
GPU 工作原理详解:SM、Warp 调度与 Tensor Core 矩阵运算
为什么GPU计算是可行的(我的数据在哪里)
Flops(每秒钟浮点运算次数)跟机器的算力有关
在购买机器的时候 nobody cares about flops 或者说 almost nobody really cares about flops
CPU大约每秒能进行2万次的双精度(FP64)运算。
内存将数据传送到CPU,每秒传输大约200G字节,也就是每秒25G的FP64数值。
因为每个FP64是8字节,所以内存每秒可以提供250亿个FP64值,CPU每秒能处理2万亿个FP64数据
每秒内存需要同时传输80次数据给CPU才能让CPU满载 计算强度
计算强度
不同CPU的计算强度都差不多,Flops处理能力越强就会有更大的内存带宽来平衡它,
当Flops的速度比内存带宽的速度快,计算强度就会上升 CPU vs GPU
CPU vs GPU
因为Flops被内存带宽完全的限制住了,所以每次加载100个程序是十分困难的,
这还不是全部,我们更关心的是延迟(Latency)而不是内存带宽(Memory bandwidth) Because
Because
通过方程aX + Y = Z,分别加载X和Y等待延迟读取到数据后进行计算得到结果,这就是核心的指令流水线 数乘(daxpy)
数乘(daxpy)
在一个时钟周期内光传播的距离只有10厘米,所以时钟频率太快而光走不了多远。
电流在硅中的传播速度只有光的五分之一(6万公里/秒),
一个时钟周期内,电流的移动只有20毫米。
内存到CPU的路程需要有5-7个时钟周期的延迟,因为物理上的原因,
在内存中提取数据时需要5-10个时钟周期才能放回到CPU。 内存到CPU距离
内存到CPU距离
CPU很快,内存很慢。所以整体效率很低 利用率
利用率
虽然0.14%的利用率很低,但是已经算很好了,这就是程序受到了延迟限制(latency bound)的影响,
它发生次数远比我们认为的要多。延迟限制是内存限制类别的一个子集,
它主要发生在不需要立即从内存中检索太多的数据,但是在内存层次结构的上层,
必须等待很长时间才能将数据发送到处理器的情况。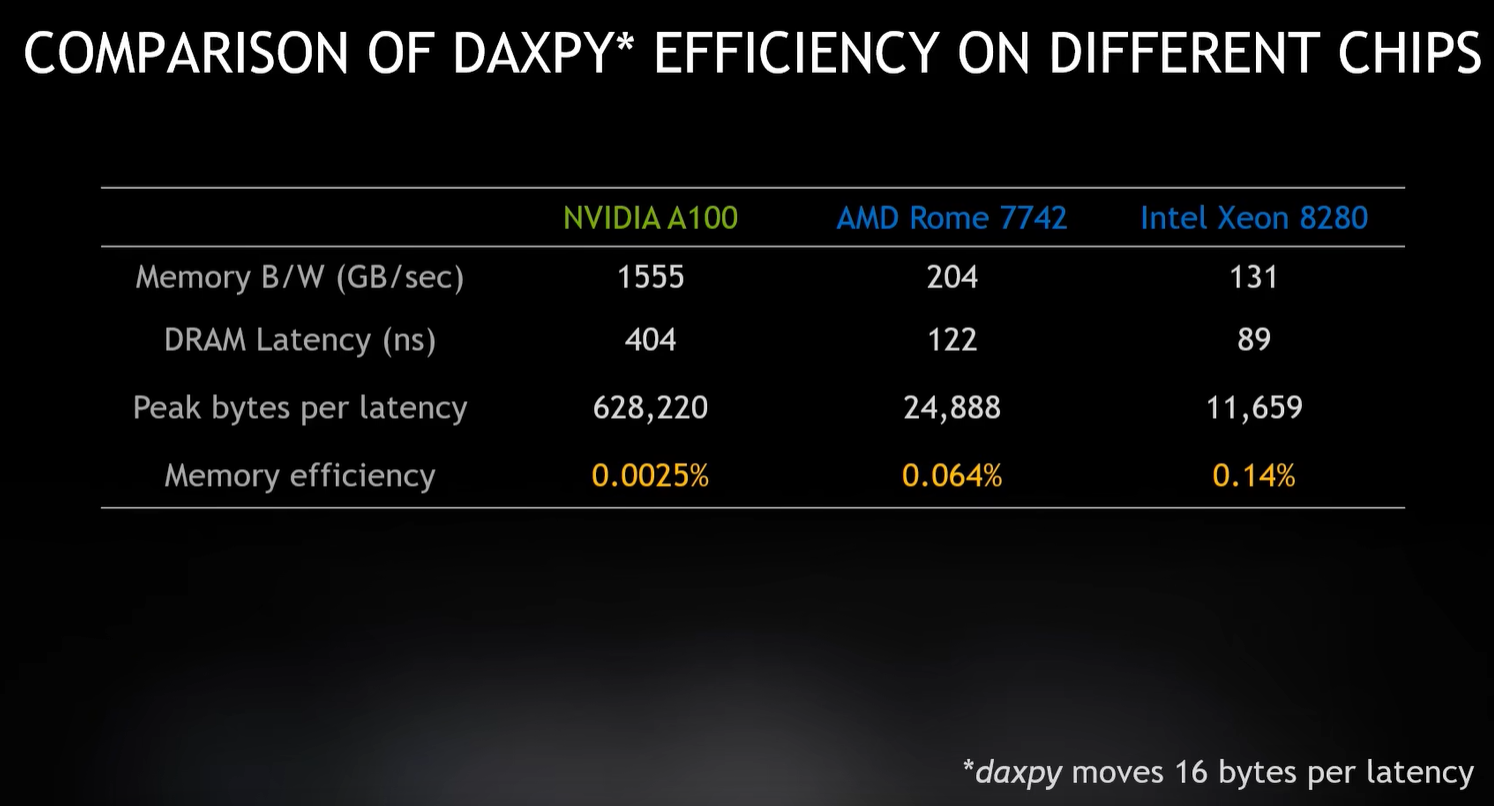 利用率对比
利用率对比
GPU要充分利用内存,根据前面的数据 11659/16=729 一次需要运行729次迭代才能让内存保持满负荷运转 GPU利用率
GPU利用率
Loop Unrolling(循环展开)
编译器有一种优化器叫做Loop Unrolling(循环展开)
- 循环展开可以由程序员完成,也可由编译器自动优化完成。
- 循环展开是通过将循环体代码复制多次实现
- 循环展开能够增大指令调度的空间,减少循环分支指令的开销
- 循环展开可以更好的实现数据预取技术
循环展开发现只有一个进程和延迟时间,通过发出back to back all at once信号加载 x 和 y
一次循环中可以做很多次,它受到硬件能跟踪多少操作请求的限制,它可以在指令流水线中缓存指令,
但是它必须追踪每一个请求。虽然我只有一个进程,但循环展开之后有729个迭代请求也没问题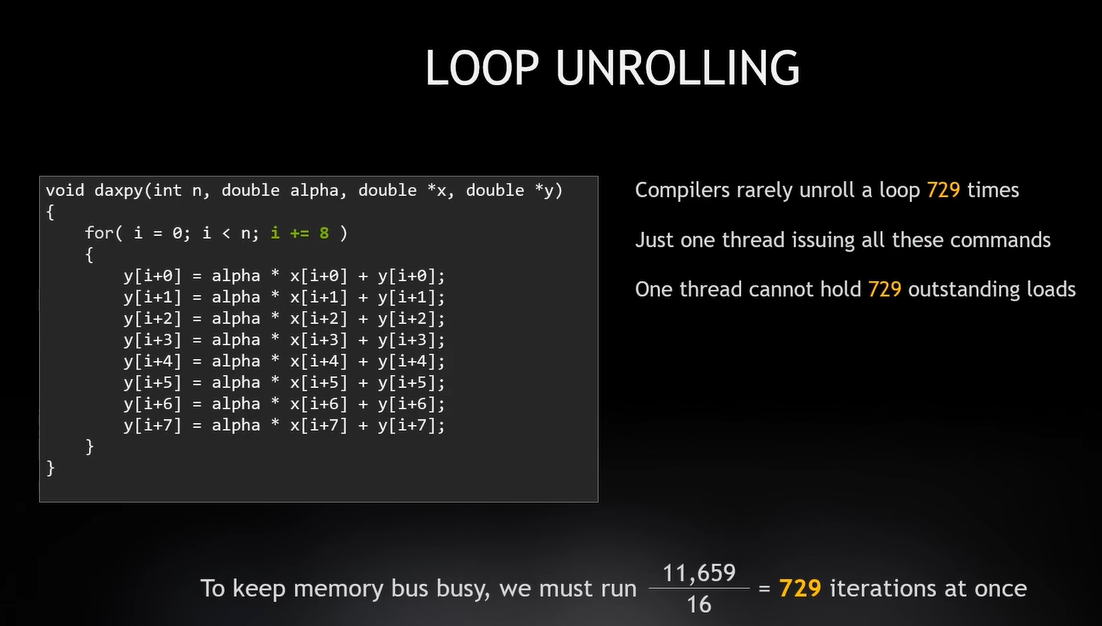 GPU并行计算
GPU并行计算
并行性(parallelism)比并发性(concurrency)强,对吗?
- 并行的关键是你有同时处理多个任务的能力(每个线程同时执行一个操作,但是硬件可以处理许多线程)
- 并发的关键是你有处理多个任务的能力,不一定要同时
GPU和CPU对比
我们可以通过循环展开多线程操作提高硬件的使用效率,同样也允许我使用较少的线程。
GPU比CPU不同的是有更高的延迟和更多的线程。
如果有一些线程正在等待内存,那么还有更多的线程等待激活,GPU就是所谓的吞吐机。
GPU的设计师将所有资源投入到更多线程中而不是减少延迟。
CPU是一台延迟机,CPU的期望是一个线程基本完成所有的工作,
将一个线程从一个切换到另一个是非常昂贵的,就像上下文切换一样。
所以你只需要足够的线程就可以解决延迟的问题,而CPU则是把所有的资源都投入到减少延迟上了。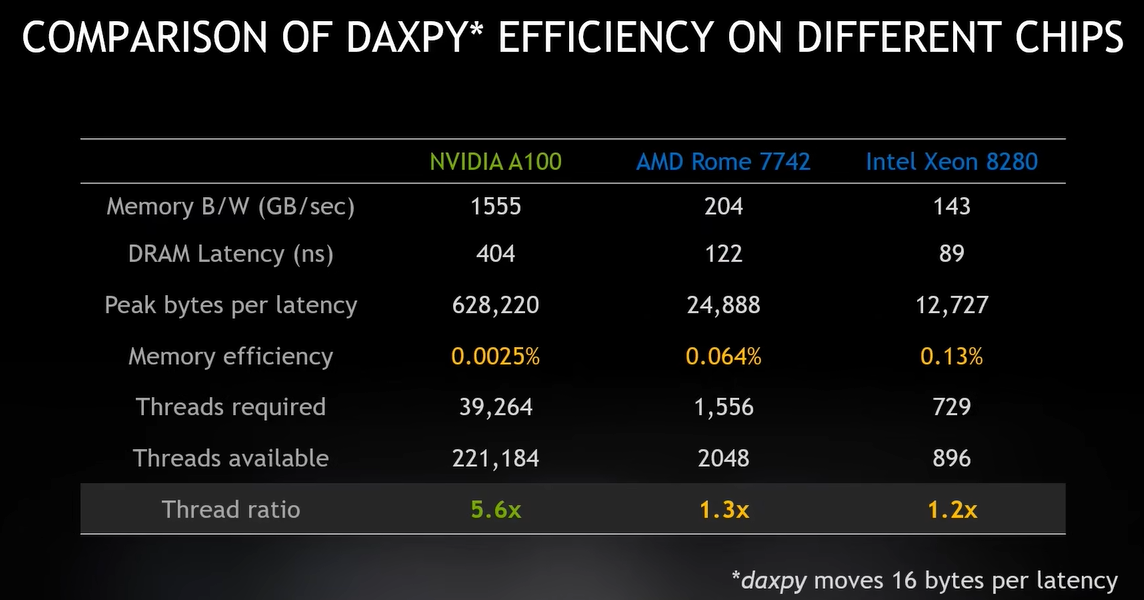 对比
对比
介绍GPU
GPU解决的方式和CPU完全不同,但是内存是最重要的,所有的程序都是和内存相关,
内存带宽、内存延迟以及数据在内存中的位置。
缓存(Cache)
我把寄存器(Register File)作为Cache的一种,这是一个非常重要的GPU细节,
GPU在每个线程中使用大量的寄存器,寄存器能够以很低的延迟来保存活动的数据,
因为不同类型的缓存延迟差距很大。硬件需要一个地方存储指针,
所以当我从内存中加载数据并放到寄存器中,我就可以计算它了,
我可做的内存操作与寄存器的数量直接相关,GPU使用寄存器缓存数据解决高延迟问题,以及通过靠近数据来减少延迟。 缓存
缓存
L1、L2、HBM缓存结构总览 缓存对比
缓存对比
L1、L2、HBM缓存,L1的带宽是最强的,PCIe是最差的,PCIe在这里没有作用,
只是因为它连接GPU和CPU,但我认为NVLink比PCIe更接近主内存领域,NVLink是GPU之间相连的 缓存对比2
缓存对比2
带宽在增加,你需要为主内存准备几乎相同数量的线程(下图是39264),
因为计算强度很高,所以如果这个内存系统中有一个比其他需要更多的线程,就会发现它的瓶颈,
我必须加入更多线程去满足那部分,然后我的内存系统的其他部分便会拥有更多线程,这是一种精心设计的平衡。
 缓存对比3
缓存对比3
SM是一个基础处理单元,它里面有很多东西,实际上要记住的是warp,它有32个线程组成一组,
warp就是GPU的基本调度单位,在一个时钟周期内,我可以运行多个warp,一个SM,包含64个warps,
4个warps可以并行运行。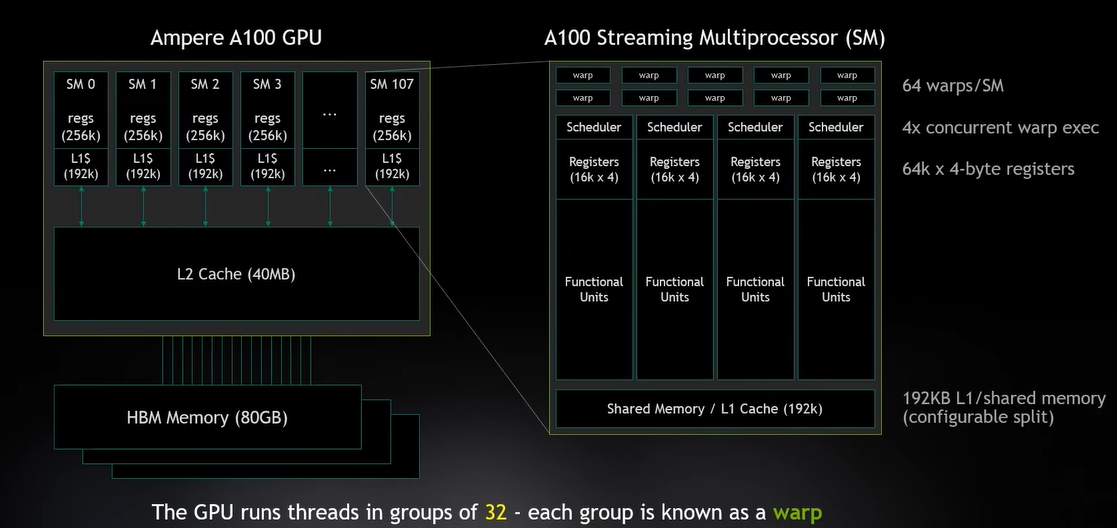 SM
SM
每个SM 2048个线程,120个线程我一次就能跑完了,这就是我说的GPU是超量配额的原因。
当一些线程因为等待延迟关闭时,其他线程大概已经收到了他们的响应,准备运行了(随时切换线程),
这就是GPU工作的全部秘密, 它可以在不同warp之间切换,并且在一个时钟周期内完成,所以根本没有上下文开销。
GPU可以连续运行线程,这意味着系统在任何时候都能运行更多的线程是非常重要的,因为这是解决延迟的好方法。
为什么不希望固定线程,因为GPU是一个吞吐机 SM2
SM2
汽车不能快速有效的帮助其他人,他只能载少数人从一个地方到另一个地方,
火车可以载很多人,会停很多地方,所以在这条线路上的所有人都能得到帮助,
而且沿途可以有很多火车,关于延迟系统很可怕的一个事就是过载,
开车如果路上太多车你哪里都去不到,火车满了可以等下一列,
GPU是一个吞吐机,就像火车一样,让你在站台等,而且需要保持忙碌,
而CPU是一个延迟机,切换线程开销很大,所以需要一个线程尽快的运行。 吞吐机和延迟机
吞吐机和延迟机
- 元素智能算法(Element-wise):两个张量之间操作,它在对应张量内的元素进行操作
- Local:比如卷积,它会引入所有邻居
- all to all:比如傅里叶转换(Fourier Transform),要求每个元素与其他元素相互作用
 算法
算法
如何获取吞吐量
一张猫的图片,将用一个网格覆盖,将网格创建许多工作块,随每个方块单独进行处理,
让这些方块彼此独立处理图像的不同部分,GPU通过超量分配(oversubscribe)加载这些块,
我们想要的是高效执行和内存满载使用。因此,多个块由许多一起工作的线程组成,
这些线程可以共享数据并实现联合任务,该块中的所有线程同时并行运行。 获取吞吐量
获取吞吐量
要做工作,都被分解成线程块,每个块都有并行线程,确保线程同时运行,这样他们就可以共享数据,
但所有块都是超量分配模式下独立调度的。我需要通过吞吐机器保持忙碌,但它也允许一定数量的线程相互交互,
这就是GPU编程的本质 独立调度
独立调度
延迟才是我真正要关心的,所有这些线程都是通过超量分配:程序、网格模型、线程,
所有的都在我的块中运行,从根本上解决延迟问题。
现在我有很多线程,根据前面那个表,我有5倍的线程,远远超过我需要的线程,问题是那么多的线程如何调度。
这归结到算法的复杂性,也就是说,我增加问题的规模,我可以增加很多线程,但我要怎么操作呢?
例如对于Element-wise,每次我添加一个线程,我都加载一个新的数据元素,但是我只做了一次操作,
我添加了一个线程,加载数据一部分,再做一个计算,我添加的线程实际上不会带来变化,我所请求的Flops增加了,
但我的算法以及算法的强度是平滑的,比如2D、卷积或者3D。我现在的数据,当我增加方块时,它是可扩展的。
它的算术强度是1:1计算,在卷积中即使再多的数据也无法与我的计算强度抗衡(线程和计算量同时增大)。 独立调度2
独立调度2
矩阵乘法是一个大而复杂的东西,但它是由大量的FMA(Fused-Multiply-Add)堆积起来的。
它重复计算很多次,这个矩阵每个绿点装载25次,我只处理了这一行并用作25次计算,
如果矩阵是10X10,我会以100次操作的速度重复使用它,这就是我想要的计算强度,
因此,随着矩阵的增长,极大地提高我的Flops能力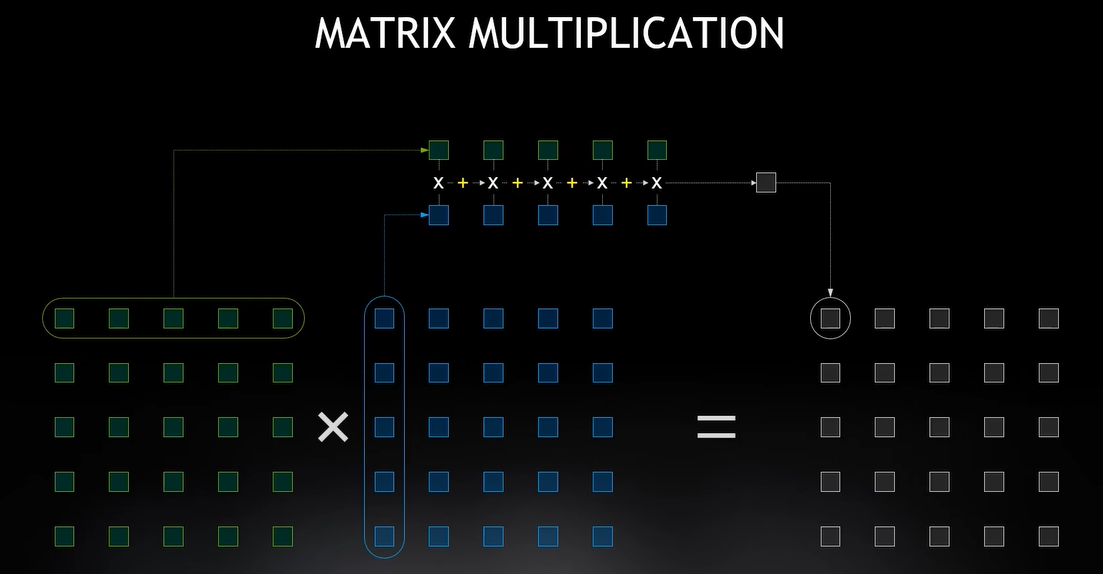 矩阵
矩阵
所以矩阵乘法具有算术强度,它增加矩阵立方的大小,这就是矩阵乘法的本质。
同时,随着矩阵变大,数据加载量呈指数级增加,我已经对正在加载的数据增添了指数,
所以我的算术强度、扩展性、算法复杂度是有序的。 矩阵相乘
矩阵相乘
这两个线的交点在50,一旦矩阵大小达到50,我们就会获取所有数据,为了满足Flops需求,
计算机会抓取所有它能处理的数据,所以这就是我能有效计算的最大矩阵,我的内存现在比计算要空闲的多,
理想情况下,为了让你的机器保持平衡,需要让一切都以100%的速度运行,这就是吞吐机的意义所在,
所以最佳点就是这条线的交点。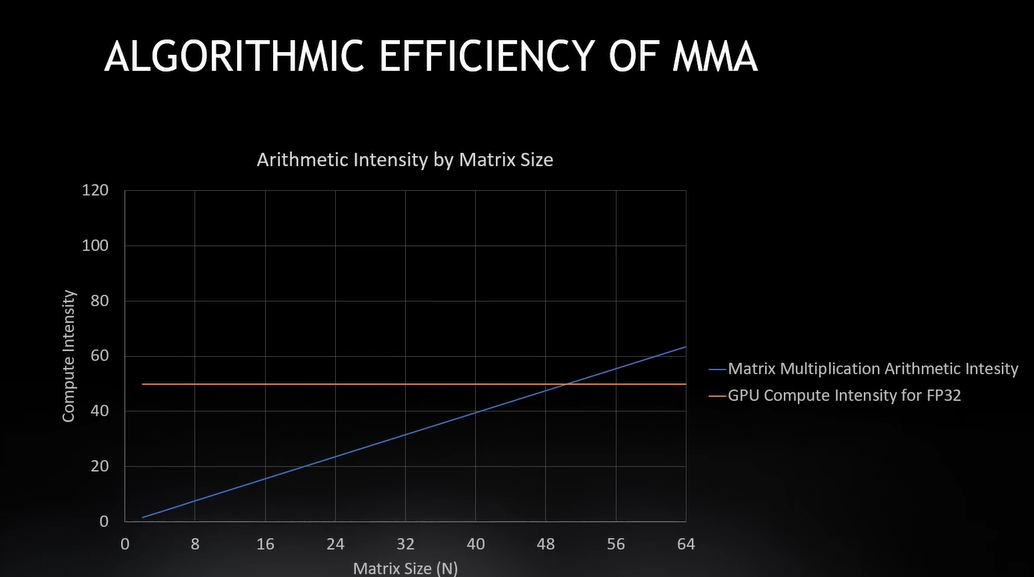 有效计算
有效计算
下图是FP32和FP64的交点的比较,计算强度100的线,到达100将会达到双精度计算的最大值,
当然,随着矩阵增大,内存会变得越来越空闲,因为我要花越来越多的时间来计算。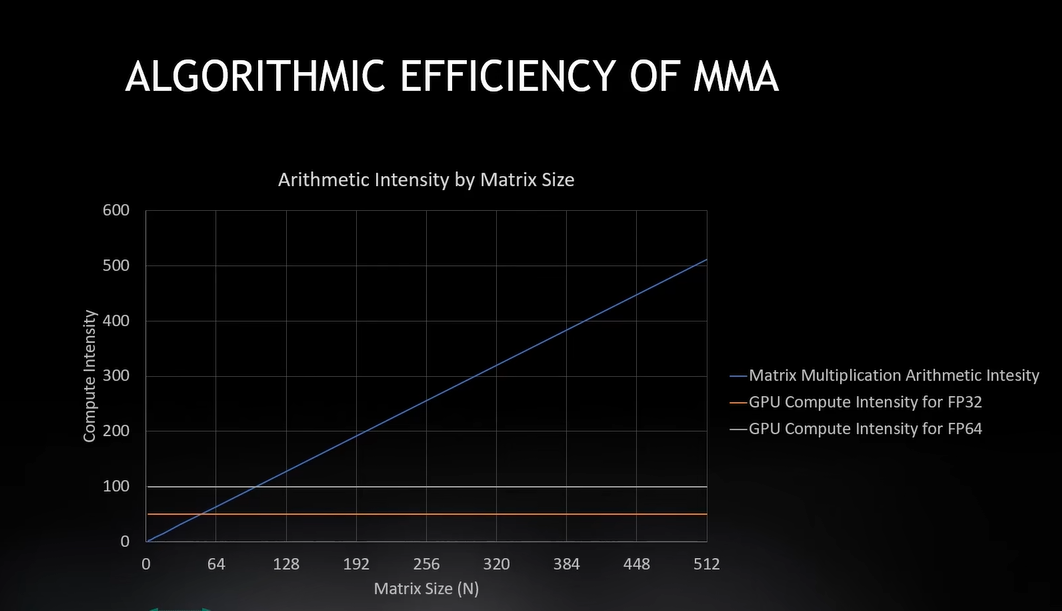 有效计算对比
有效计算对比
所以现在我们可以引入Tensor Core,Tensor Core是内置在SM中的定制硬件单元,
很像一个算术单元,我可以乘或加运算,但是它们可以一次性完成整个矩阵运算,
这意味着它们可以一步完成多个Flops请求任务,FMA每个指令可以做两个乘加运算,
它为每个指令增加了两个Flops,这些张量核心能够比Cuda核心实现更多的Flops。
我想要跑得更快,但是更大的Flops需要更大的问题规模,当内存空间用完时,就无法增大Flops了。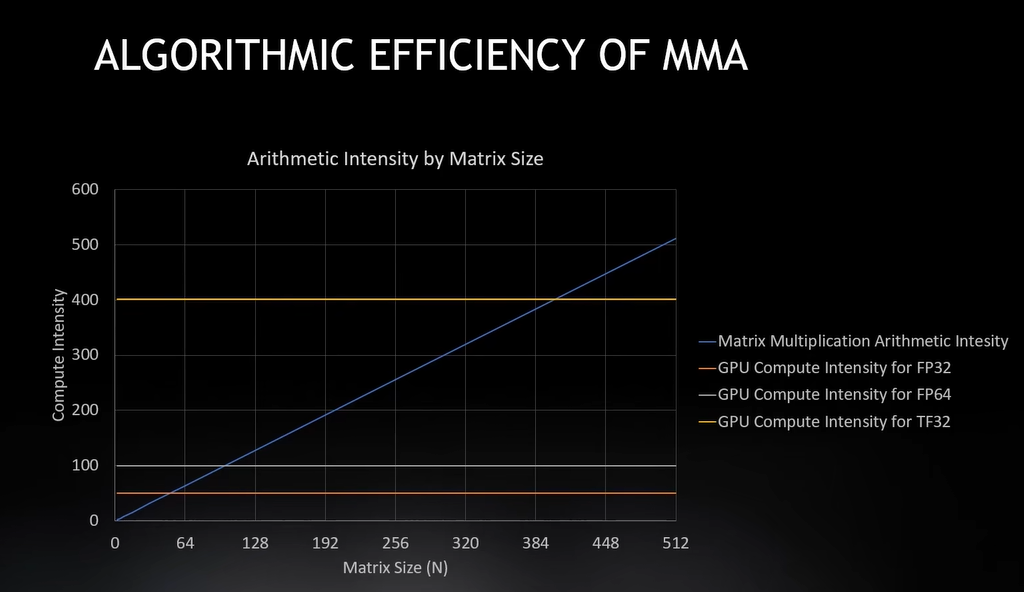 Tensor Core
Tensor Core
HBM计算强度有400,这就是为什么它需要使用HBM内存进行操作。
如果使用L2缓存,我的计算强度只有156,L1更小,只有32,
所以我显然需要使用缓存来搭配我的张量核心,使它在最小矩阵下更高效。缓存对比2
在我的主存储器里是400,L2是156,L1中是32,我可以快速处理小矩阵,因为我已经改变数据所在的位置。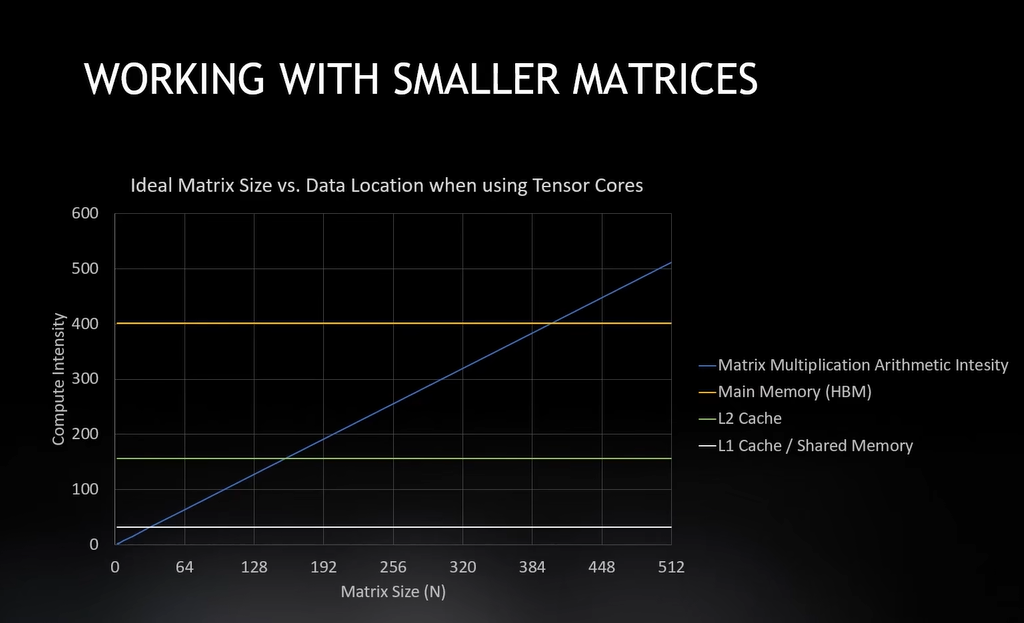 缓存对比4
缓存对比4
- 本文作者:樱白 - Cherry White
- 本文链接:https://cherry-white.github.io/posts/3e8e8143.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!
☕ 如果这篇文章对你有帮助
欢迎请我喝杯咖啡,支持持续创作