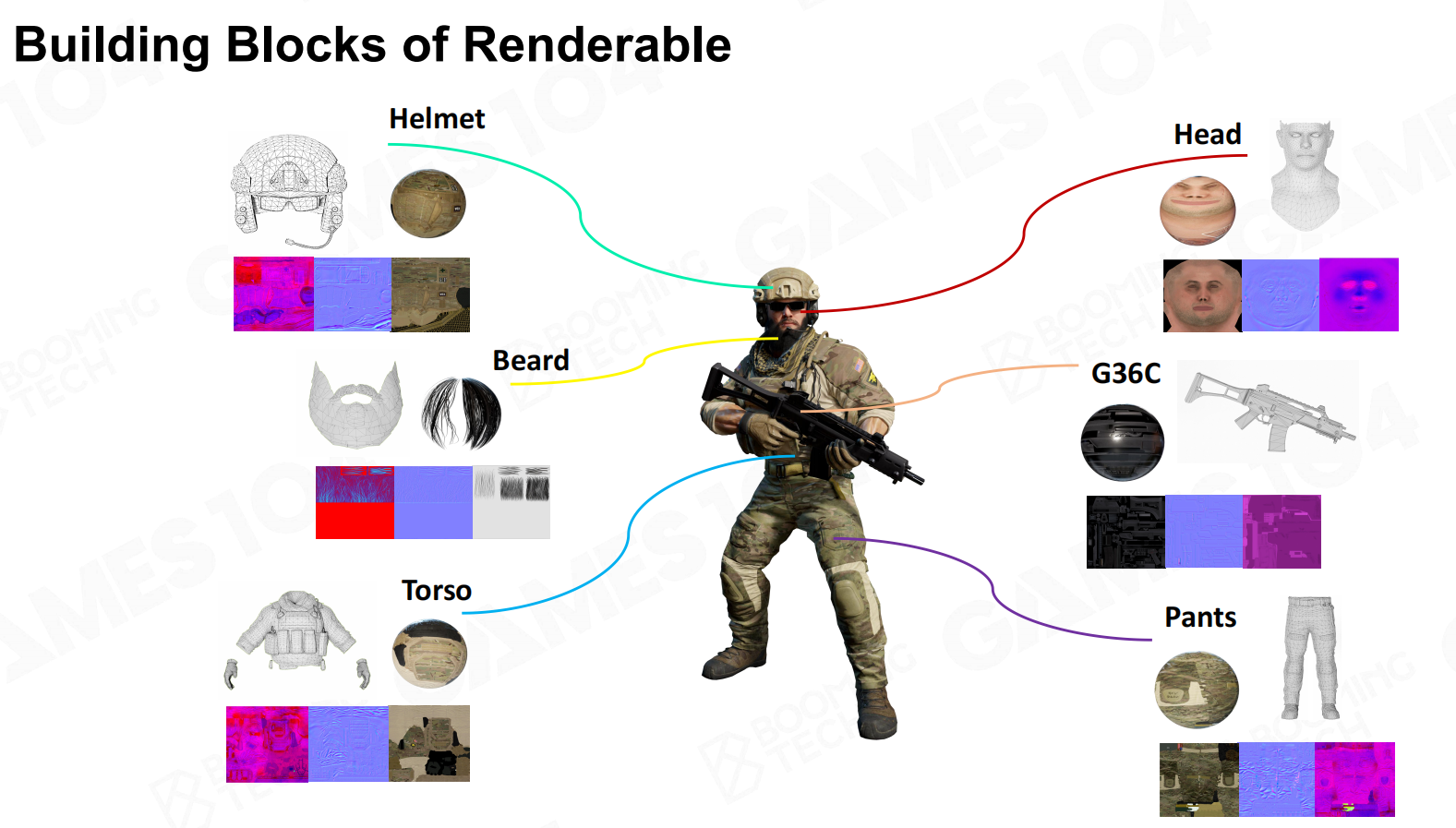 可渲染的物体块
可渲染的物体块
Mesh提供了单位的网格数据,网格是由一个个顶点数据组成的三角面的集合。
顶点数据涉及坐标、颜色、法线、切线……(不一定都有)有了顶点数据之后,最暴力的表示方法就是,每个三角面都有自生的原始数据,
这样的话N个三角面就有N*3个顶点数据。但我们仔细观察就会发现,这样的数据中有很多是重复的的(相邻三角面两个顶点数据相同)
在OpenGL中定义Mesh时就有VBO与VAO的概念,顶点数据为原始数据,通过index索引来组成三角面。
除了通过index引用的方式表示,还有Triangle Strip的表示方式:顶点列表中,连续三个顶点表示一个三角面,这样就省去了index数据,并且对缓存友好。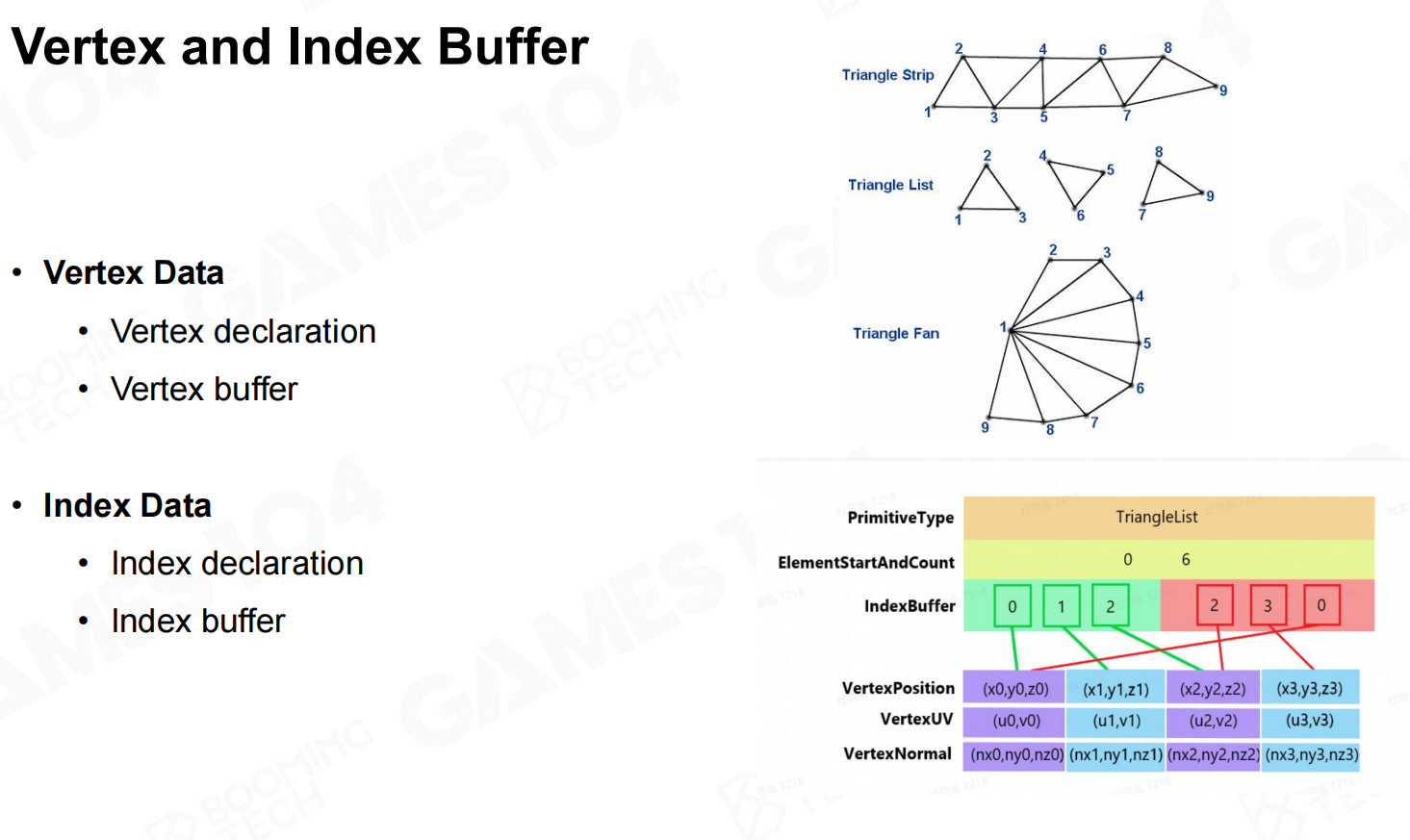 顶点和索引缓冲区
顶点和索引缓冲区
Rendering里面定义的Material只是视觉材质,也就是看起来像塑料,金属等,
而不是物理材质,像是其弹性,摩擦等是物理方面的,物理材质通常会单独的描述。 Material
Material
经过这么多年的发展,从图形学中经典的phong模型到现在的PBR模型,以及一些特殊的效果,比如半透明的效果,工业界中已经积累了很多的Material模型。
在表达材质时,Texture起到了很重要的作用,因为大多数时候我们判断一个物体的材质,第一时间是通过其Texture来判断的,而不是根据材质的参数。
比如这个生锈的铁球,我们是根据Roughness的Texture来区分哪些部分是光滑的哪些部分是生锈的,所以Texture也是Material重要的一种表达方式。 Texture
Texture
Shader代码也是Render able的关键数据:
- 拥有了Mesh,Material,Texture等,需要通过Shader才能将物体给绘制出来。
- Shader是Source code,但是在引擎中又会被当做数据进行处理。
 Shader
Shader
物体做好了,需要坐标转换从自身坐标系移到世界坐标系。
当确认相机的位置,需要物体投影到相机坐标系。
将正交投影或投影映射到屏幕的坐标系。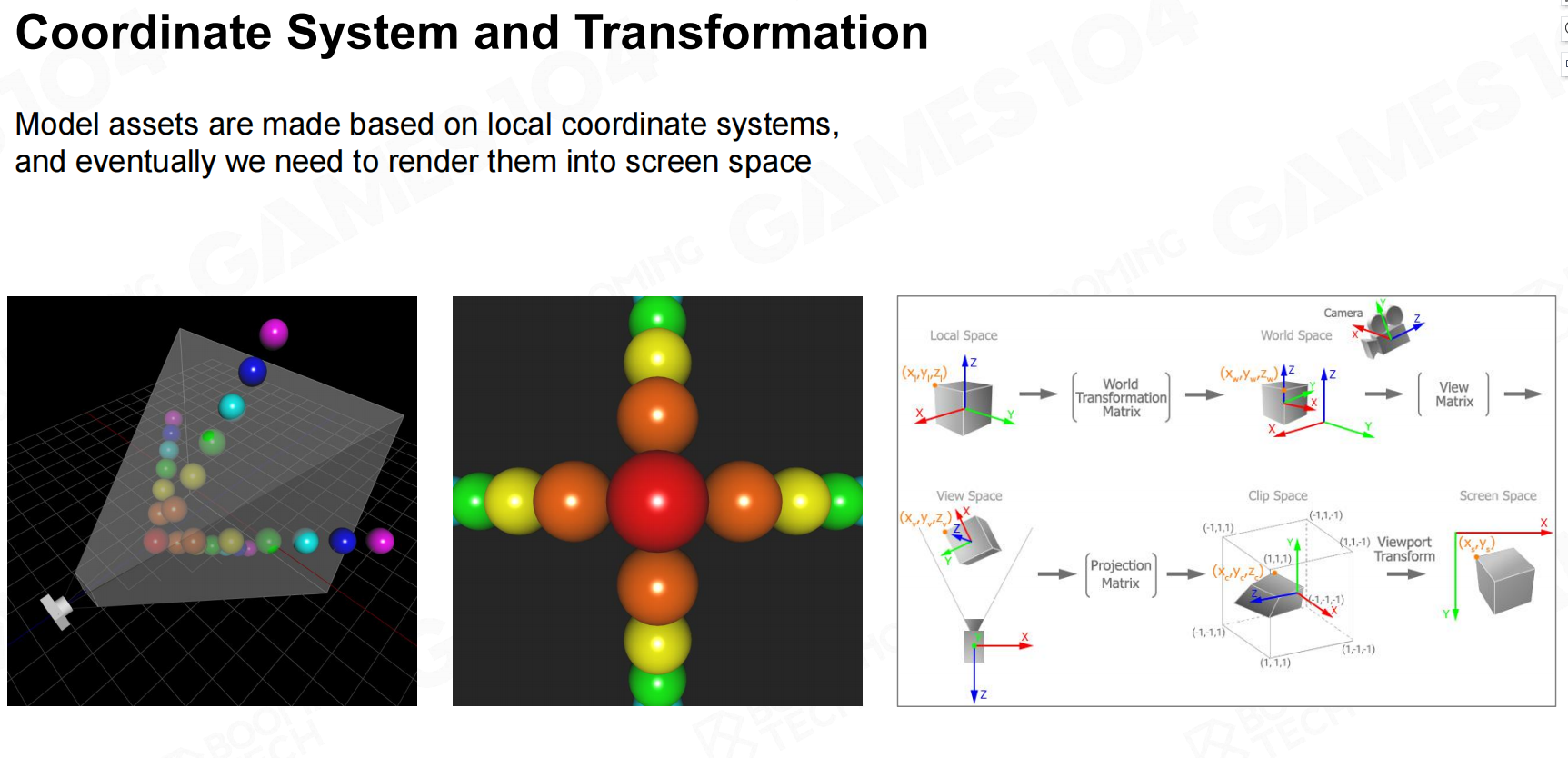 空间变换
空间变换
上述的为一般渲染处理流程,但对于一个复杂对象来说,部件的材质各不相同。
GPU作为一个状态机,只会保留最后Material所提交的状态进行渲染,那么就不能得到正确的效果,如图右边,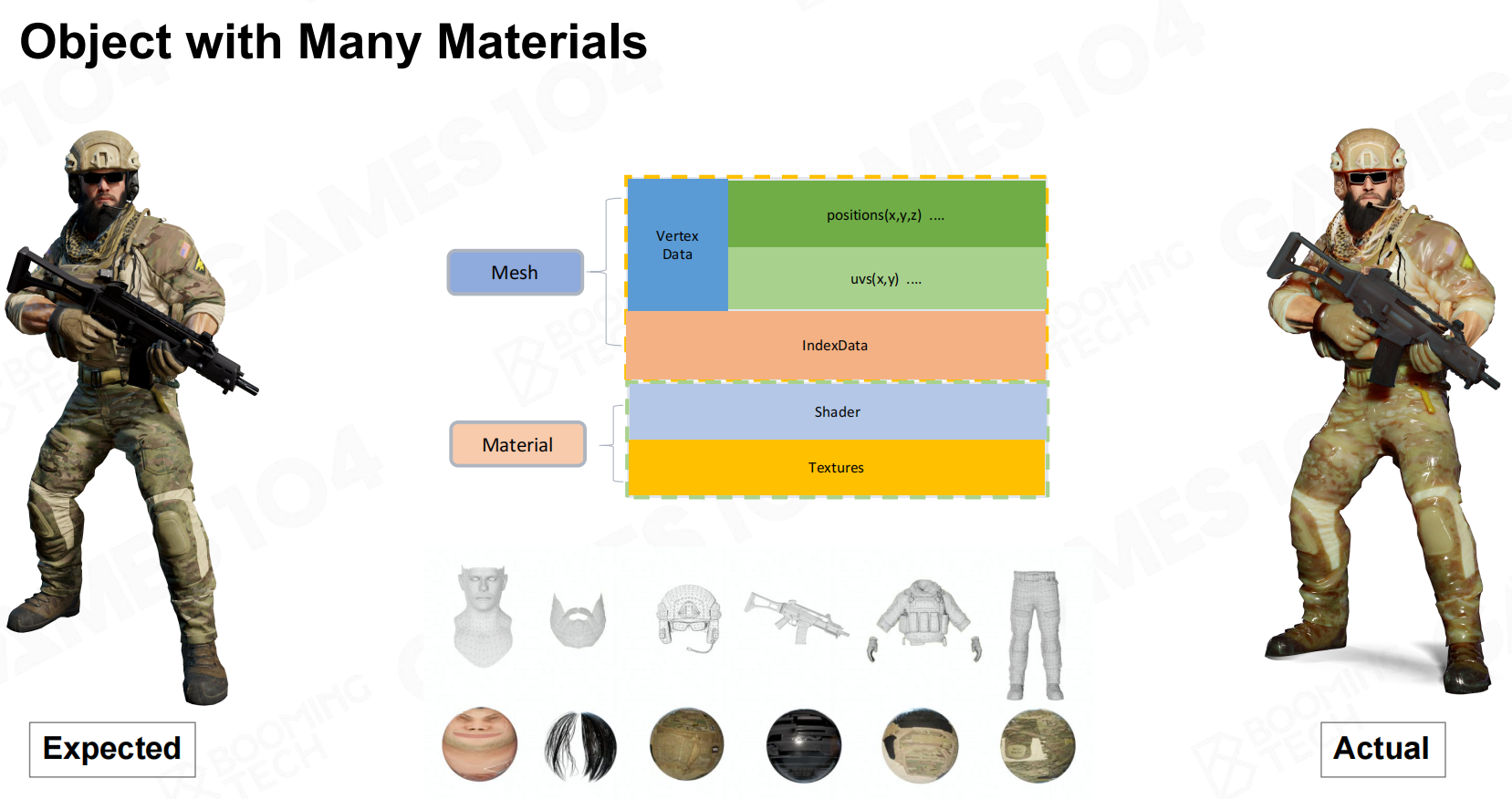 根据数据与Shader渲染
根据数据与Shader渲染
因此就需要引入SubMesh的概念: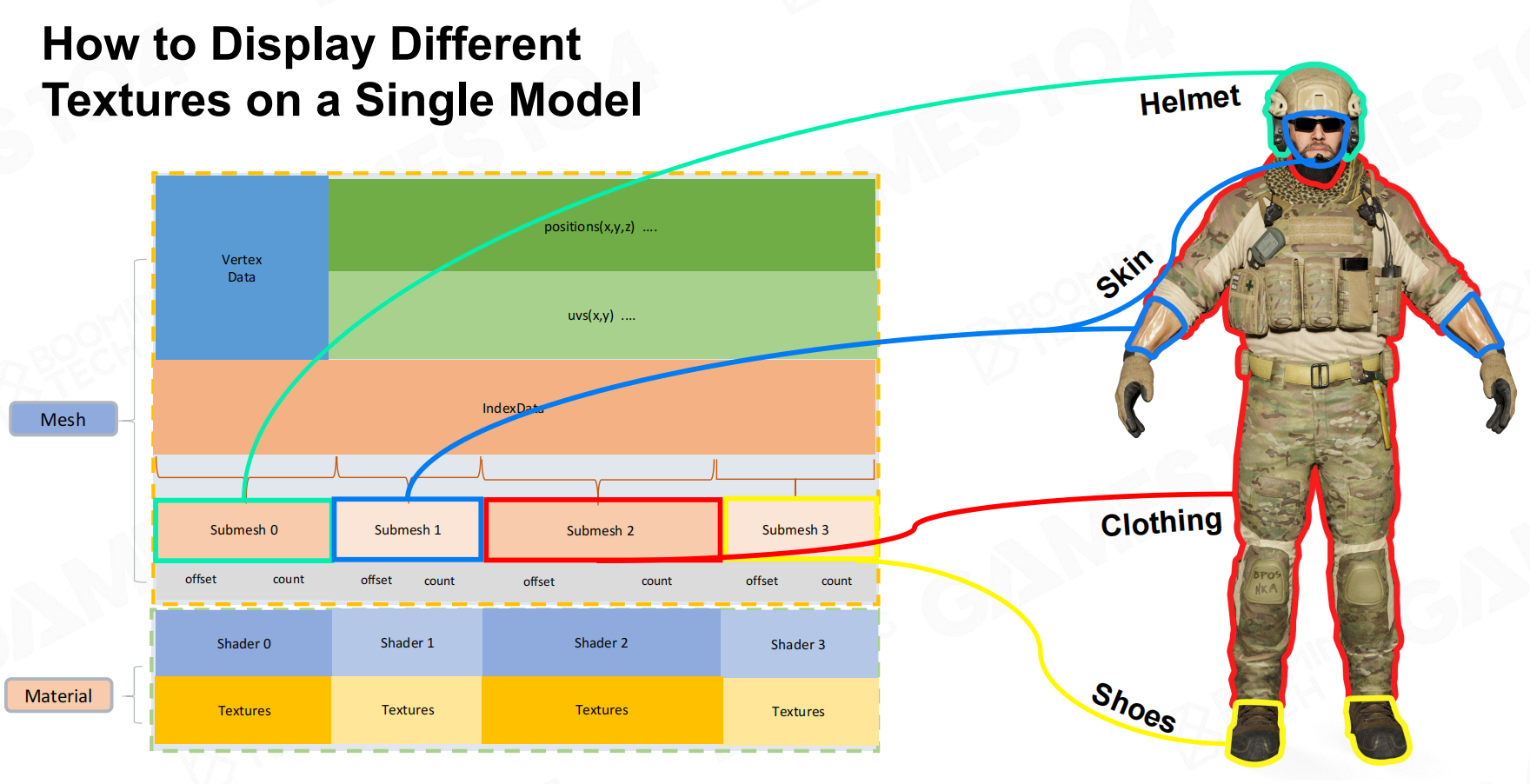 Submesh结构
Submesh结构
对于存在多个材质的对象,我们会对网格进行切分(通过offset、count确定index)为submesh,对应各自的材质,一个完整的复杂对象渲染就处理完成了。
但如果我们需要绘制大量这样的复杂单位,如果每个单位都独立存储一份完整的渲染数据,这样的开销太过巨大。
这些单位的材质、Mesh、纹理都有相同部分,因此较好的数据组织方式是对渲染资源数据创建资源池。
当我们在游戏中创建不同的GameObject,可以看做资源在场景中的实例化。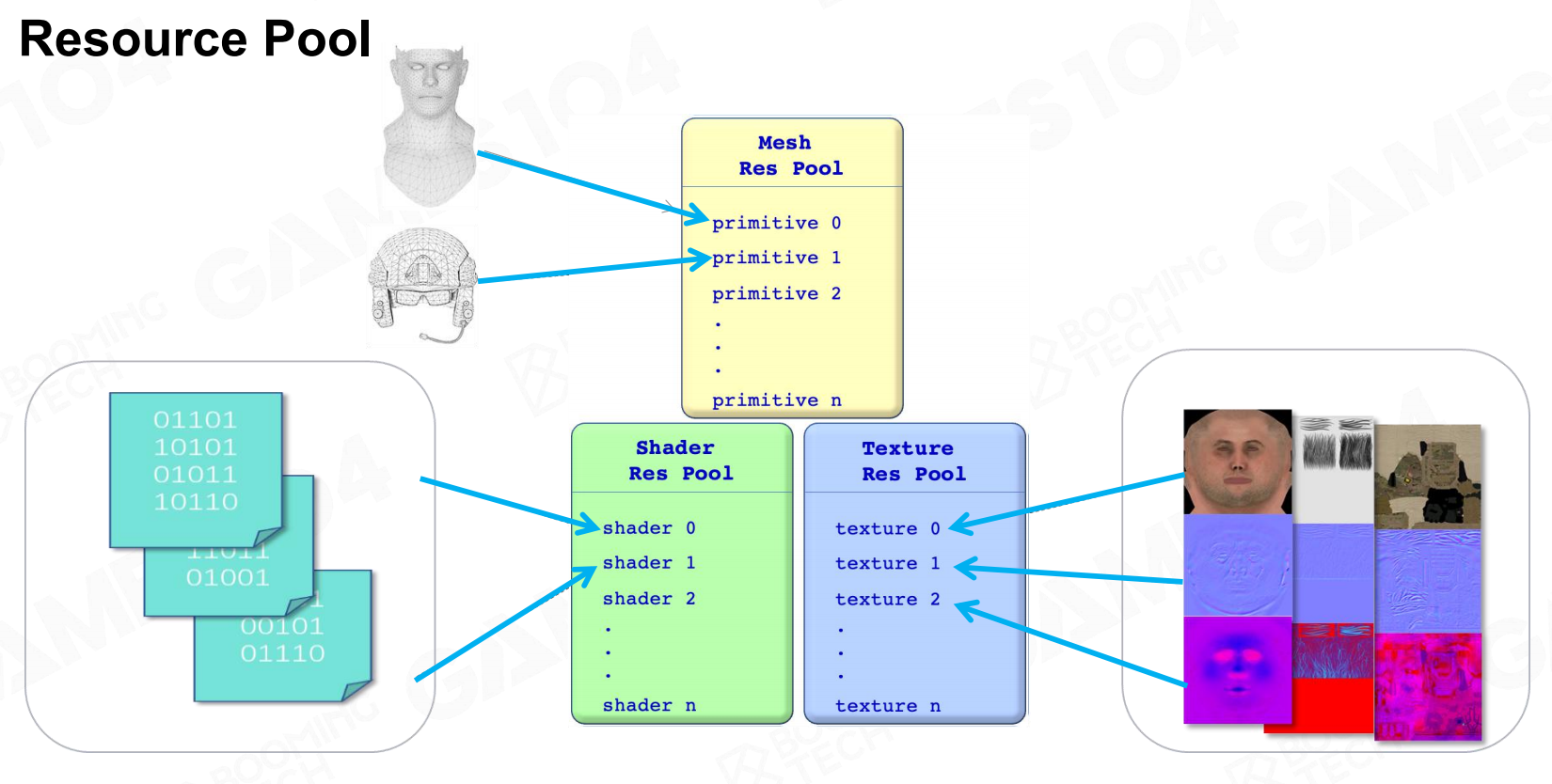 资源池
资源池
渲染的整体分为三个步骤:
- CPU提交渲染数据
- GPU设置渲染状态
- GPU渲染
对于相同材质的对象来说,每次都处理三个流程是极为耗时的,我们可以为材质相同的对象跳过步骤(2)。
这也是现代图形渲染API的设计思路:根据材质进行Submesh渲染。Unity中的SRP Batcher类似于这一概念。 按材质排序
按材质排序
除了简化渲染状态设置,我们还可以对数据的提交进行优化:对于完全相同的物体,只是在场景中的位置不同。
就可以将这一类对象的渲染数据一起提交到GPU,减少数据提交次数。Unity中的GPU Instance类似于这一概念 GPU批处理渲染
GPU批处理渲染
可见性裁剪
在知道了如何绘制场景GameObject了后,我们需要思考一些问题:我们要绘制哪些物体?
最暴力的方法是所有对象都绘制一遍,但显然在大世界的游戏中是不行的。
那对于硬件的负荷也太大了,因此需要Visibility Culling,它是引擎的渲染模块中的一个基础底层系统。
Bound Volume(包围盒)
通常我们会根据Camera的可视范围(视锥体、长方体)作为单位是否可见的判断依据,但单位的形状千奇百怪,
如何能够将这些Mesh与可视范围进行检测呢?这就需要对物体范围进行简化:包围盒(Bound),规则物体的相交是相对便于计算的。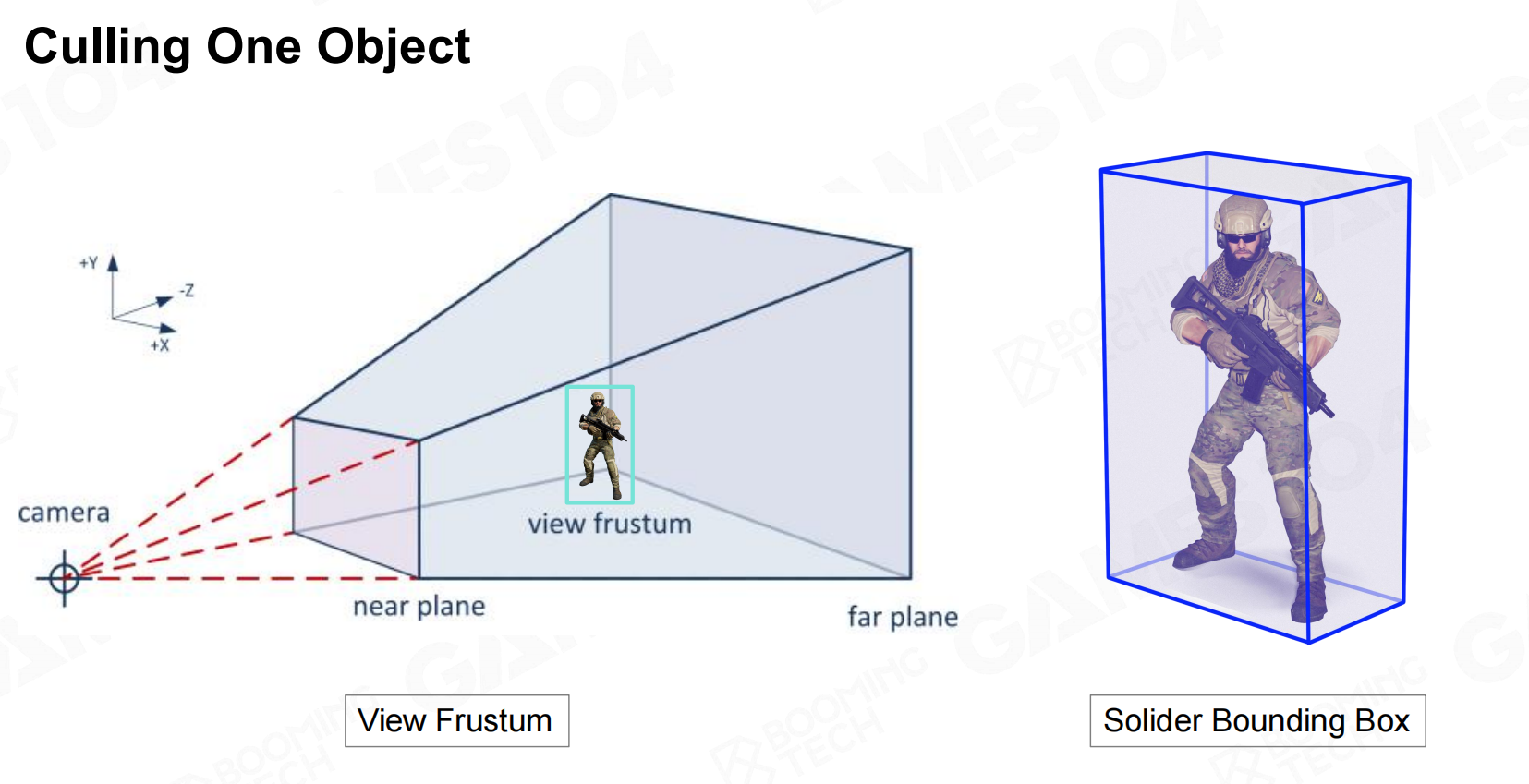 包围盒
包围盒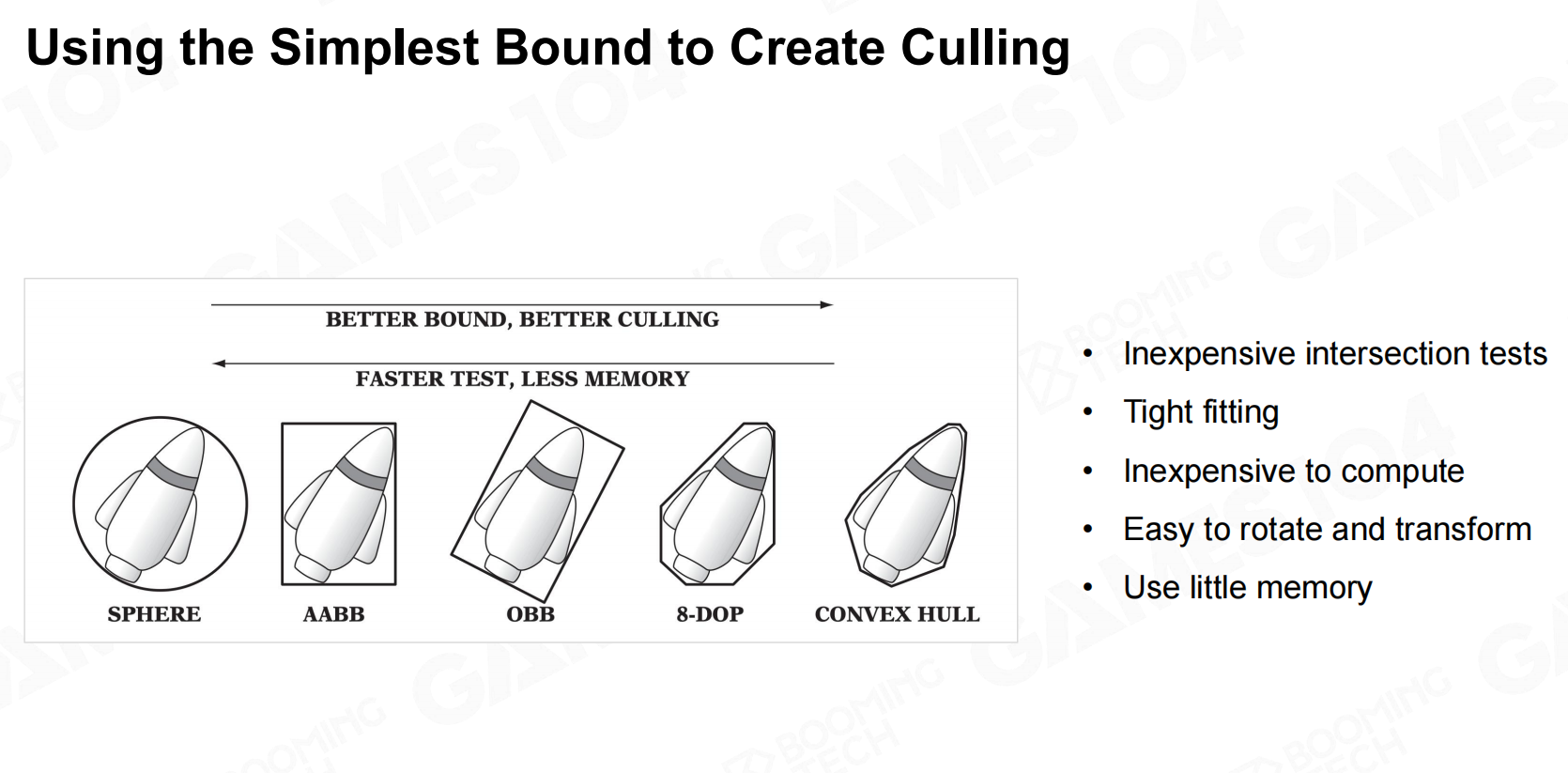 包围盒类型
包围盒类型
场景管理
有了包围盒后我们确实可以去判断是否被culling掉,最简单的方法就是将所有包围盒都进行判断,
但这样的话面对拥有数量众多GameObject的游戏效率是十分低的,因此我们可以通过对场景中的GameObject进行划分管理,
比如经典的四叉树划分,BVH划分等,预先剔除摄像机覆盖范围外的对象。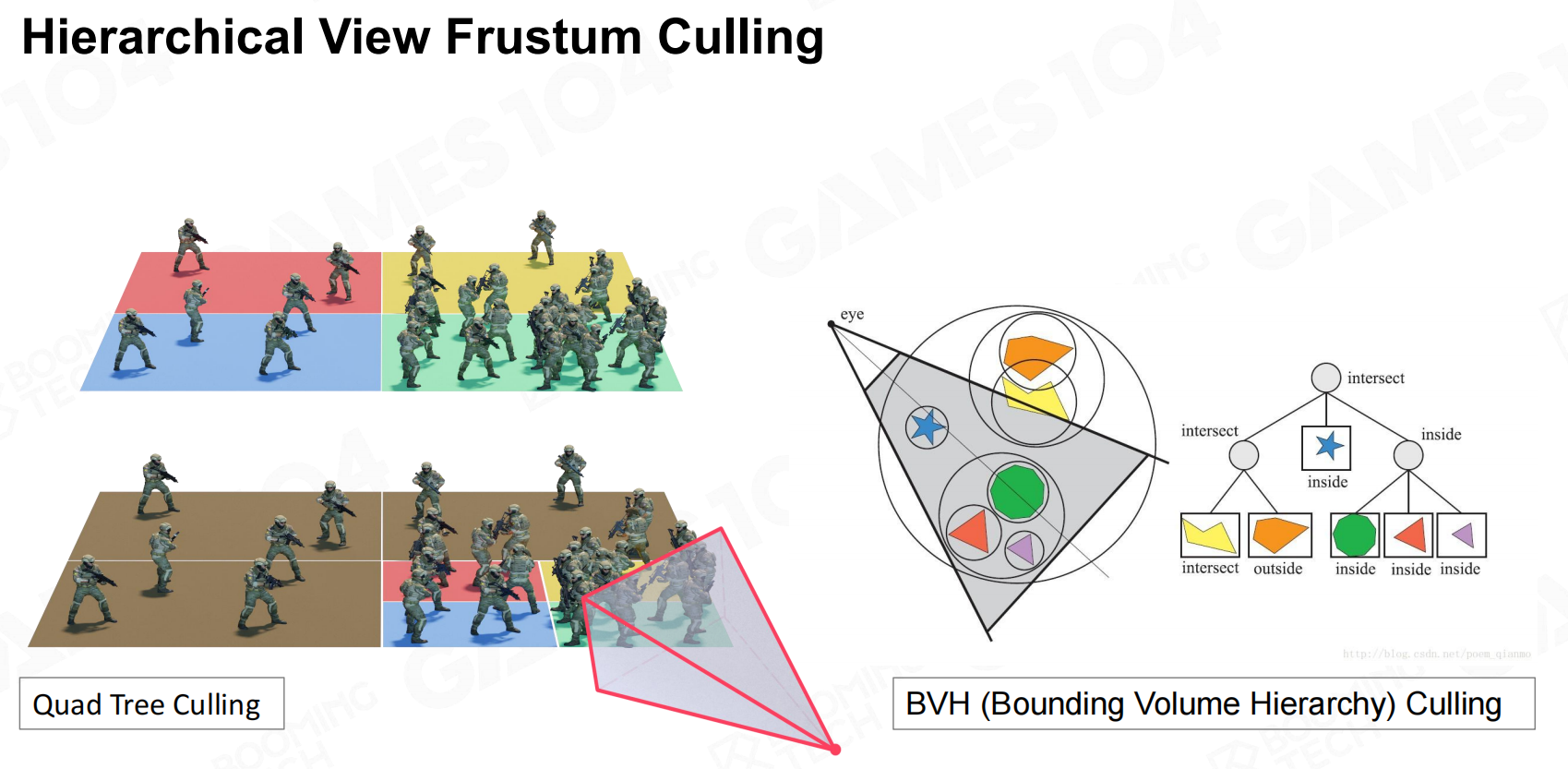 层次视图
层次视图
以BVH为例,把包围盒们以树状结构管理,层次包围盒树(BVH树)是一棵多叉树,用来存储包围盒形状。
它的根节点代表一个最大的包围盒,其多个子节点则代表多个子包围盒。
因此当frustum判断这个包围盒在内的话,进入精细化分的子节点继续判断。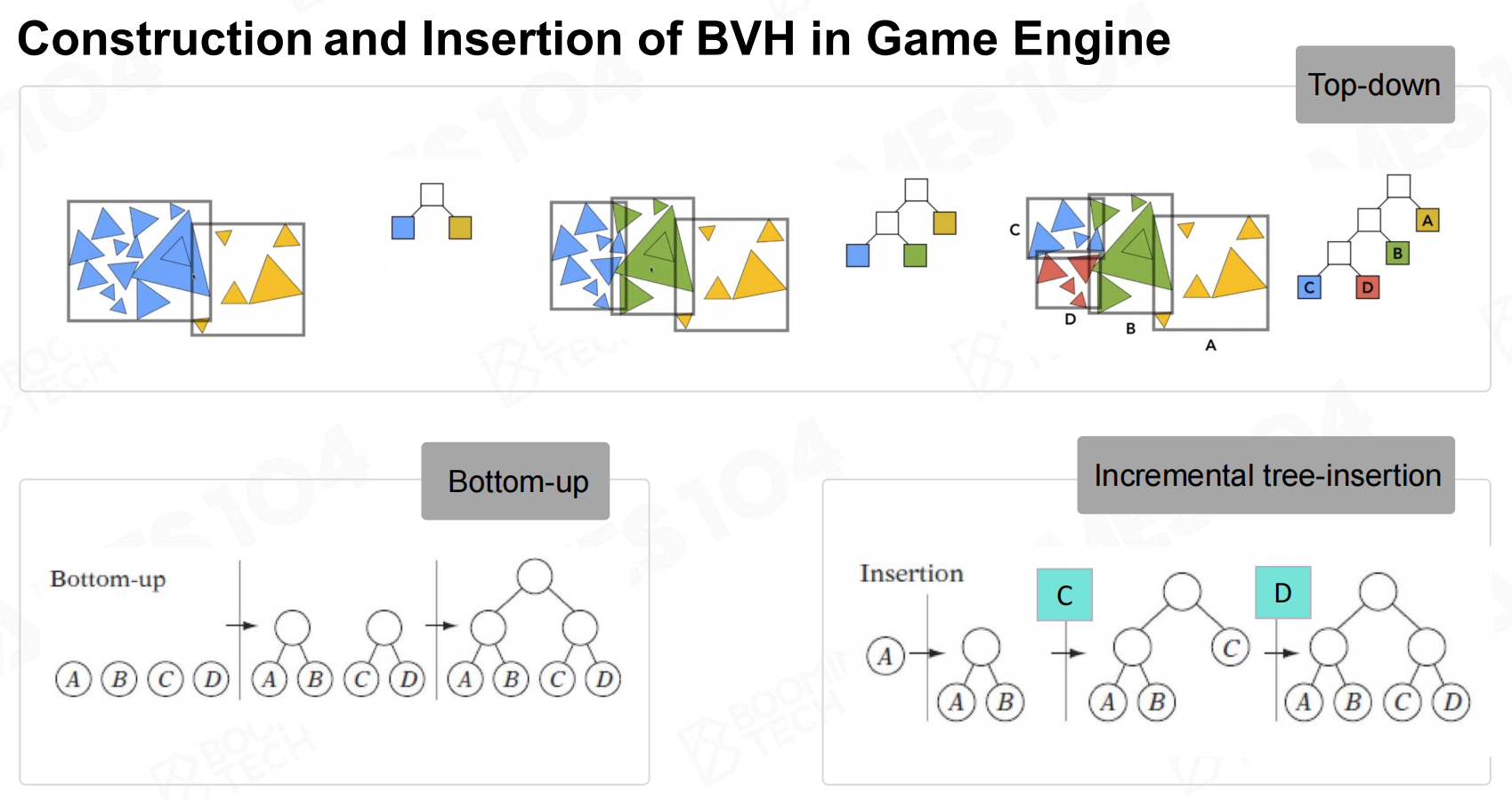 游戏引擎中BVH的构建与插入
游戏引擎中BVH的构建与插入
BVH算法在工业界广泛使用,因为现代游戏场景内动的物体比较多,因此当GO移动后也就是节点变动,
我们需要重新构建树状结构,此时要考虑重新构建的成本一定要很低,而BVH恰好在此有很多优势,因此BVH适用于开阔动态场景。
接下来我们来学习PVS(potential visibility set),它的算法思想是很有用的:
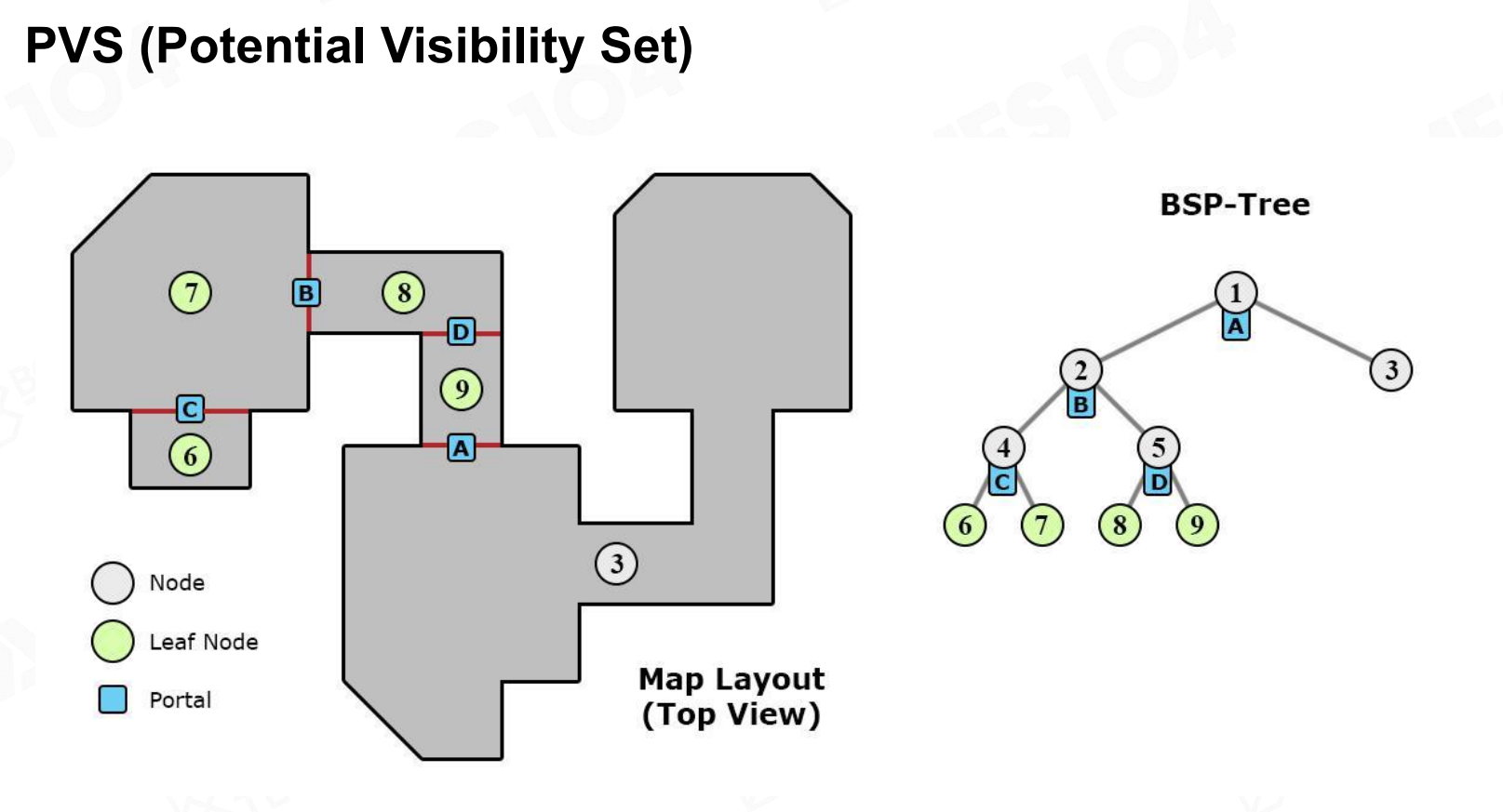 PVS
PVS
我们将一个大的游戏场景划分为一系列的子场景,如图,相邻的子场景之间设置portal(也就是真实世界中的门),
当你站在一个子场景时,通过portal(门或窗)只能看见有限的子场景,如下图,
站在7号子场景可以看到6,1,2,3四个子场景,因此在7号子场景时只需要渲染,6,1,2,3四个子场景的所有东西。 连接处和PVS数据
连接处和PVS数据
 游戏中PSV用法
游戏中PSV用法
随着硬件的不断发展,现如今GPU的批处理速度远远快于CPU,通过GPU进行Culling操作,
在绘制对象时,靠前的物体会挡住靠后的物体,进行这一判断就需要Early-Z(z-Buffer)。
通常在进行真正绘制之前,Camera会对空间对象生成一张深度图(z-Buffer)。
在之后绘制对象时,就可以判断像素的深度是否符合要求,以此来判断是否进行绘制。
利用了GPU高效的并行化能力加上廉价的成本形成一群遮挡物的深度图,然后通过比较从而节省掉不必要的计算过程,对于大型场景很有用。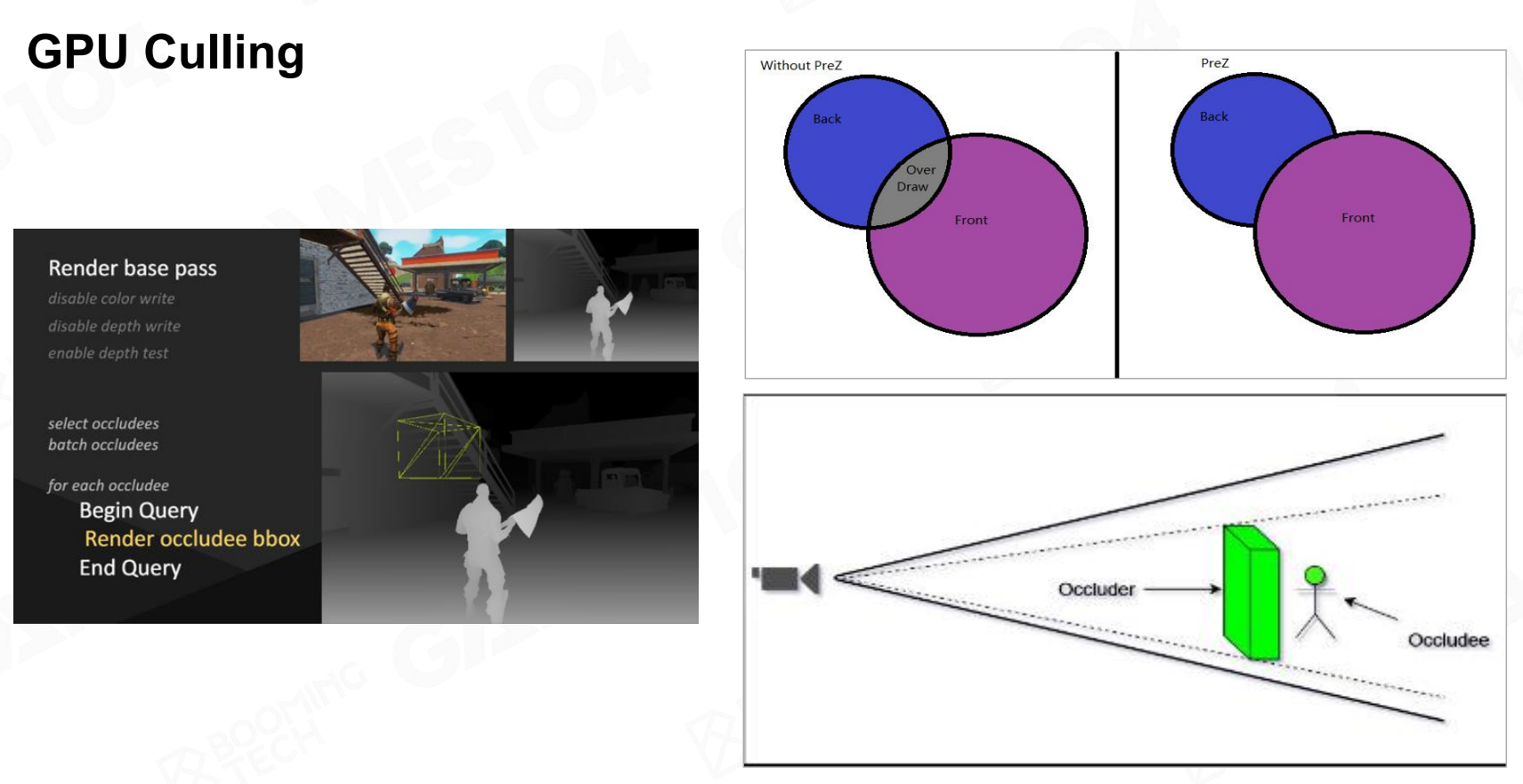 GPU裁剪
GPU裁剪
贴图压缩(纹理压缩)
我们日常使用的图片压缩格式(如PNG、JPEG等),有很好的压缩或显示效果,但通常无法满足游戏引擎的需求:快速随机访问像素。
在游戏引擎中通常采用block思想:将纹理划分为多个小块,然后进行压缩。
以DXTC格式举例,对于每个划分的小块,取得其中最亮和最暗的像素点,其余部分通过差值系数的记录数据。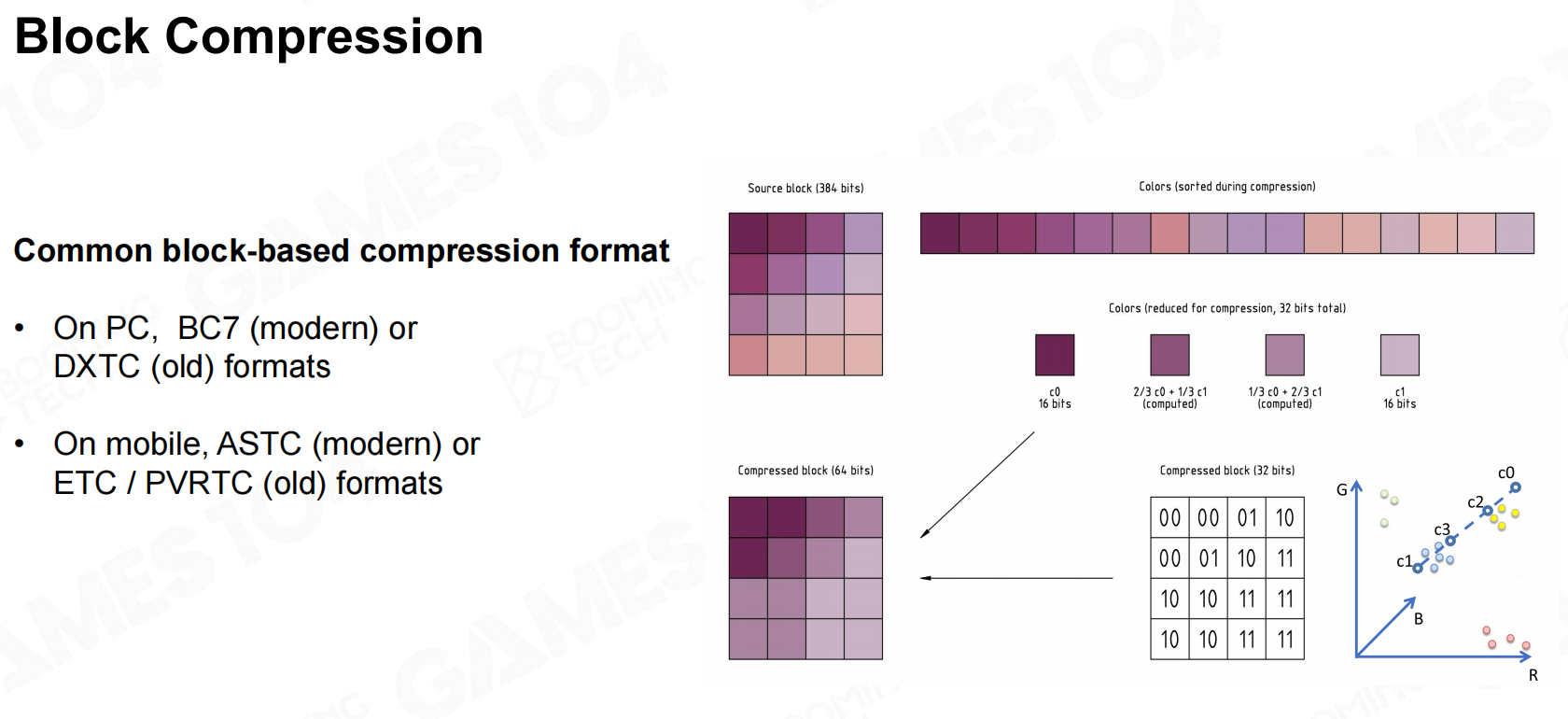 块压缩
块压缩
模型工具
 多边形建模
多边形建模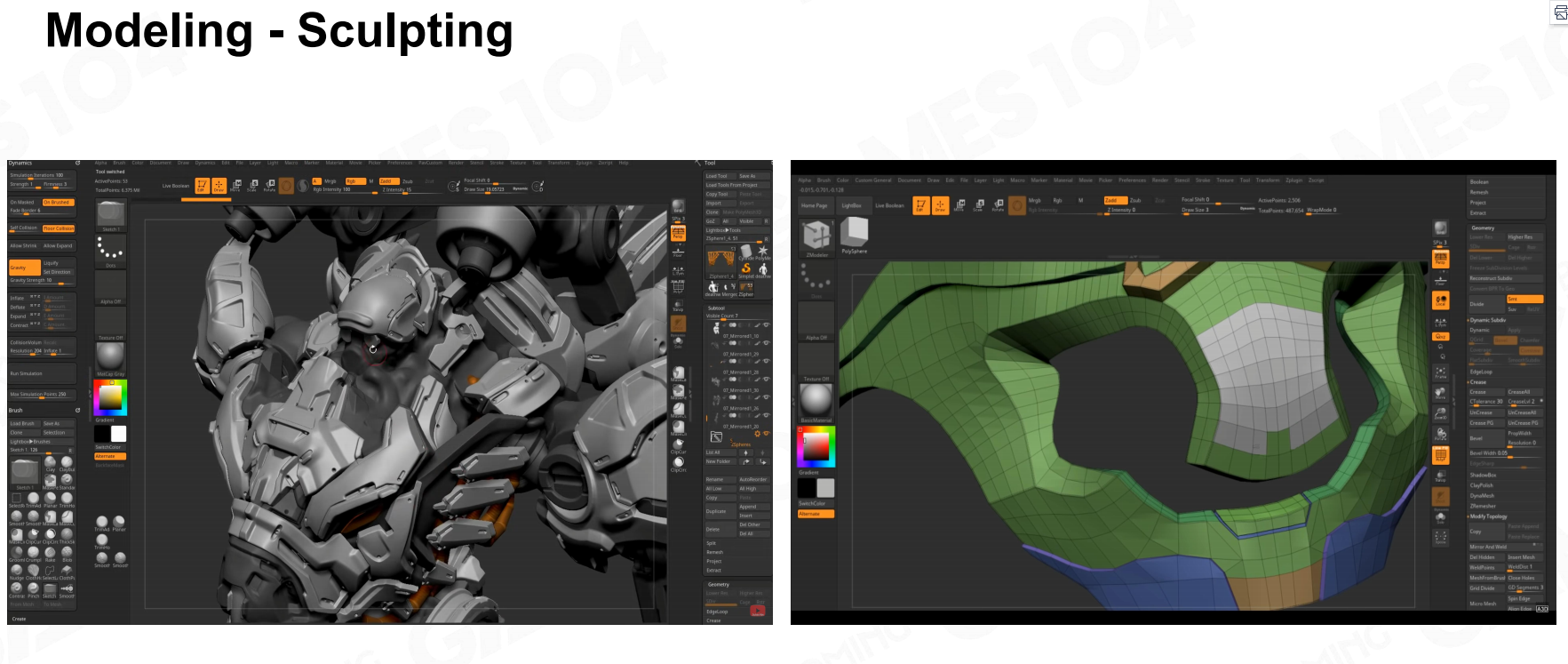 雕刻
雕刻 扫描
扫描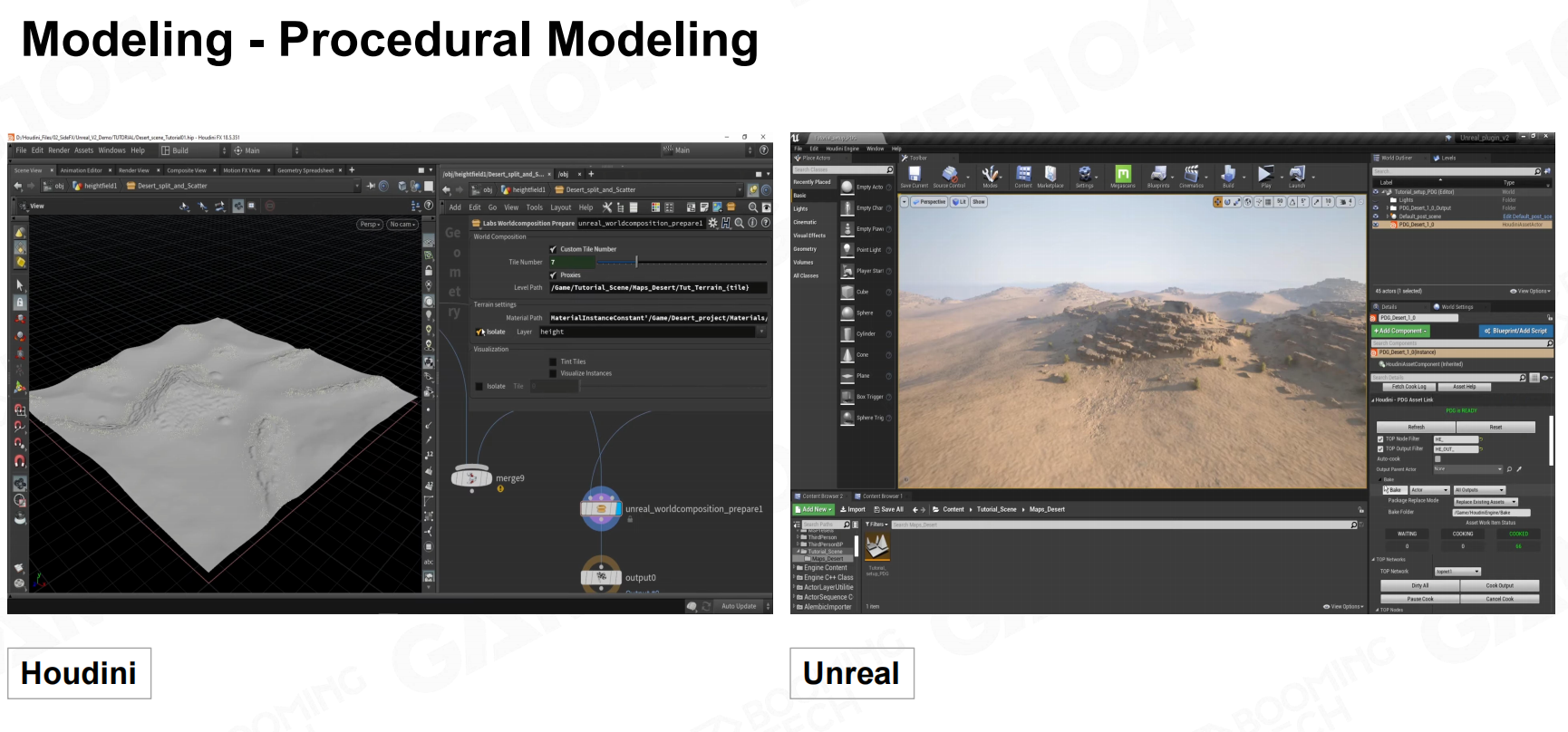 算法生成
算法生成 建模方式对比
建模方式对比
新的模型管线
游戏和影视有很大的重合部分,但由于游戏的实时渲染以及硬件存储要求,通常一个模型的面片数不会超过1W,
而影视级的模型通常是千万级的。 想要在游戏中实现影视级效果,那就得上点手段了。
2015年《刺客信条:大革命》提出了Mesh Cluster Rendering概念。其核心思想是将模型分成多个Cluster(32\64面片),
根据这些Cluster与摄像机的远近来展示不同的细节。这样处理的好处在于:
- 现在GPU可以根据实时数据,动态生成几何细节(曲面细分Tessellation)
- 以相同的Cluster结构来并行处理时,能够有效利用GPU
- 可以对模型进行Cluster剔除
 基于网格的管道
基于网格的管道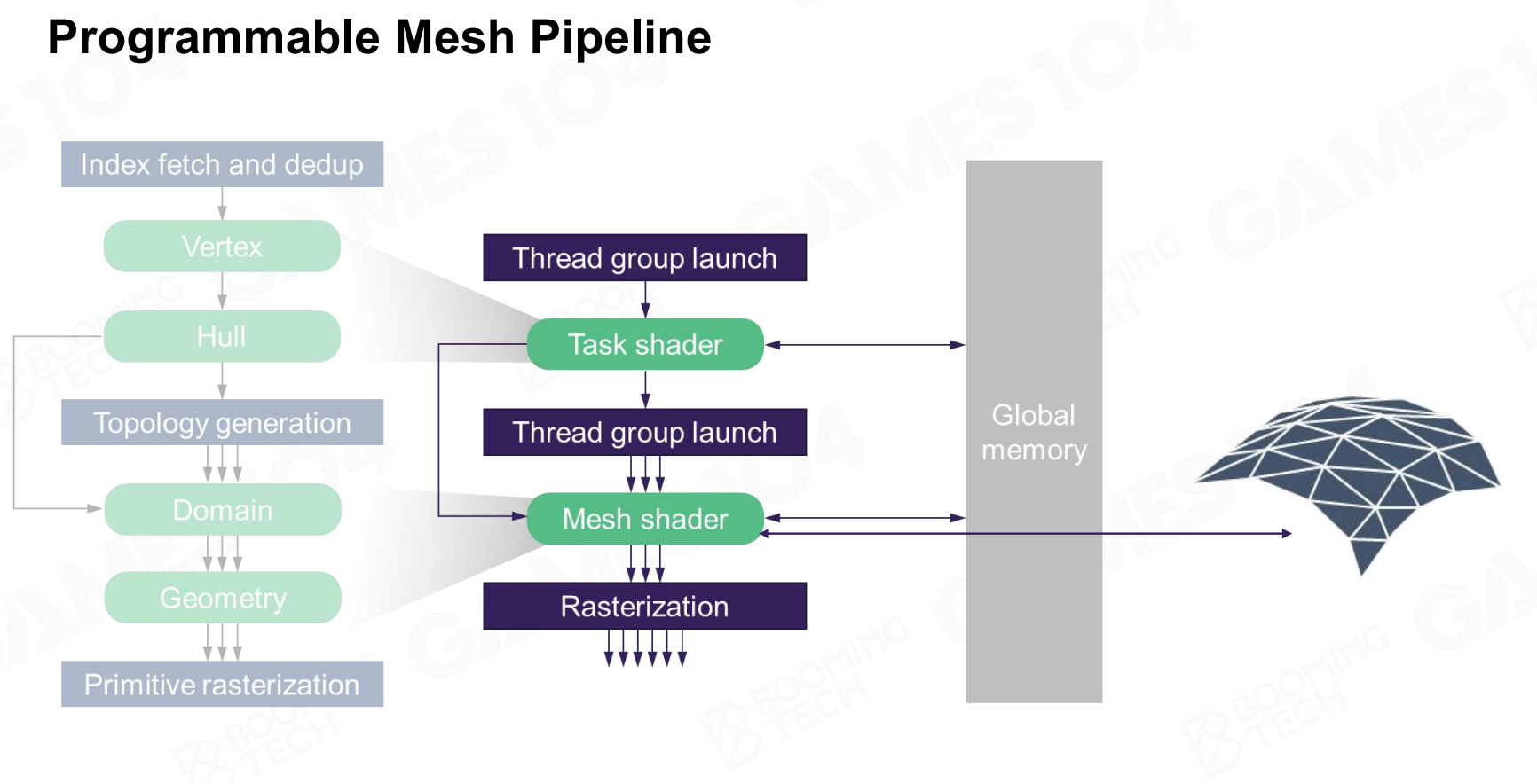 可编程的网格管道
可编程的网格管道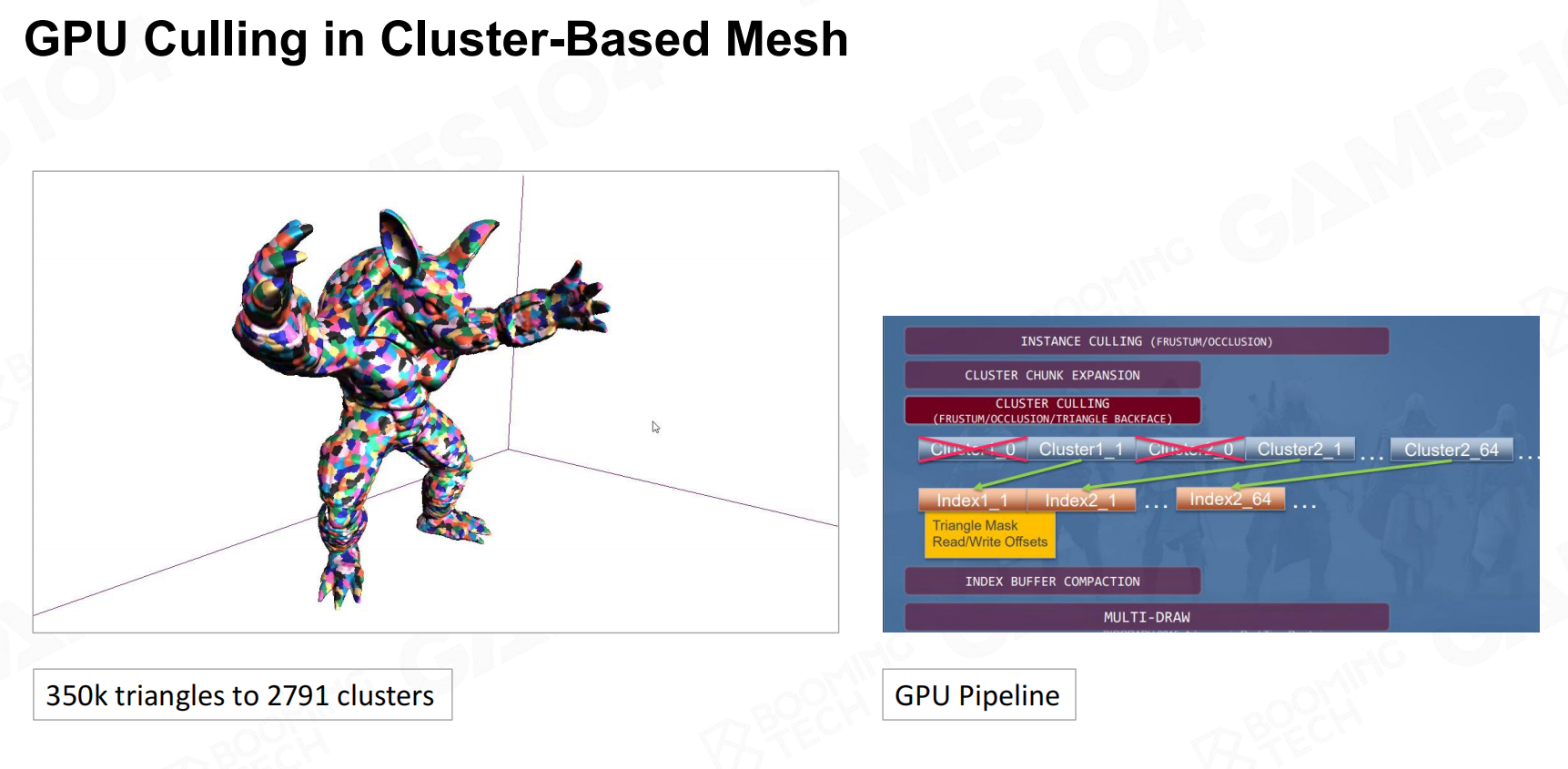 基于集群的网格中的GPU裁剪
基于集群的网格中的GPU裁剪
用一个基于数据可以凭空生成几何,并且可以根据cluster与相机间的距离选择不同的精度的算法。这样GPU处理的都是大小一致的几何体,并行处理使得高效。
总结
- 游戏引擎的Rendering模块是一个工程科学,深度依赖于现代硬件架构和编程者对现代硬件架构的理解
- 游戏引擎渲染的核心问题是Mesh、Material、Texture等数据间的关系,比如Mesh和Submesh就是一个很好的解决方案
- 游戏引擎渲染在绘制对象时,要尽可能减少处理内容,从而可以提升性能,因此Visibility Culling非常重要
- 现代GPU的处理效率越来越高,可以将CPU中的并行计算转移到GPU中
引用
- 本文作者:樱白 - Cherry White
- 本文链接:https://cherry-white.github.io/posts/3d4c0b0.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!
☕ 如果这篇文章对你有帮助
欢迎请我喝杯咖啡,支持持续创作