
现代游戏引擎 - 高级AI系统:HTN、GOAP与强化学习(十七)
高级AI大纲
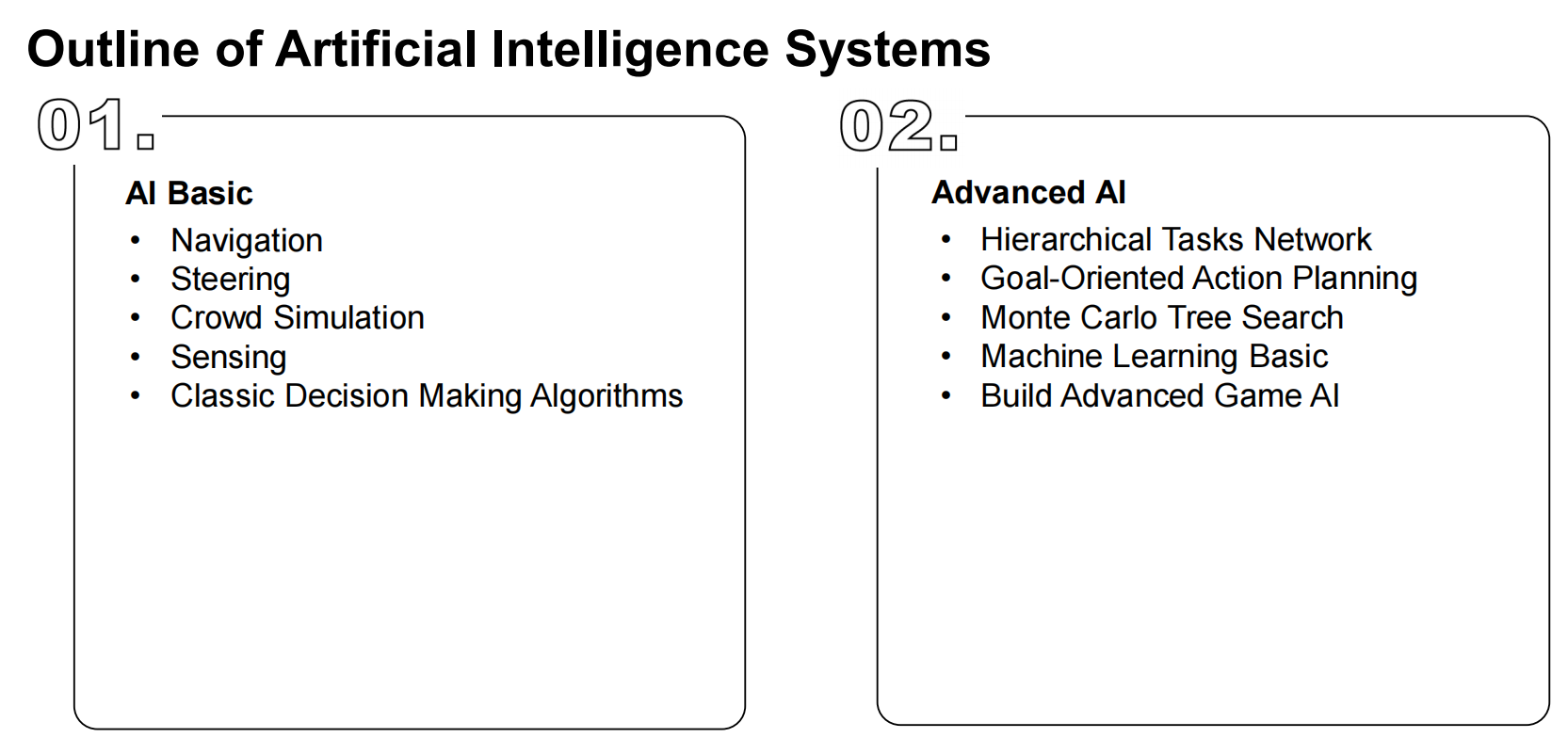 高级AI大纲
高级AI大纲
层次任务网络(Hierarchical Tasks Network)
层次任务网络(hierarchical tasks network, HTN)是经典的游戏AI技术,和上一节介绍过的行为树相比HTN可以更好地表达AI自身的意志和驱动力。 概括
概括
HTN的思想是把总体目标分解成若干个步骤,其中每个步骤可以包含不同的选项。AI在执行时需要按照顺序完成每个步骤,并且根据自身的状态选择合适的行为。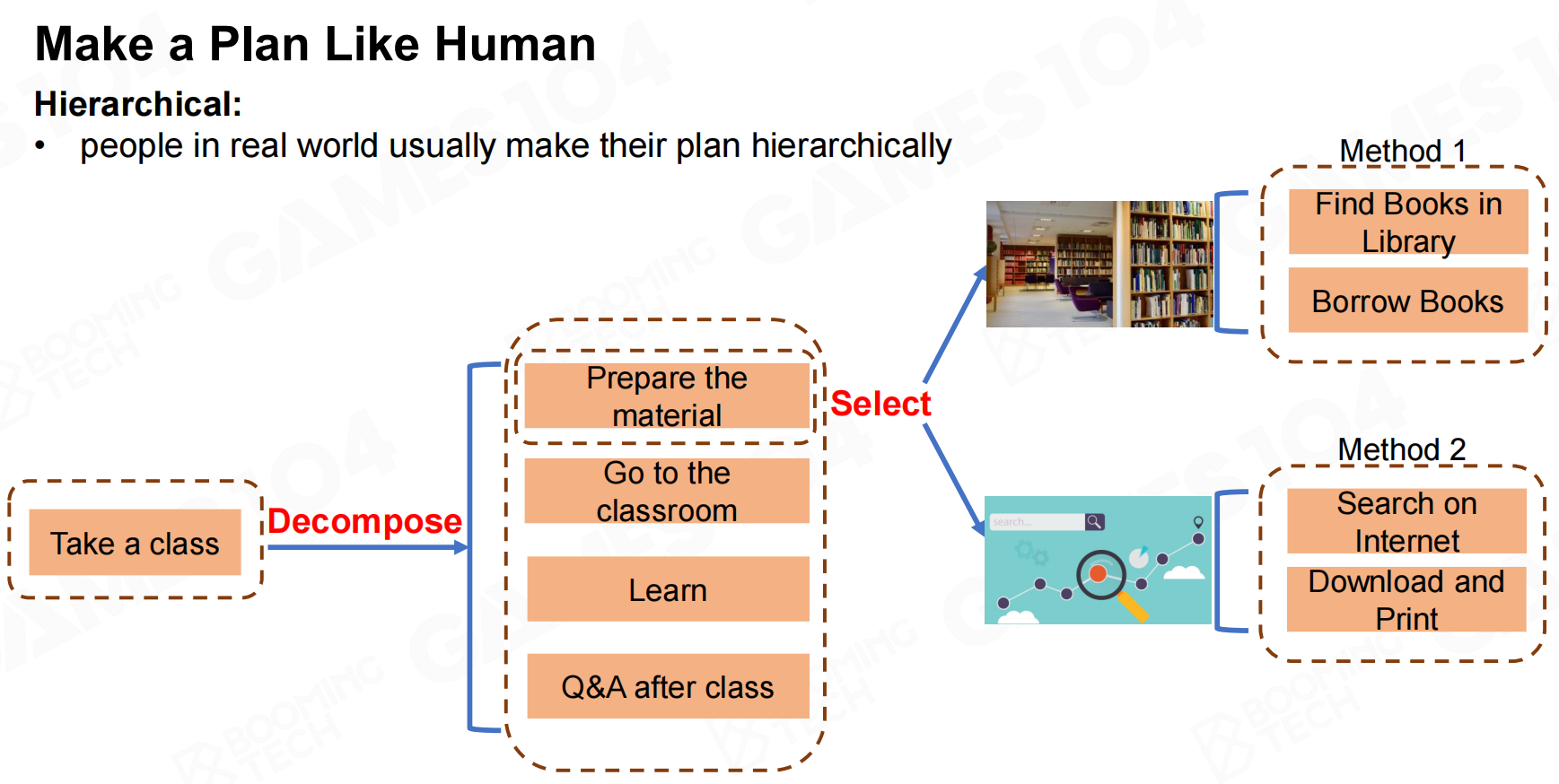 像人一样制定一个计划
像人一样制定一个计划
分层任务网络框架(HTN Framework)
HTN框架中包含两部分,world state和sensor两部分。其中world state是AI对于游戏世界的认知,而sensor则是AI从游戏世界获取信息的渠道。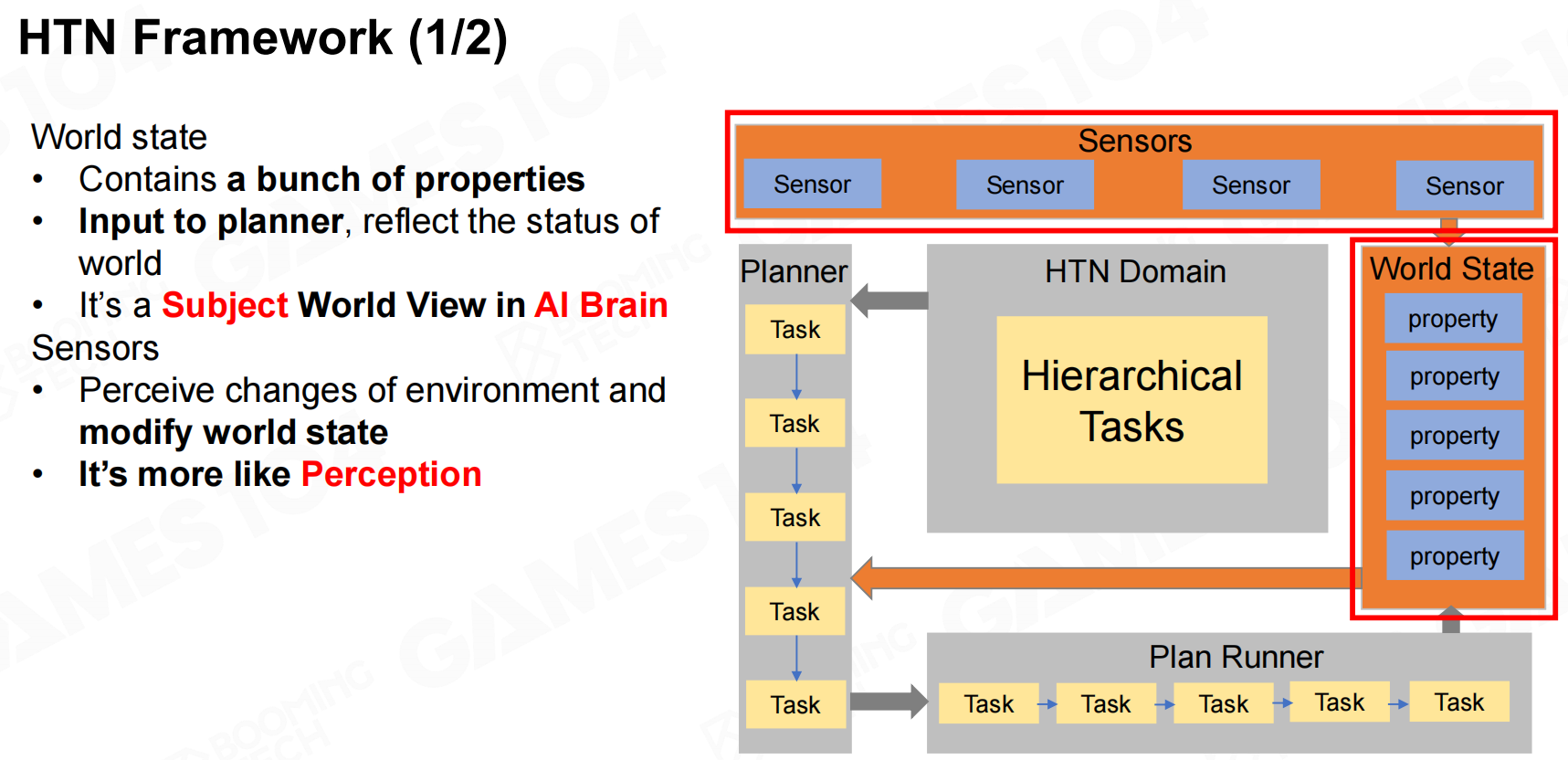 分层任务网络框架
分层任务网络框架
除此之外HTN还包括domain,planner以及plan runner来表示AI的规划以及执行规划的过程。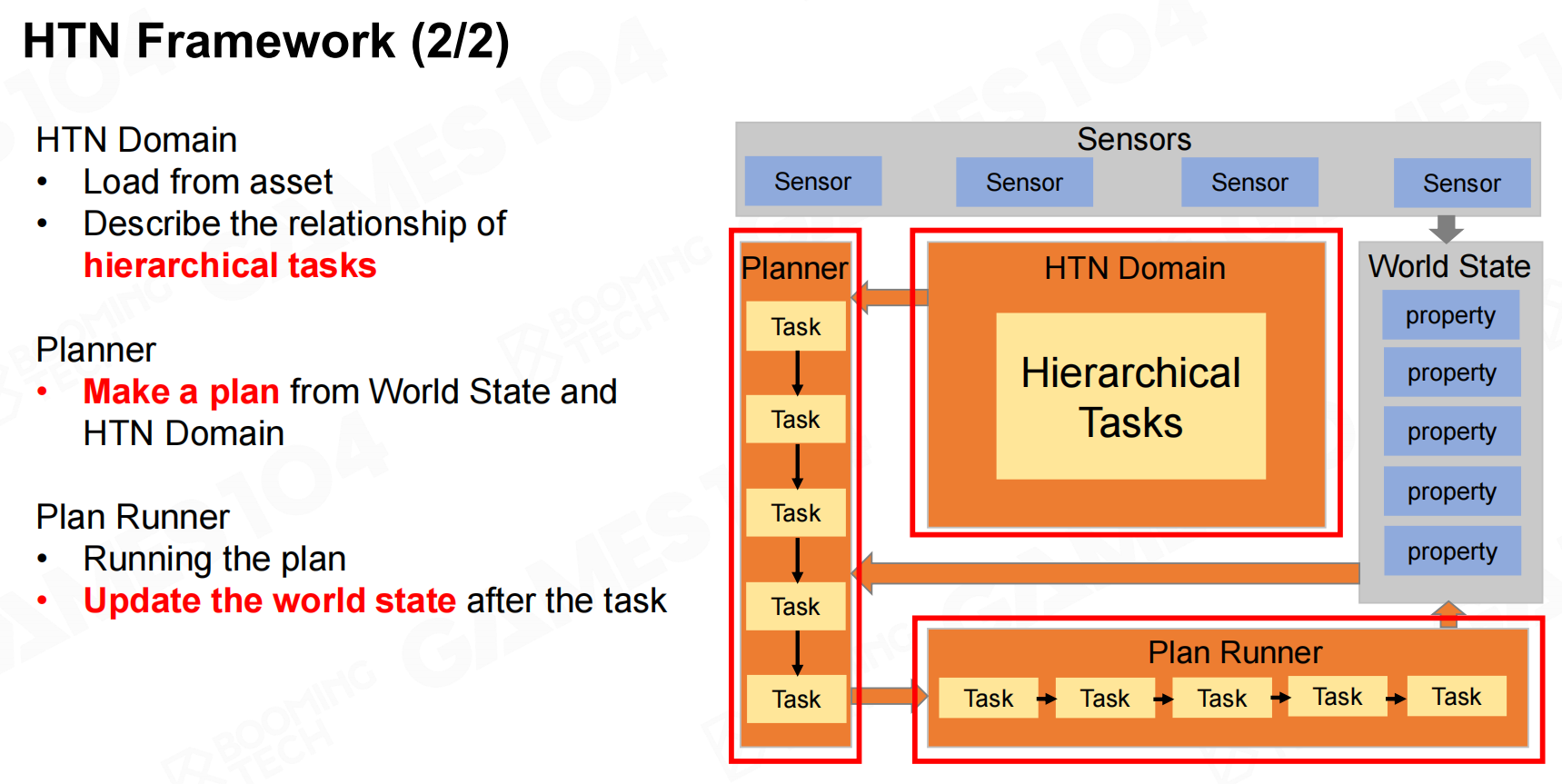 分层任务网络框架2
分层任务网络框架2
分层网络任务类型(HTN Task Types)
在HTN中我们将任务分为两类,primitive task和compound task。 分层网络任务类型
分层网络任务类型
primitive task一般表示一个具体的动作或行为。在HTN中每个primitive task需要包含precondition、action以及effects三个要素。 原始任务
原始任务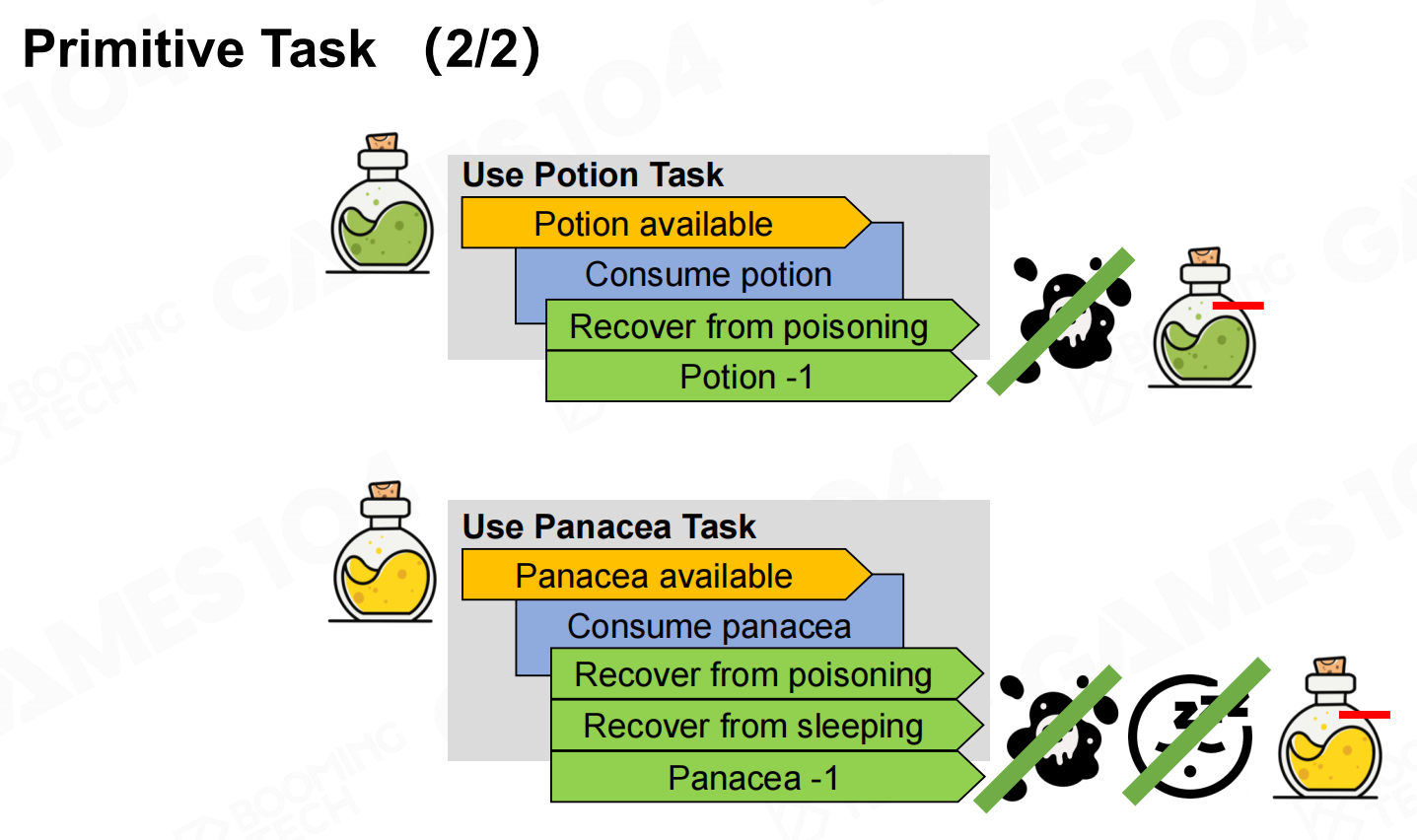 原始任务2
原始任务2
而compound task则包含不同的方法,我们把这些方法按照一定的优先级组织起来并且在执行时按照优先级高到低的顺序进行选择。每个方法还可以包含其它的primitive task或者compound task,当方法内所有的task都执行完毕则表示任务完成。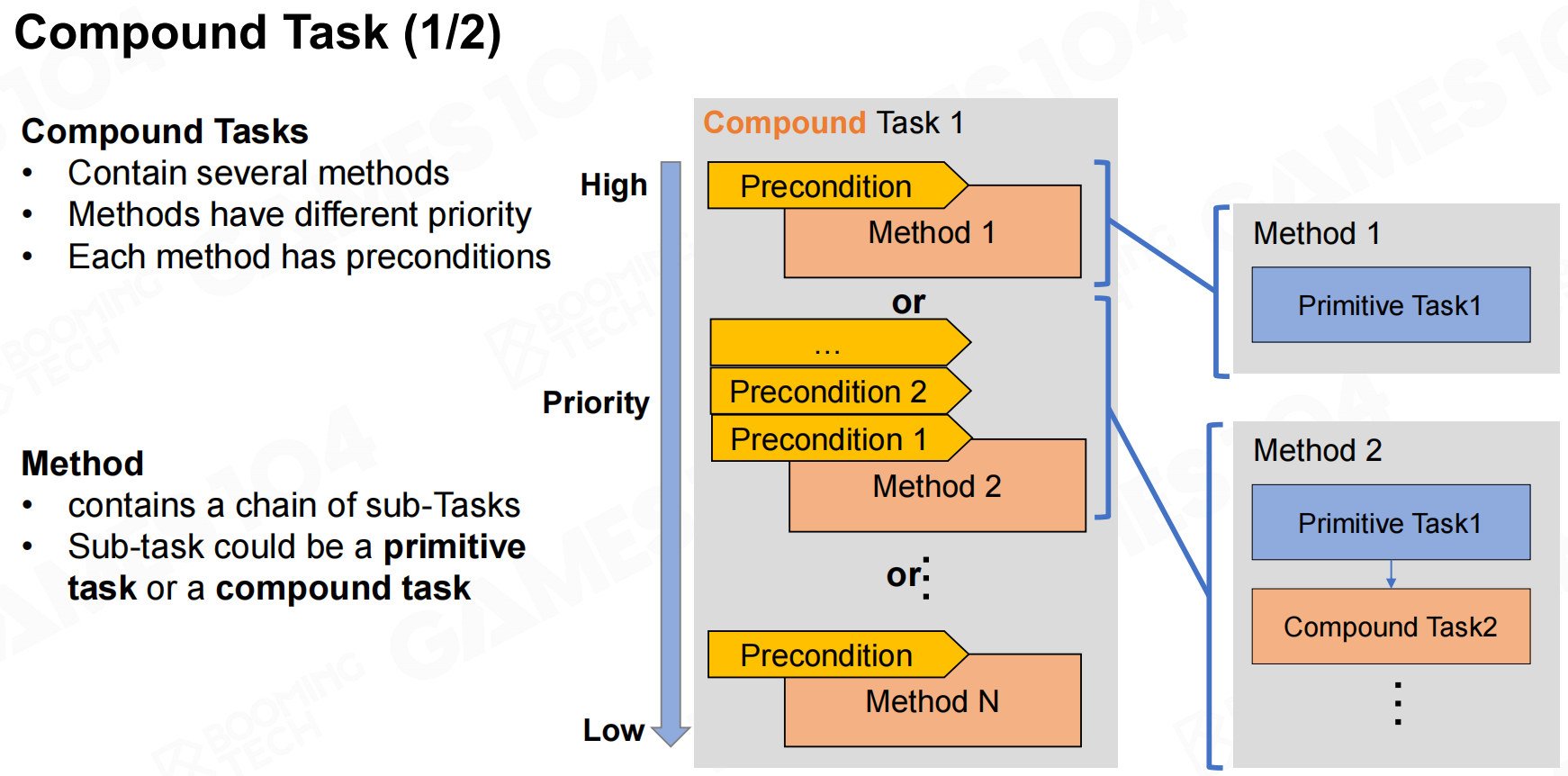 复合任务
复合任务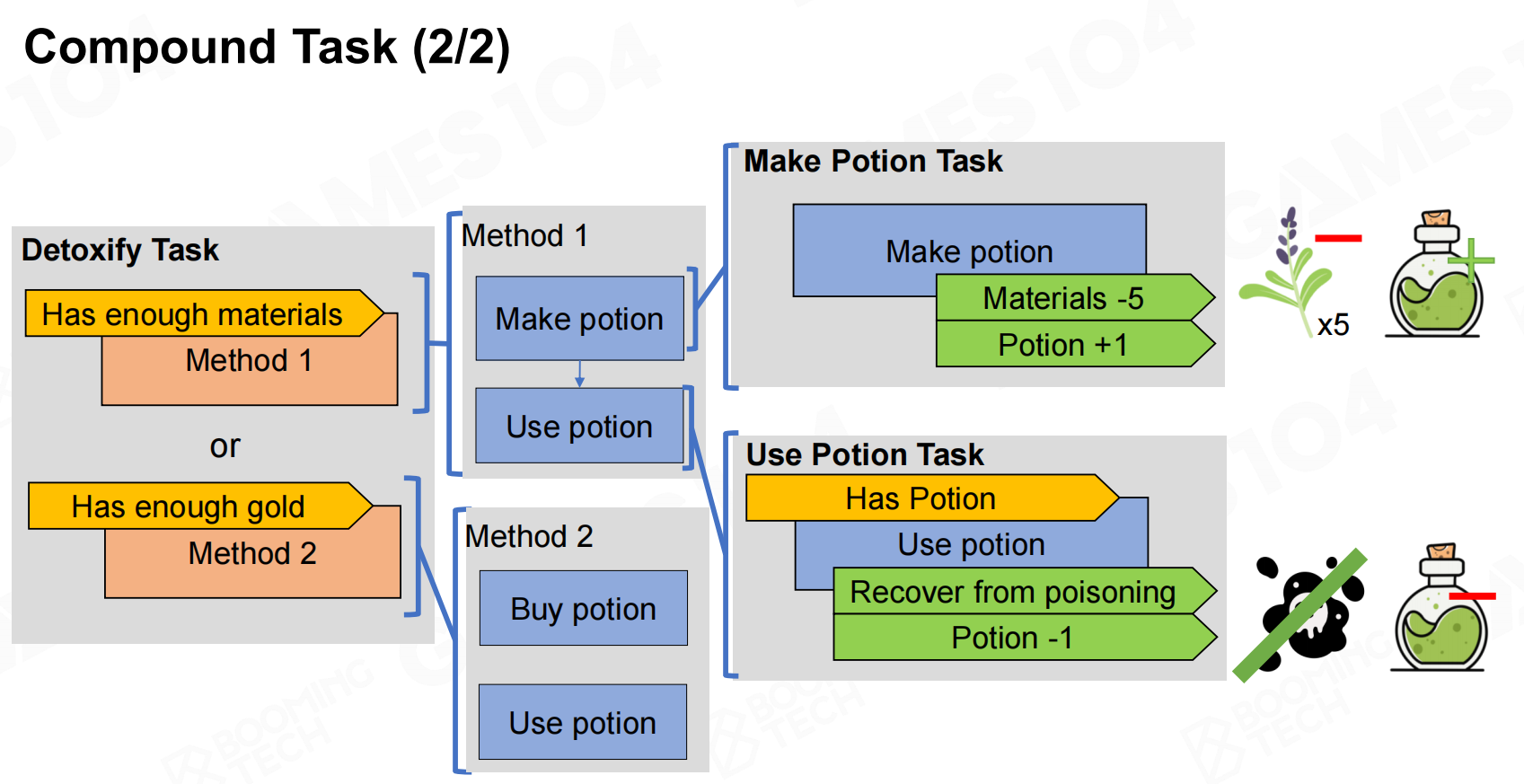 复合任务2
复合任务2
在此基础上就可以构造出整个HTN的domain,从而实现AI的行为逻辑。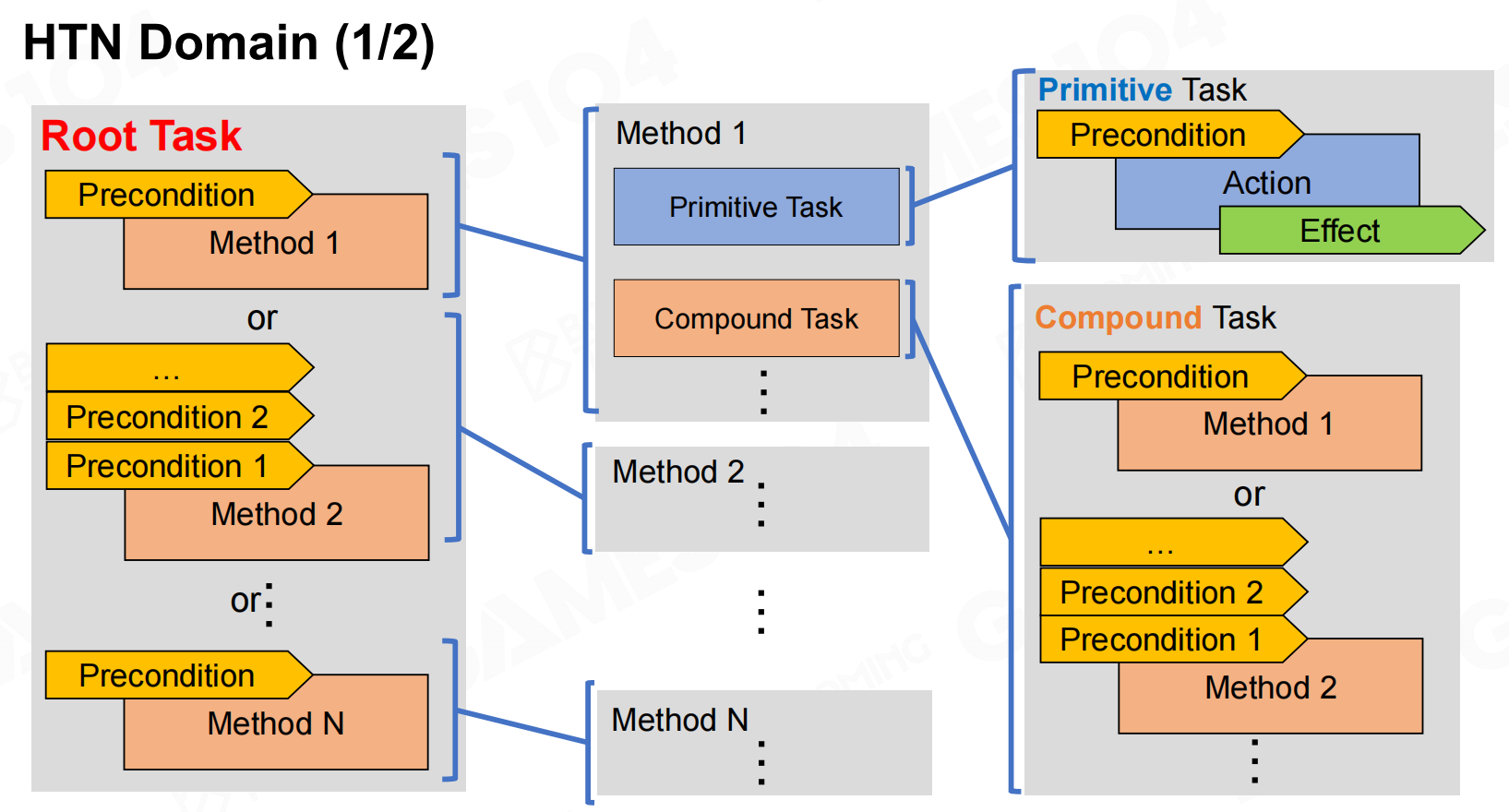 HTN域
HTN域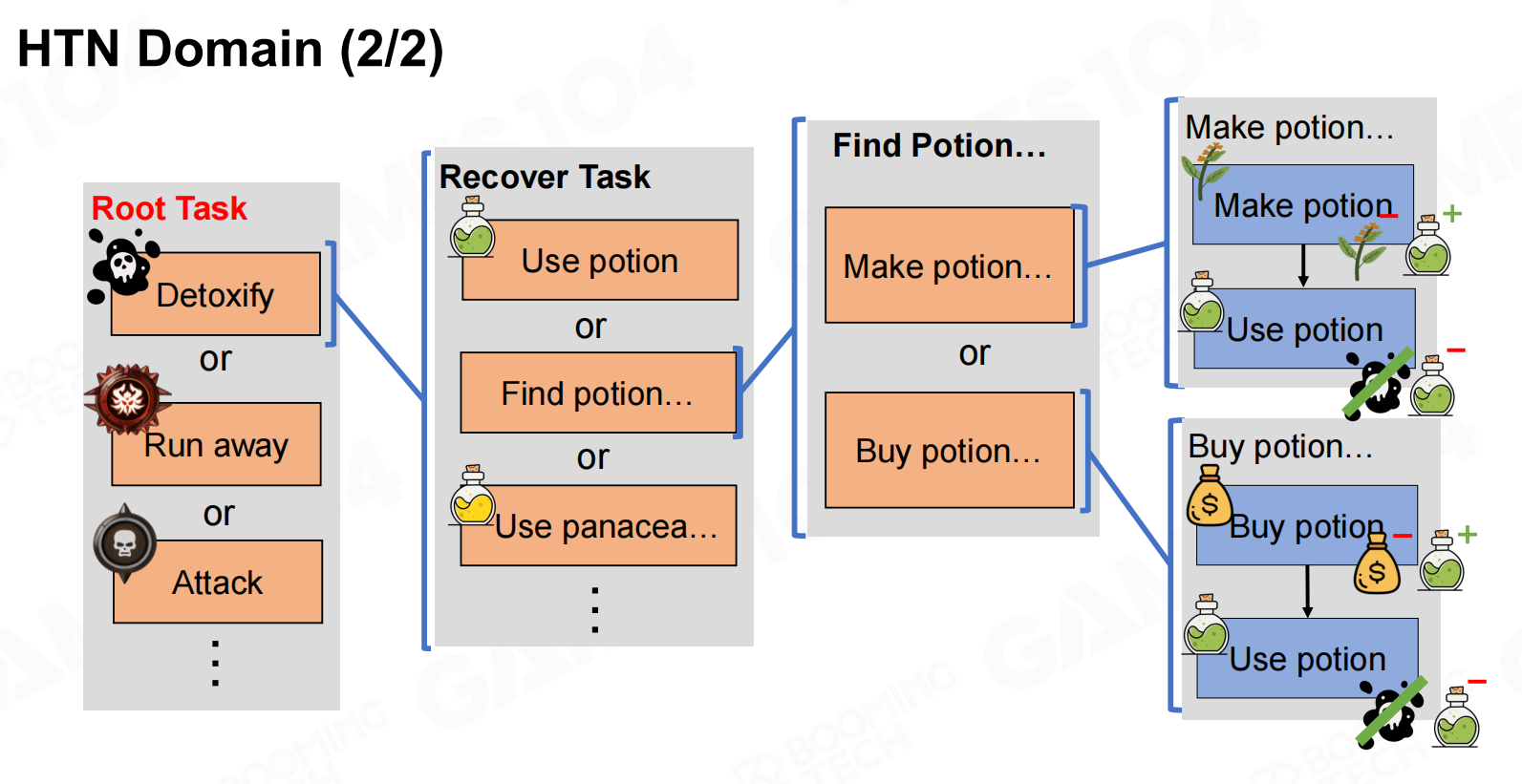 HTN域2
HTN域2
规划(Planning)
接下来就可以进行规划了,我们从root task出发不断进行展开逐步完成每个任务。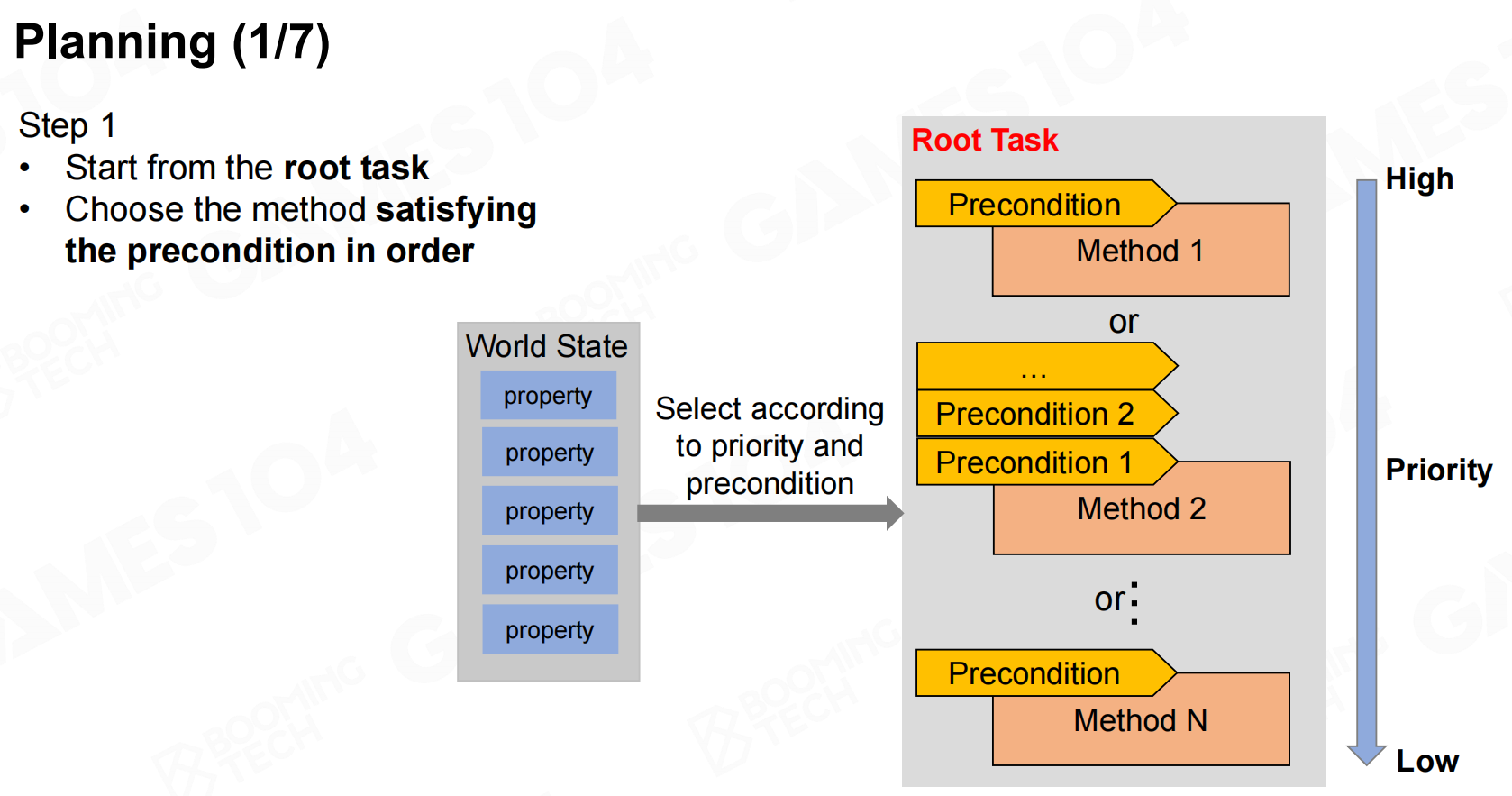 规划
规划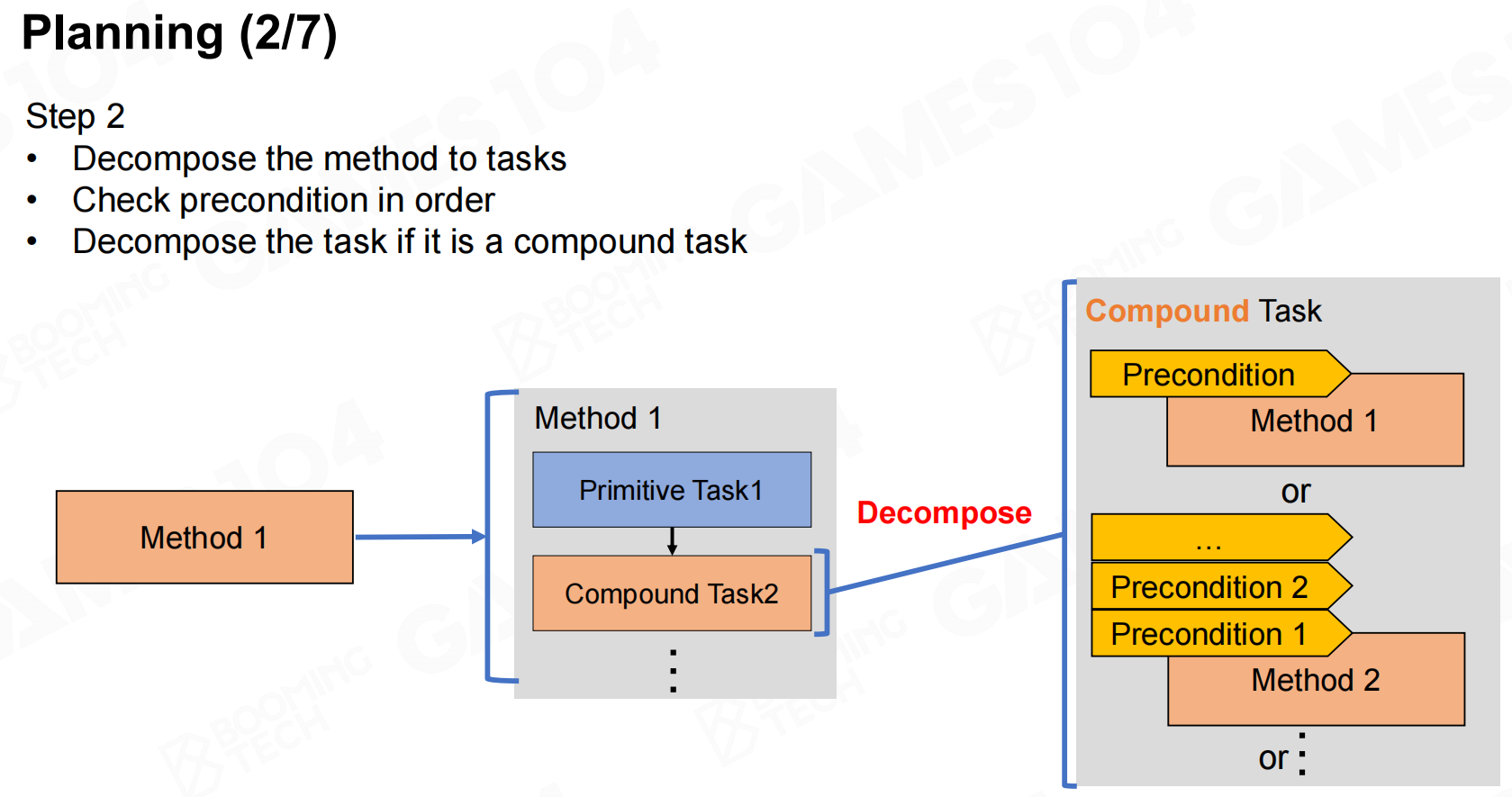 规划2
规划2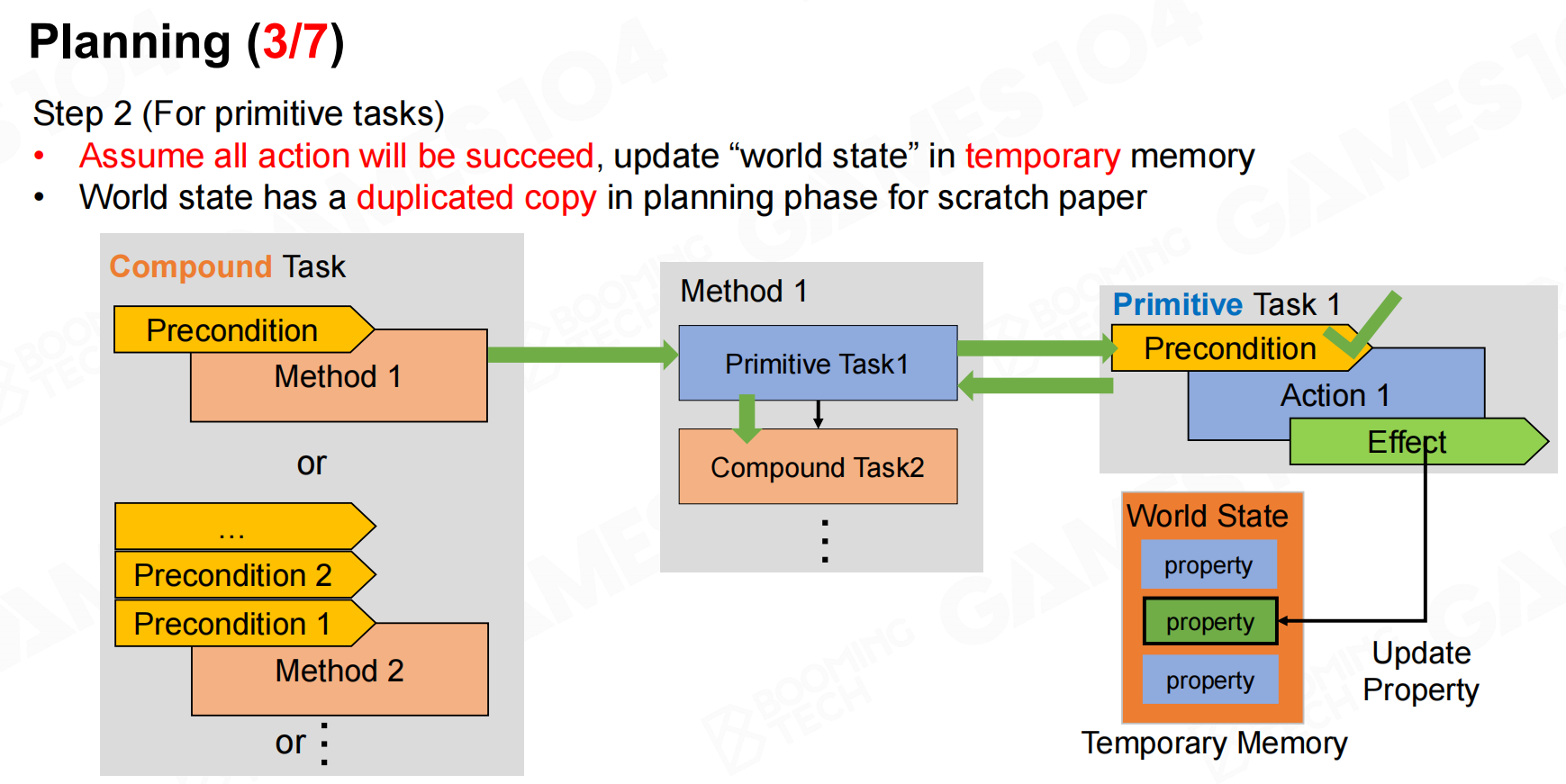 规划3
规划3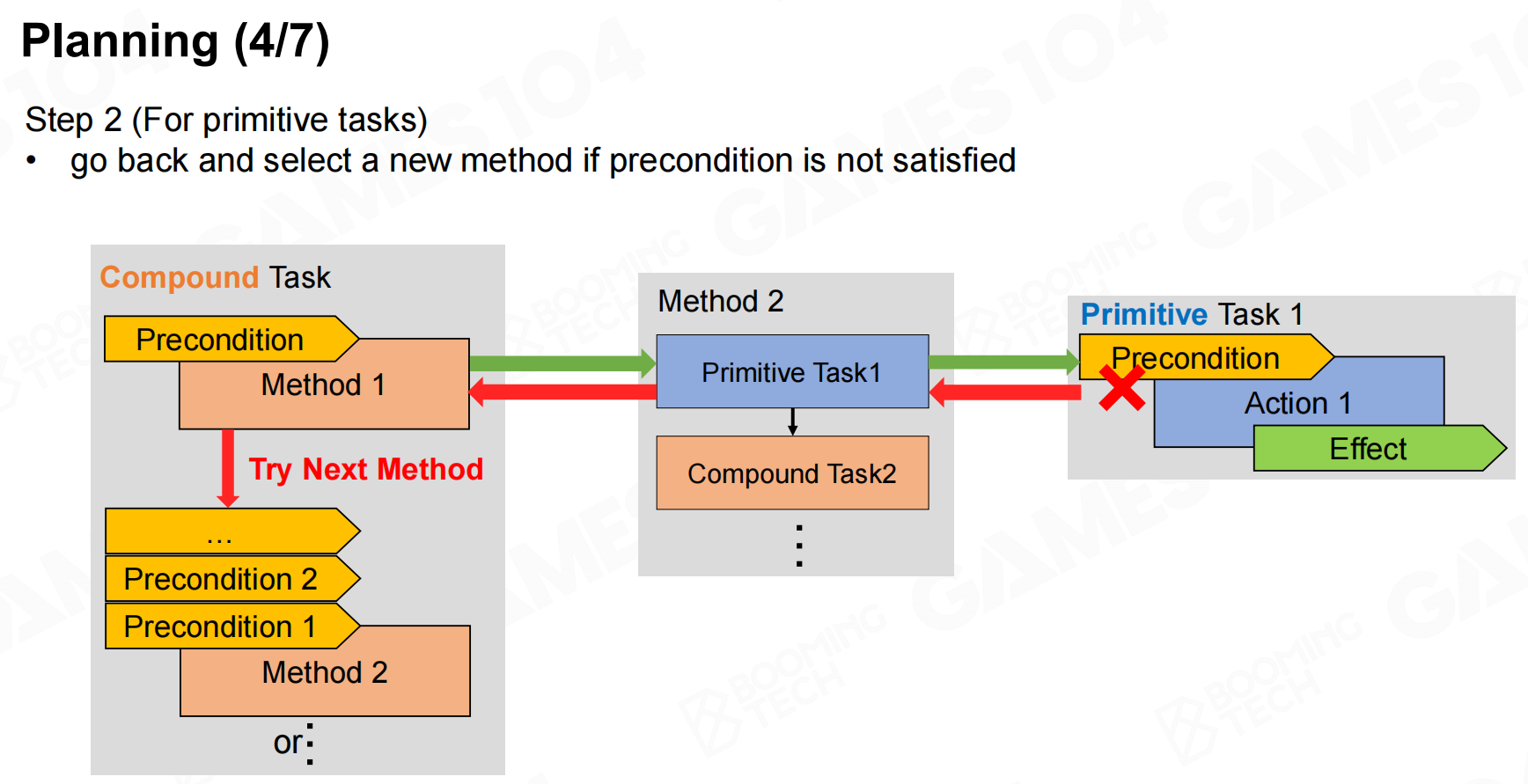 规划4
规划4 规划5
规划5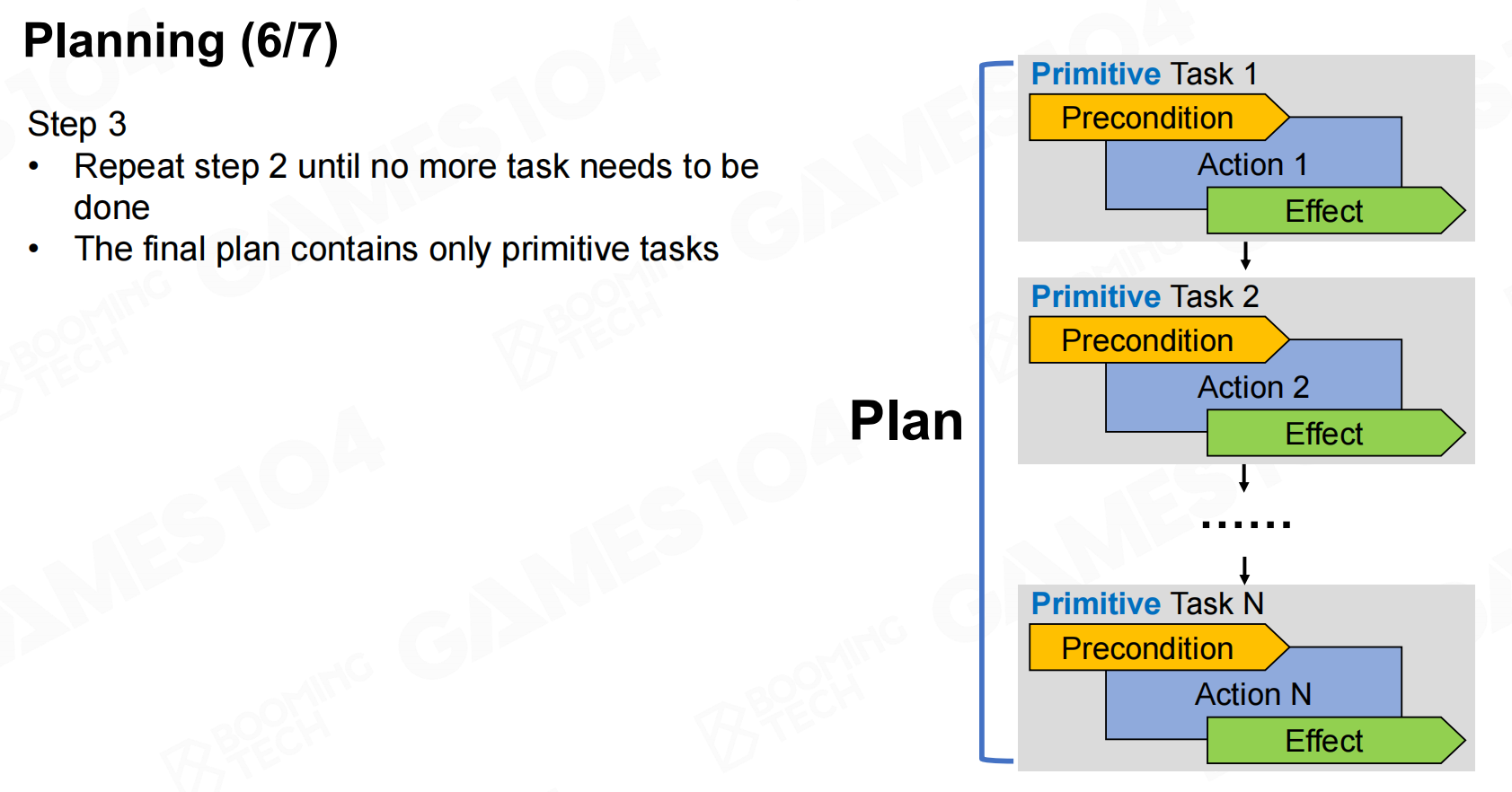 规划6
规划6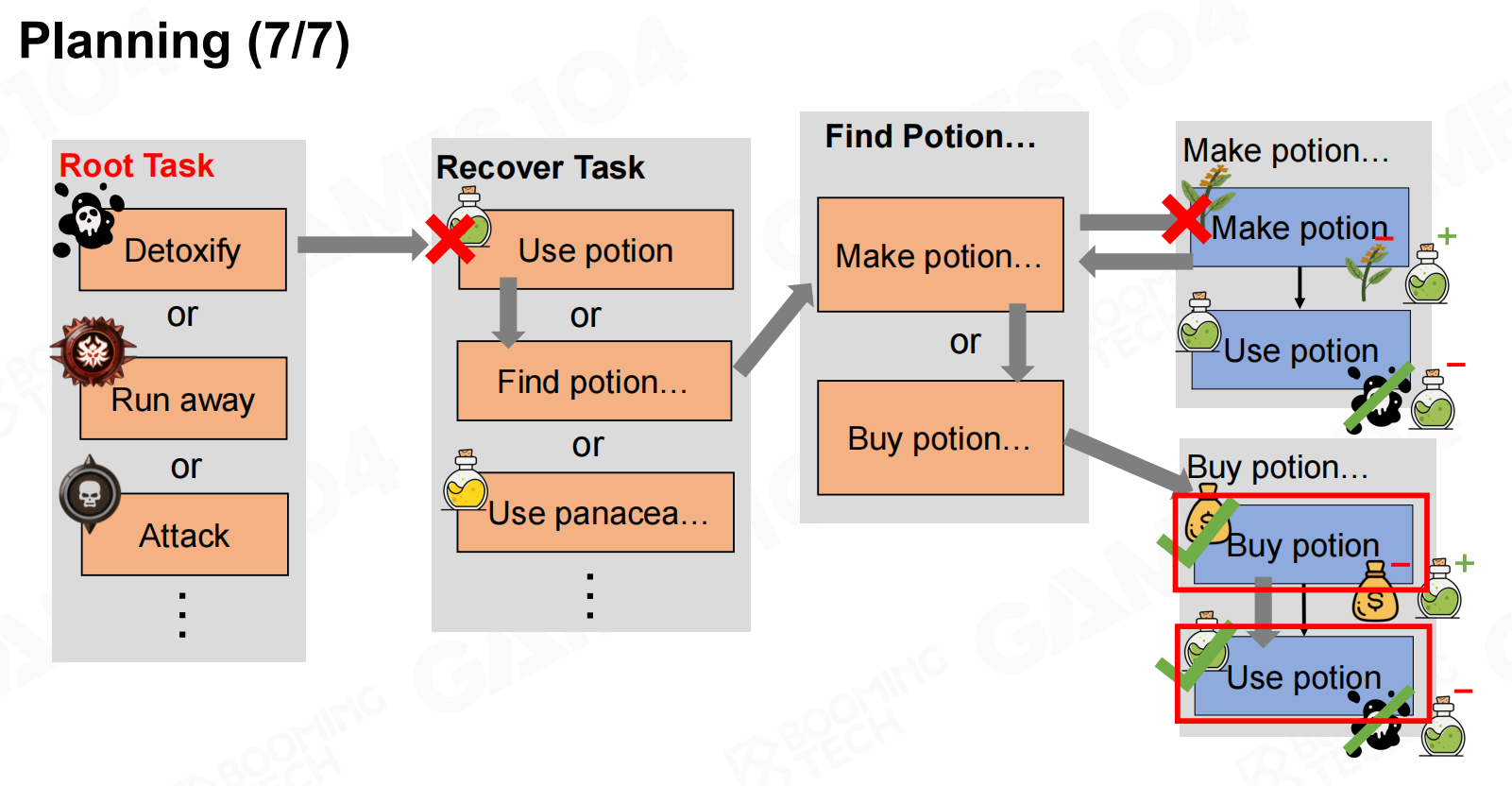 规划7
规划7
重新规划(Replan)
执行plan时需要注意有时任务会失败,这就需要我们重新进行规划,这一过程称为replan。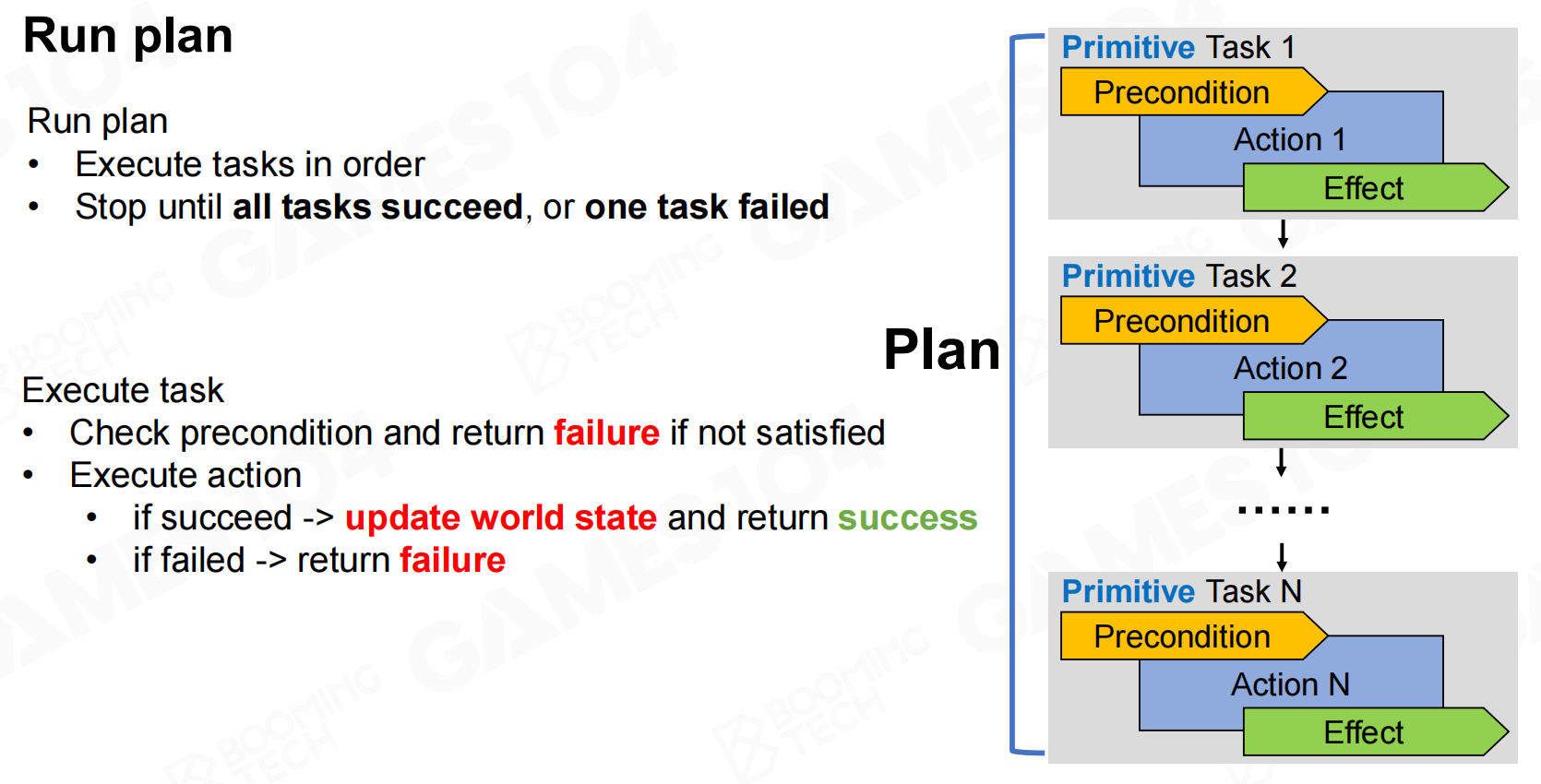 运行规划
运行规划
当plan执行完毕或是发生失败,亦或是world state发生改变后就需要进行replan。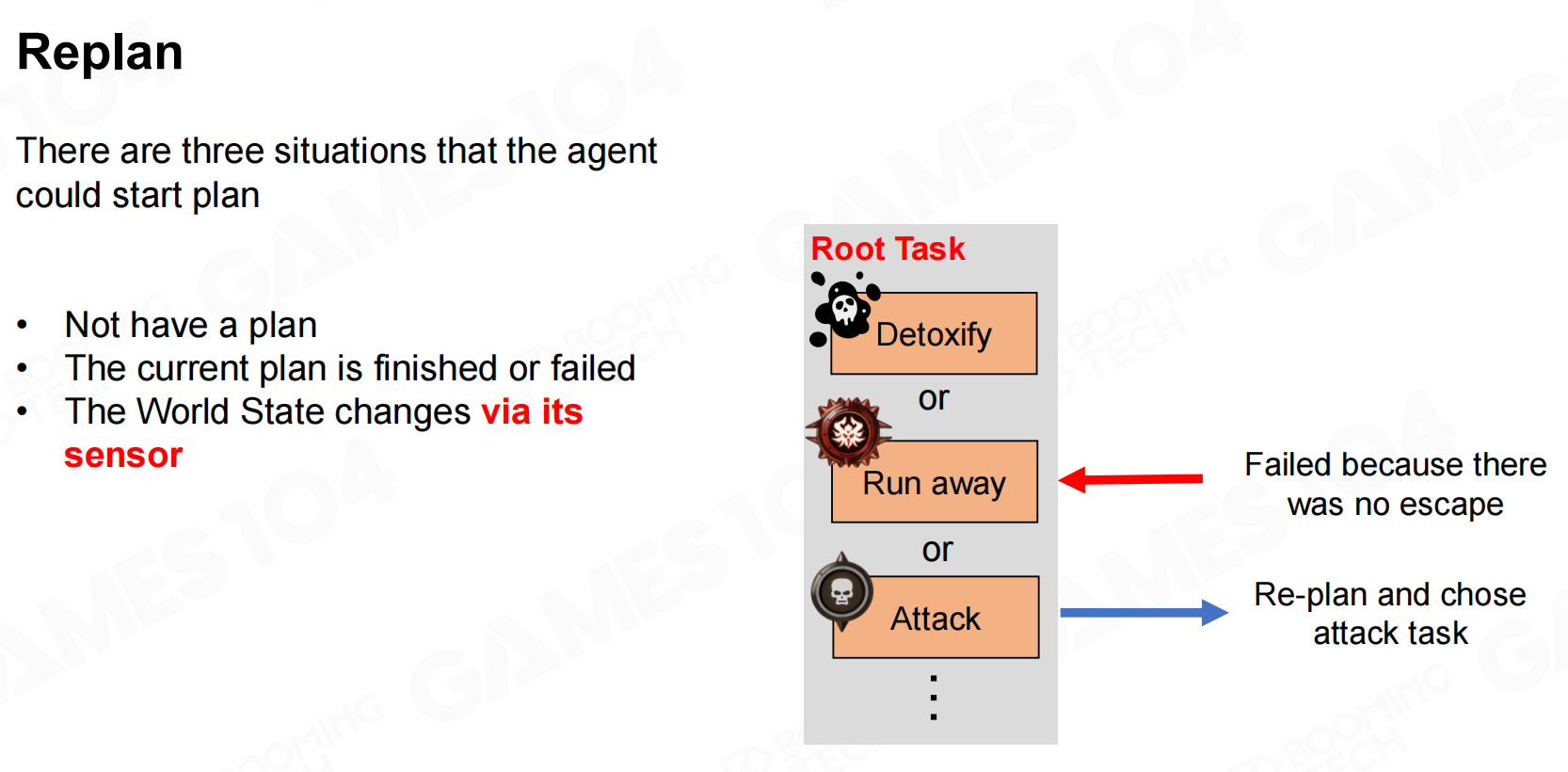 重新规划
重新规划
总结一下HTN和BT非常相似,但它更加符合人的直觉也更易于设计师进行掌握。 总结
总结
目标导向的AI系统(Goal-Oriented Action Planning - GOAP)
goal-oriented action planning(GOAP)是一种基于规划的AI技术,和前面介绍过的方法相比GOAP一般会更适合动态的环境。 目标导向的AI系统
目标导向的AI系统
结构(Structure)
GOAP的整体结构与HTN非常相似,不过在GOAP中domain被替换为goal set和action set。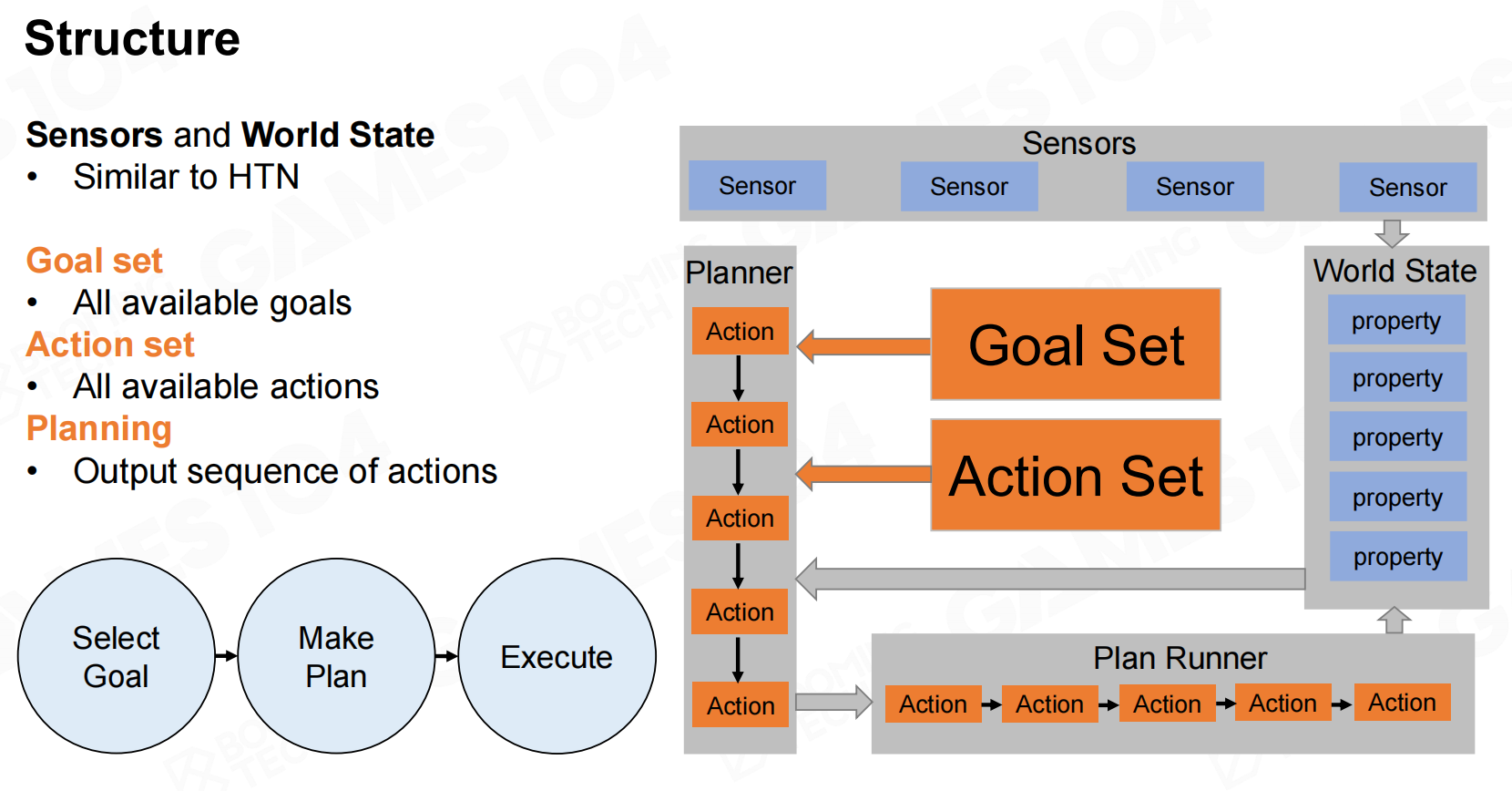 结构
结构
goal set表示AI所有可以达成的目标。在GOAP中需要显式地定义可以实现的目标,这要求我们把目标使用相应的状态来进行表达。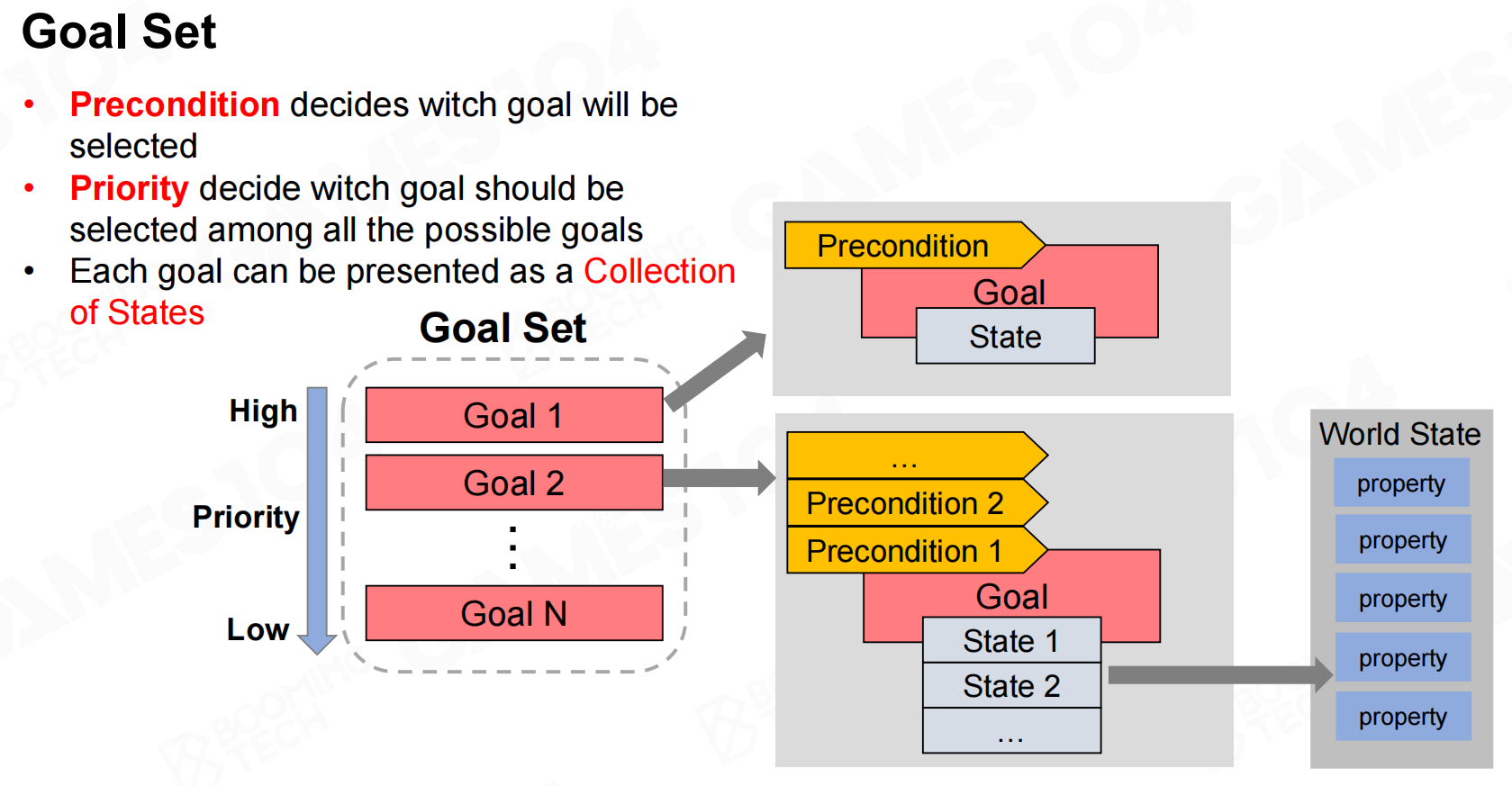 目标集合
目标集合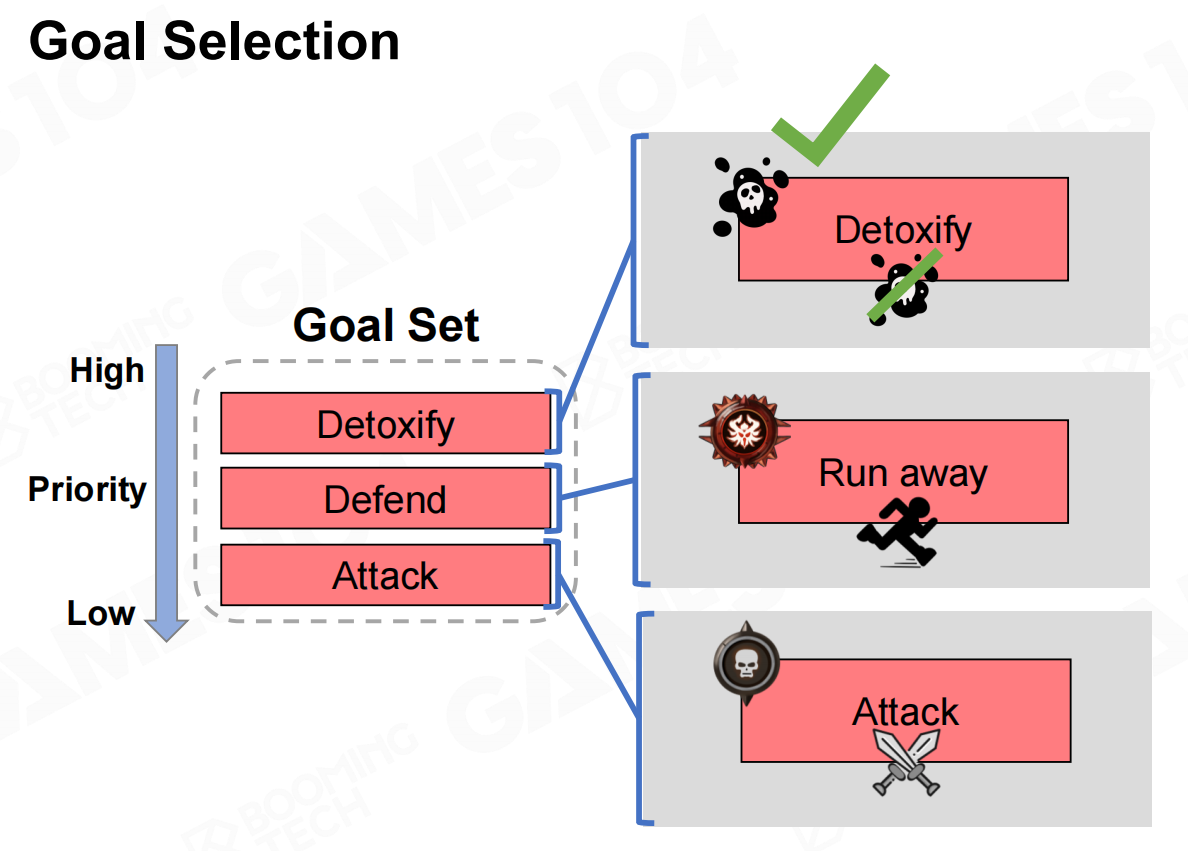 目标选择
目标选择
而action set则接近于primitive task的概念,它表示AI可以执行的行为。需要注意的是action set还包含代价(cost)的概念,它表示不同动作的”优劣”程度。在进行规划时我们希望AI尽可能做出代价小的决策。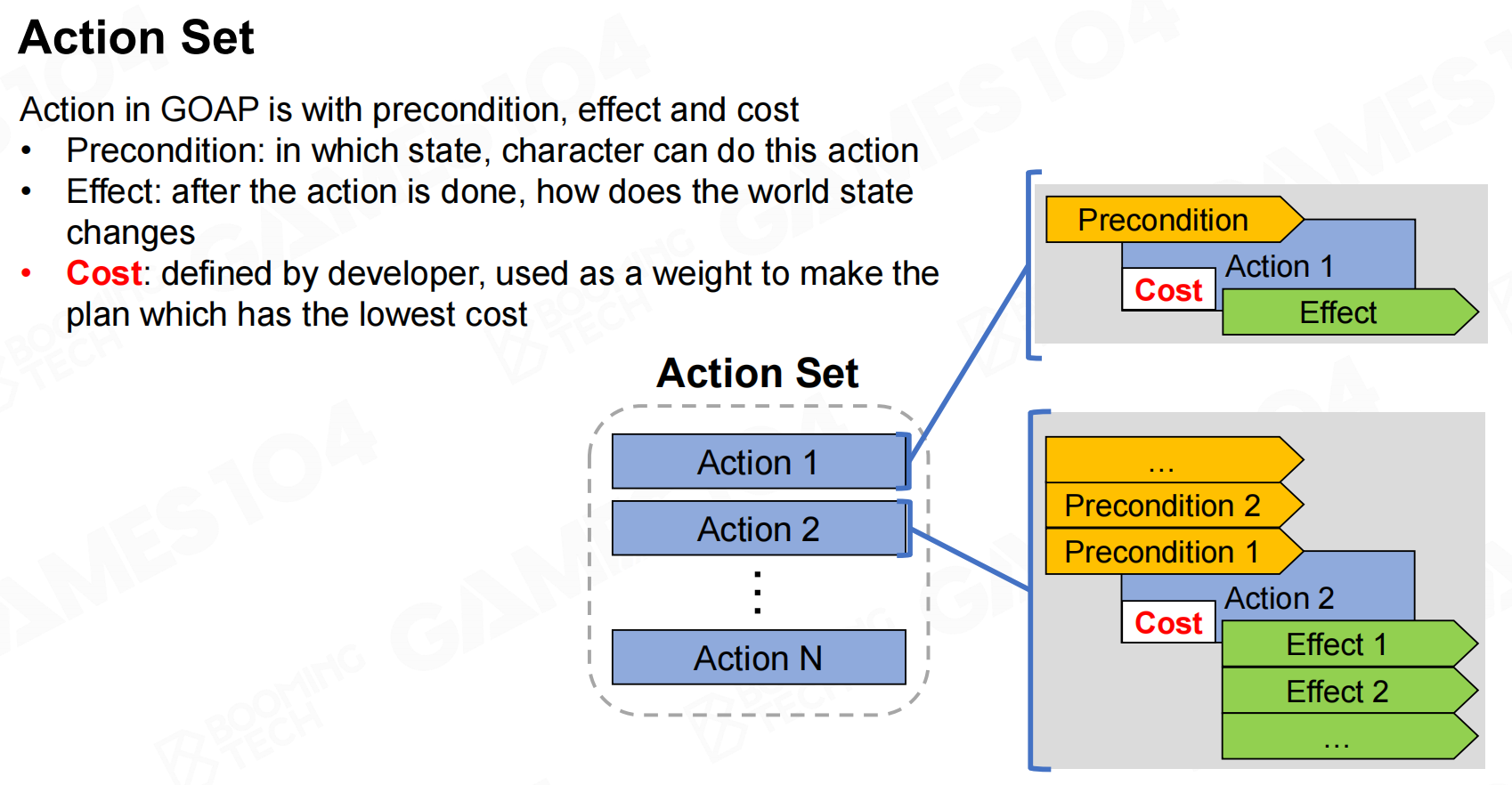 操作集
操作集
规划(Planning)
GOAP在进行规划时会从目标来倒推需要执行的动作,这一过程称为反向规划(backward planning)。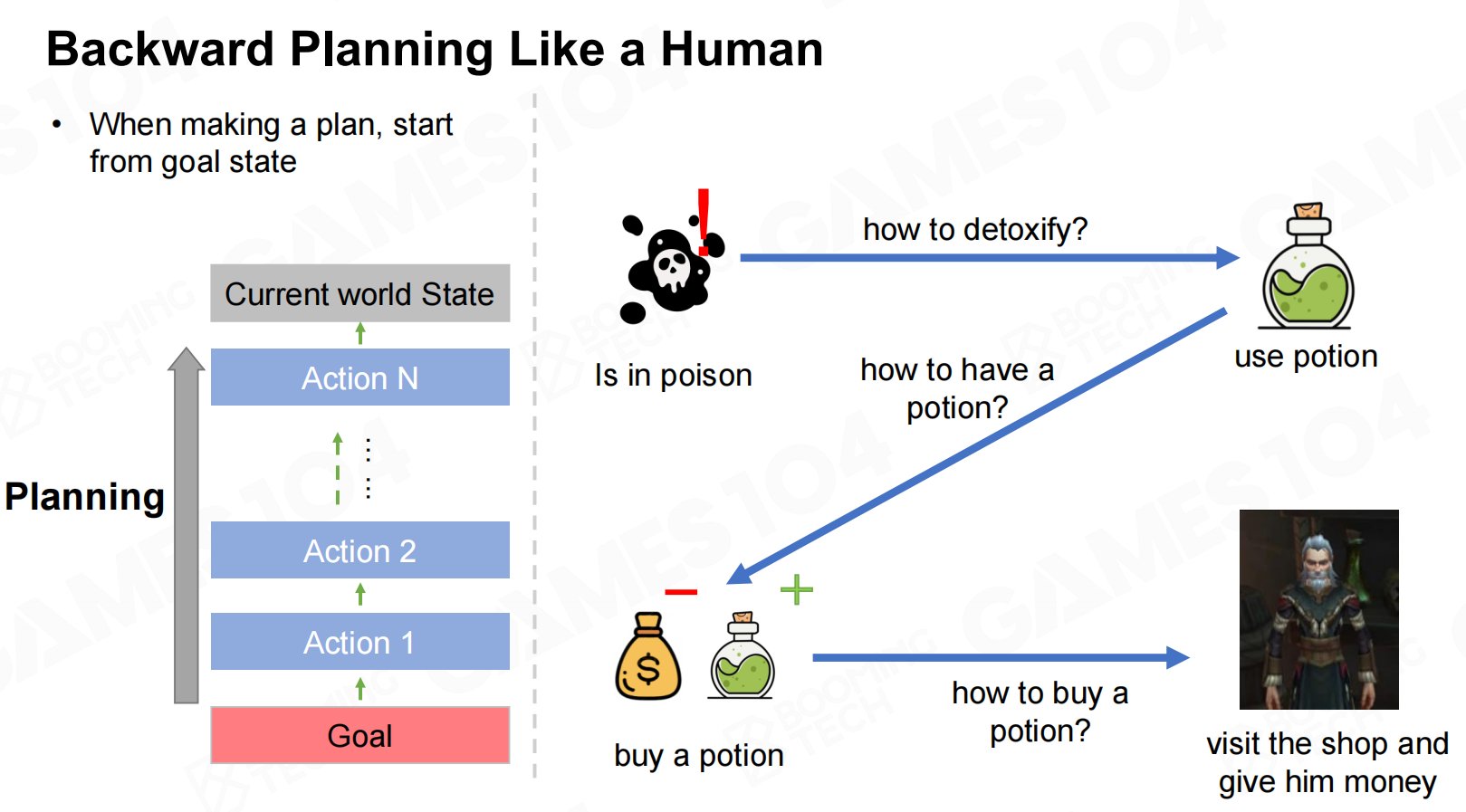 像一个人一样反向规划
像一个人一样反向规划
在进行规划时首先需要根据优先级来选取一个目标,然后查询实现目标需要满足的状态。为了满足这些状态需求,我们需要从action set中选择一系列动作。需要注意的是很多动作也有自身的状态需求,因此我们在选择动作时也需要把这些需求添加到列表中。最后不断地添加动作和需求直到所有的状态需求都得到了满足,这样就完成了反向规划。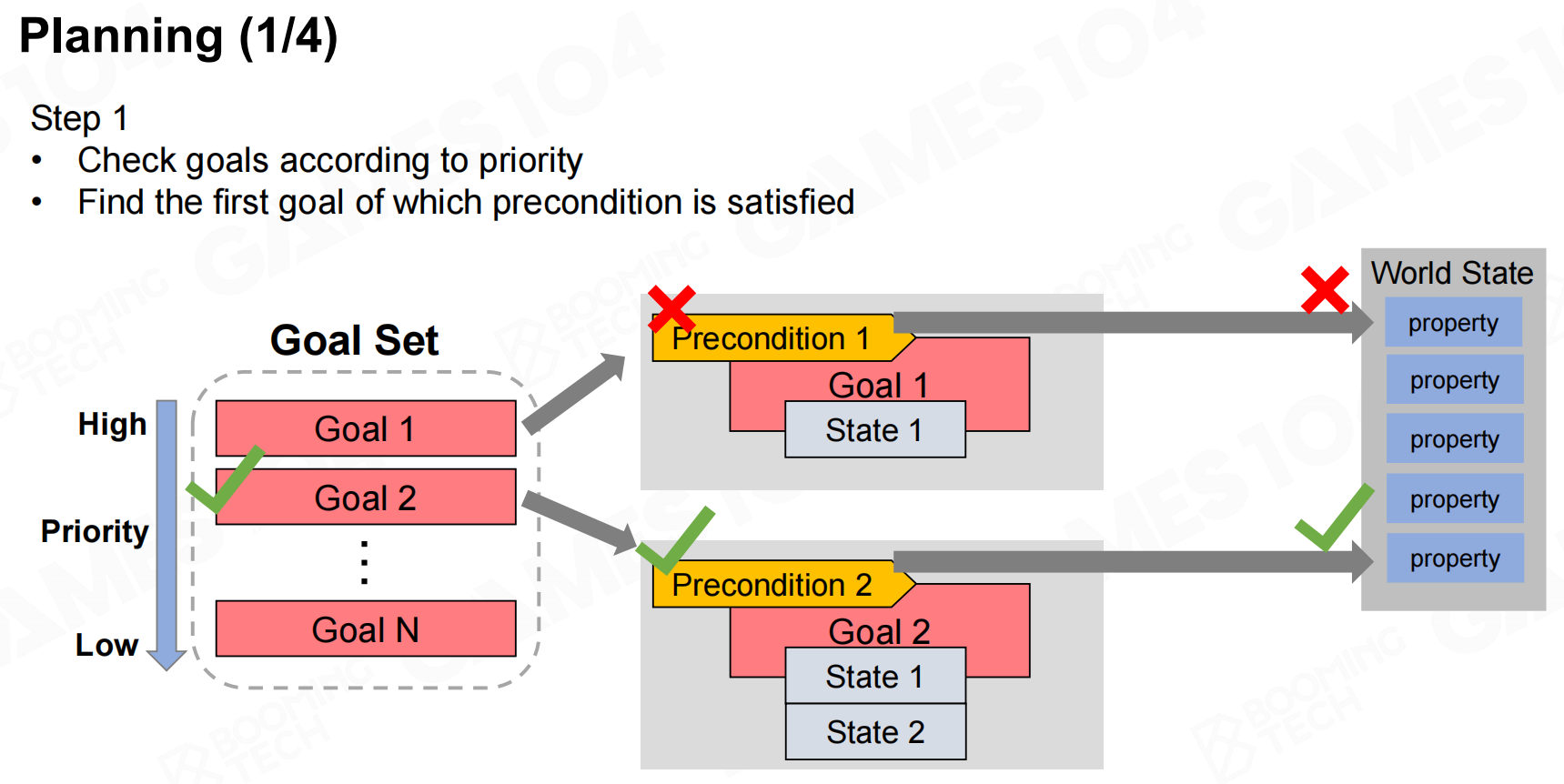 规划
规划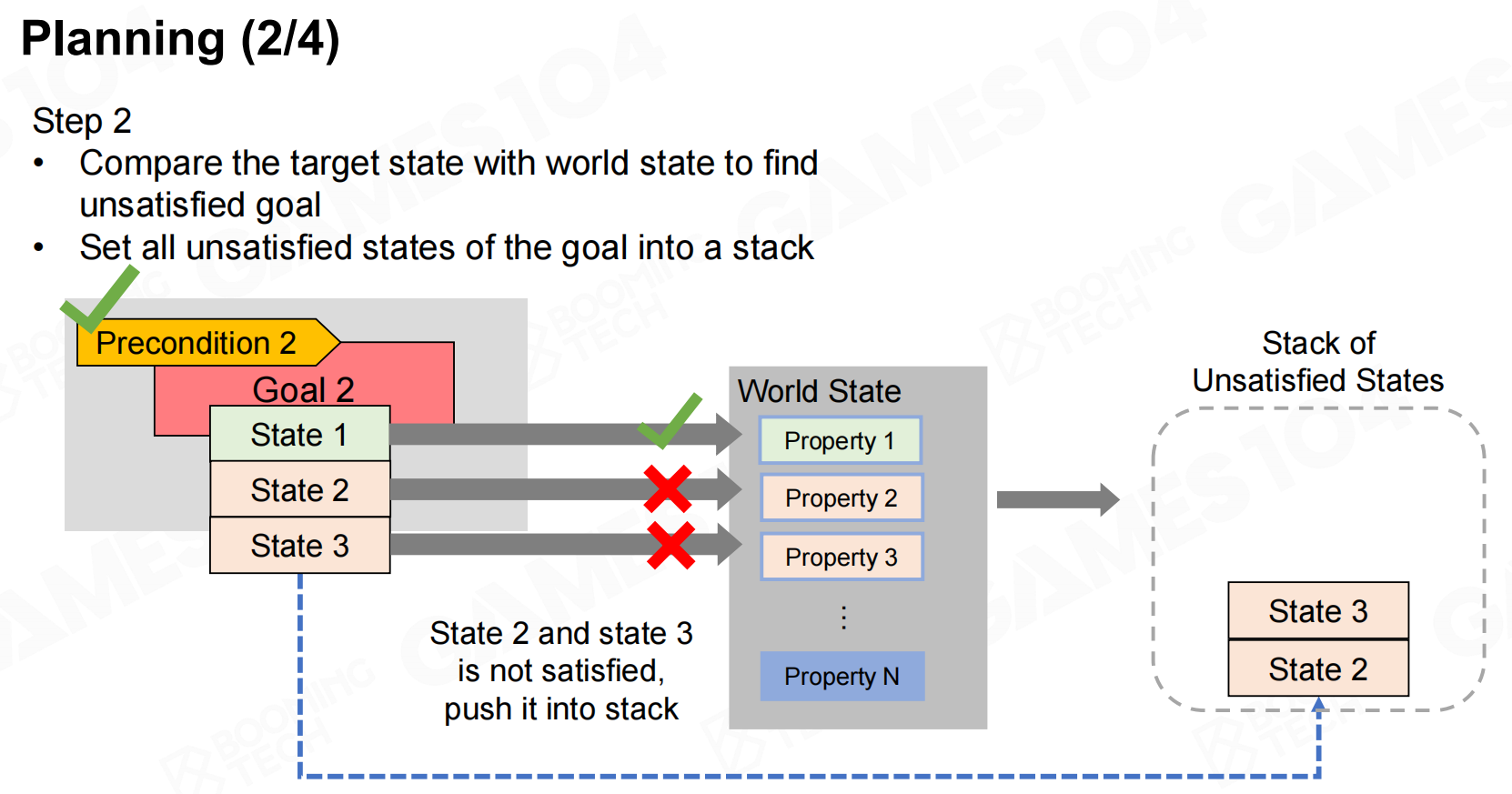 规划2
规划2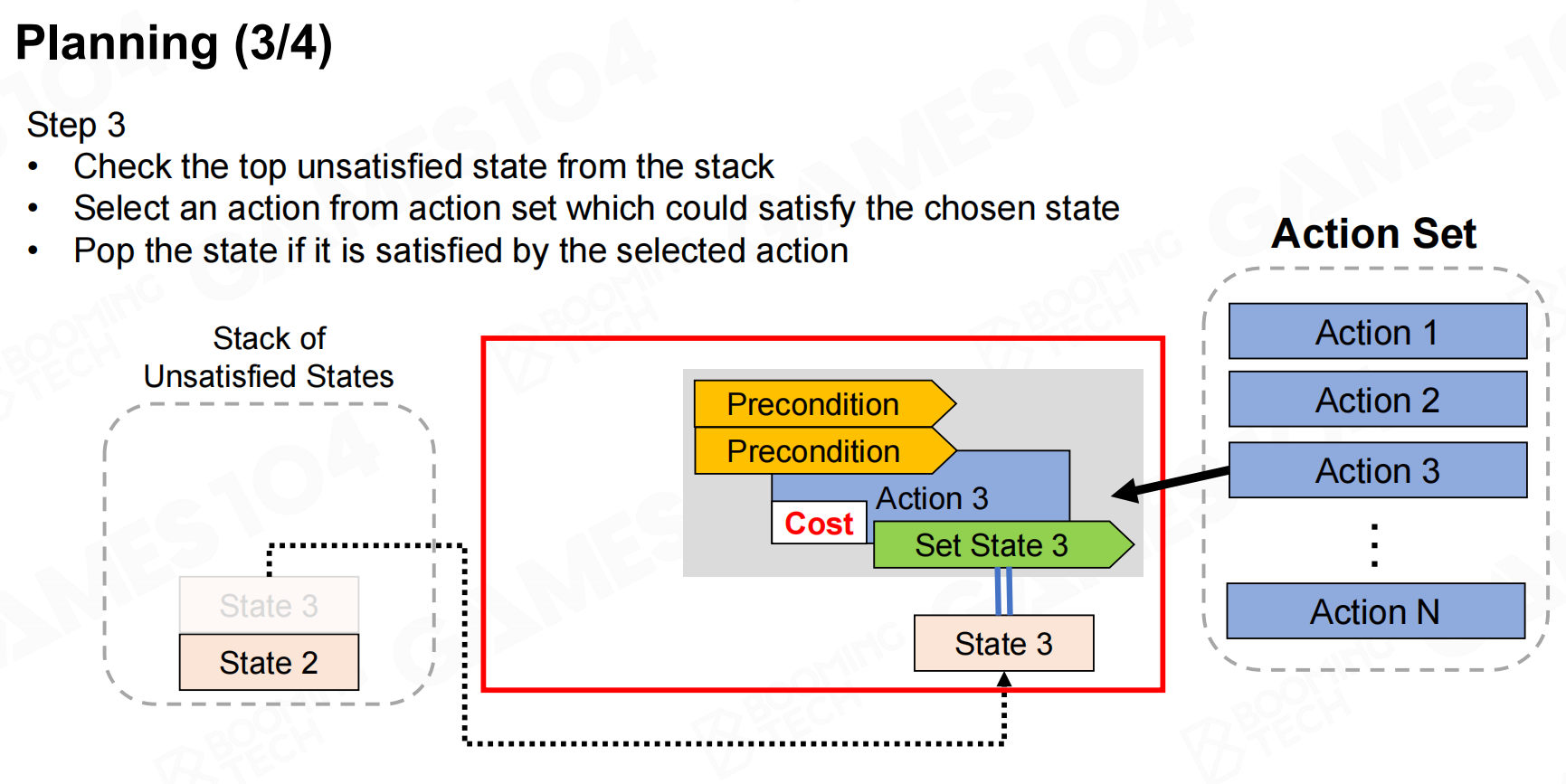 规划3
规划3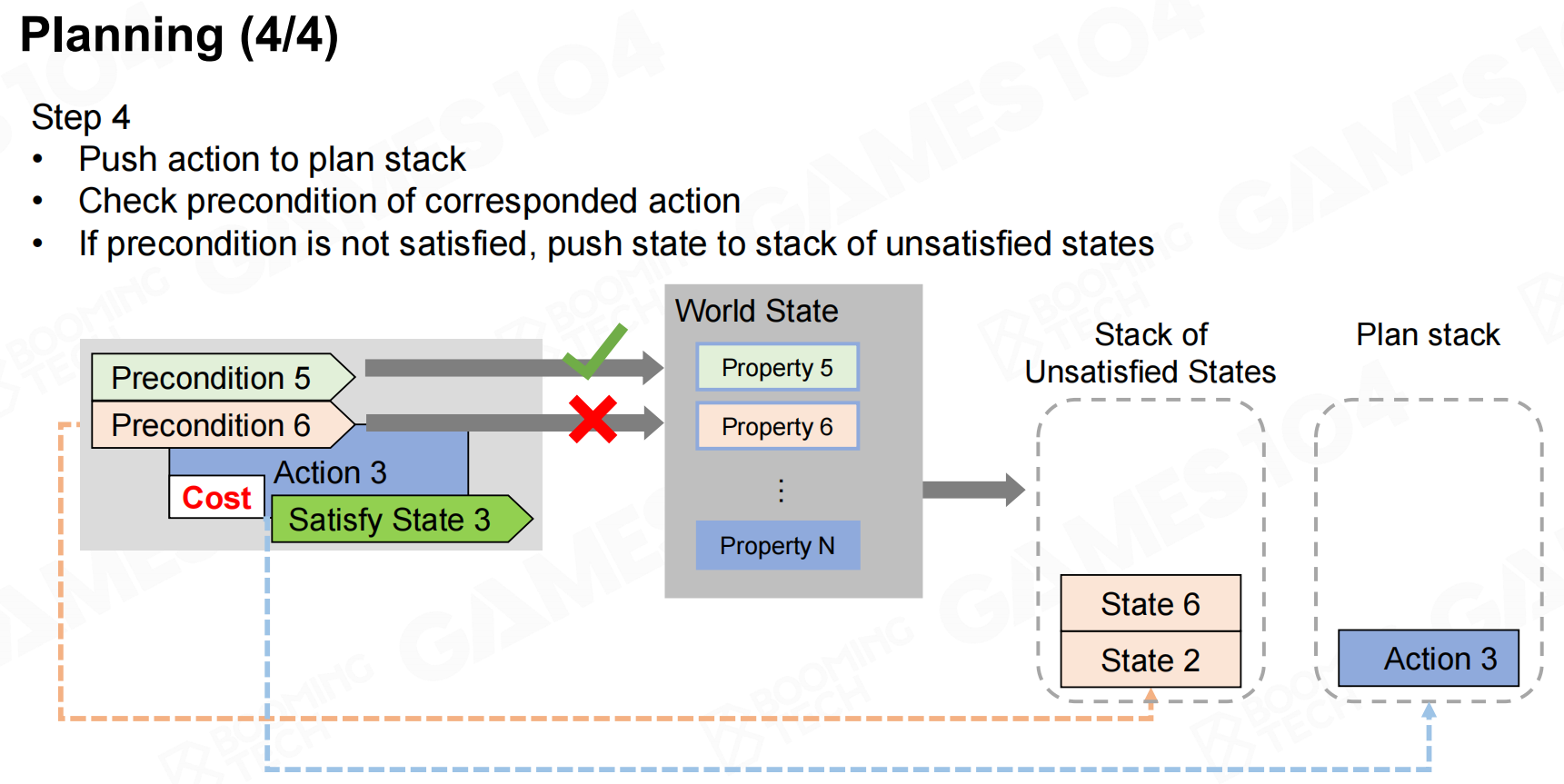 规划4
规划4
GOAP的难点在于如何从action set进行选择,我们要求状态需求都能够得到满足而且所添加动作的代价要尽可能小。显然这样的问题是一个动态规划(dynamic programming)问题,我们可以利用图这样的数据结构来进行求解。在构造图时把状态的组合作为图上的节点,不同节点之间的有向边表示可以执行的动作,边的权重则是动作的代价。这样整个规划问题就等价于在有向图上的最短路径问题。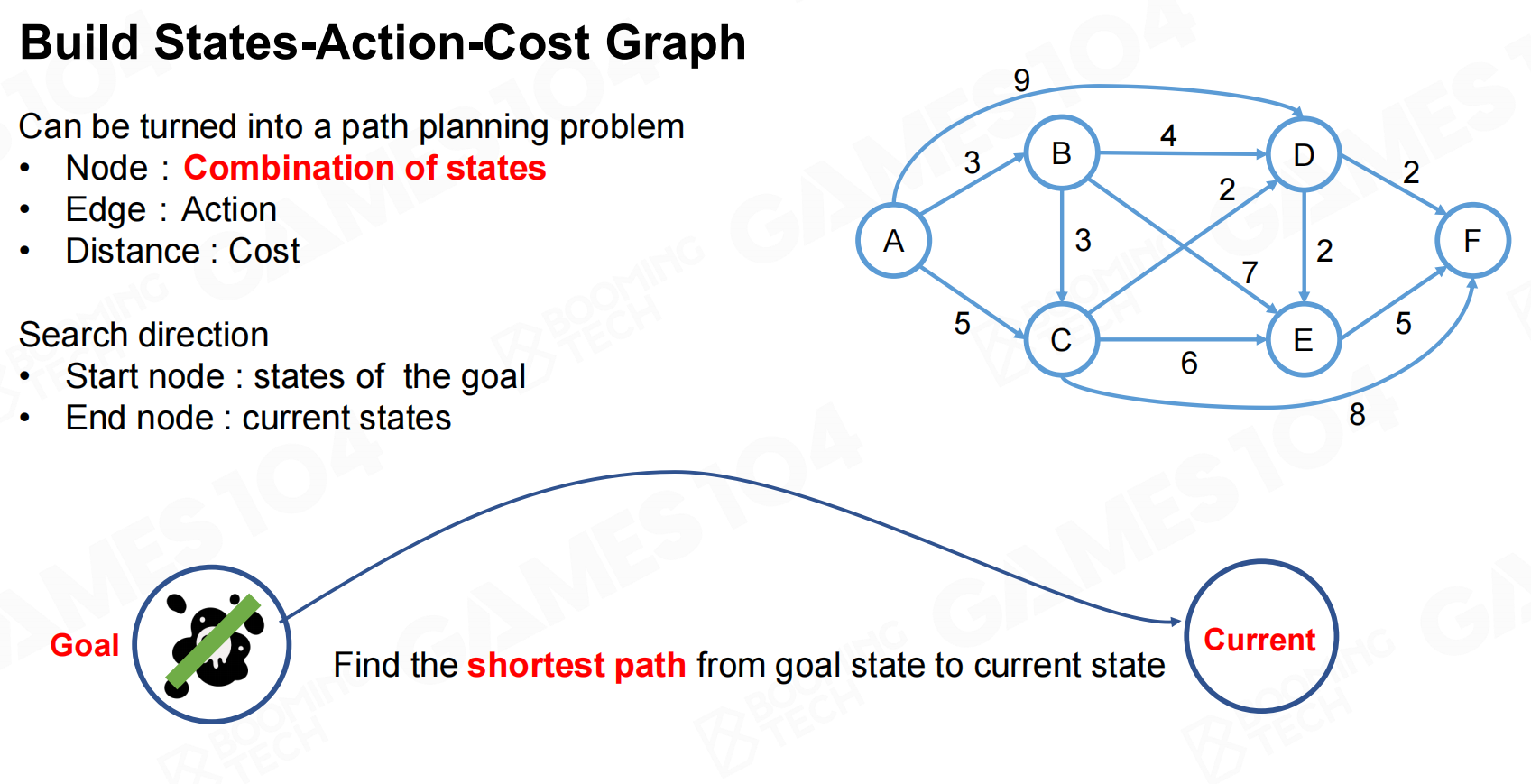 构建状态-行动成本图
构建状态-行动成本图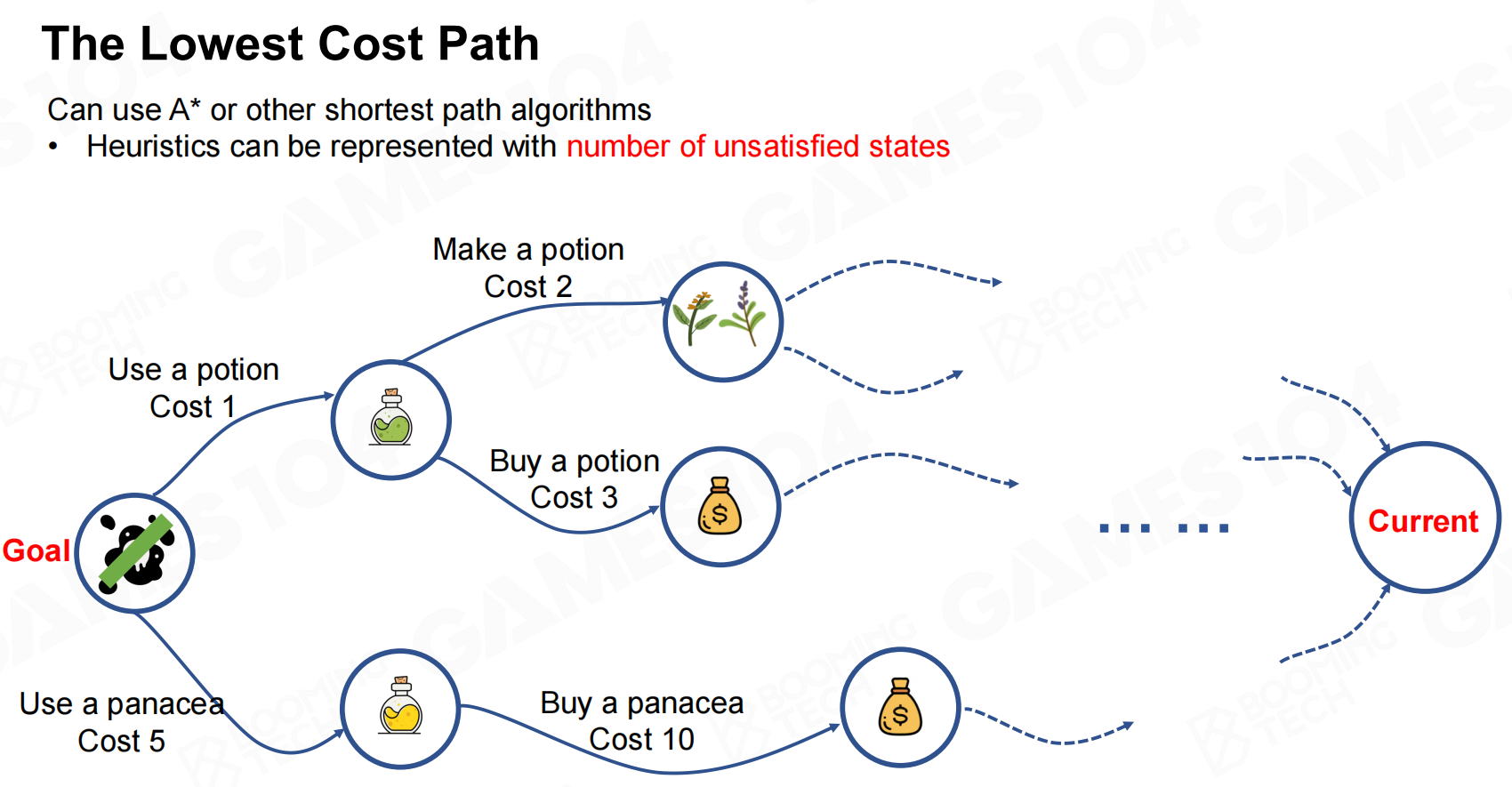 最低成本路径
最低成本路径
总结一下GOAP可以让AI的行为更加动态,而且可以有效地解耦AI的目标与行为;而GOAP的主要缺陷在于它会比较消耗计算资源,一般情况下GOAP需要的计算量会远高于BT和HTN。 总结
总结
蒙特卡洛树搜索(Monte Carlo Tree Search)
蒙特卡洛树搜索(Monte Carlo tree search, MCTS)也是经典的AI算法,实际上AlphaGo就是基于MCTS来实现的。简单来说,MCTS的思路是在进行决策时首先模拟大量可行的动作,然后从这些动作中选择最好的那个来执行。 蒙特卡洛树搜索
蒙特卡洛树搜索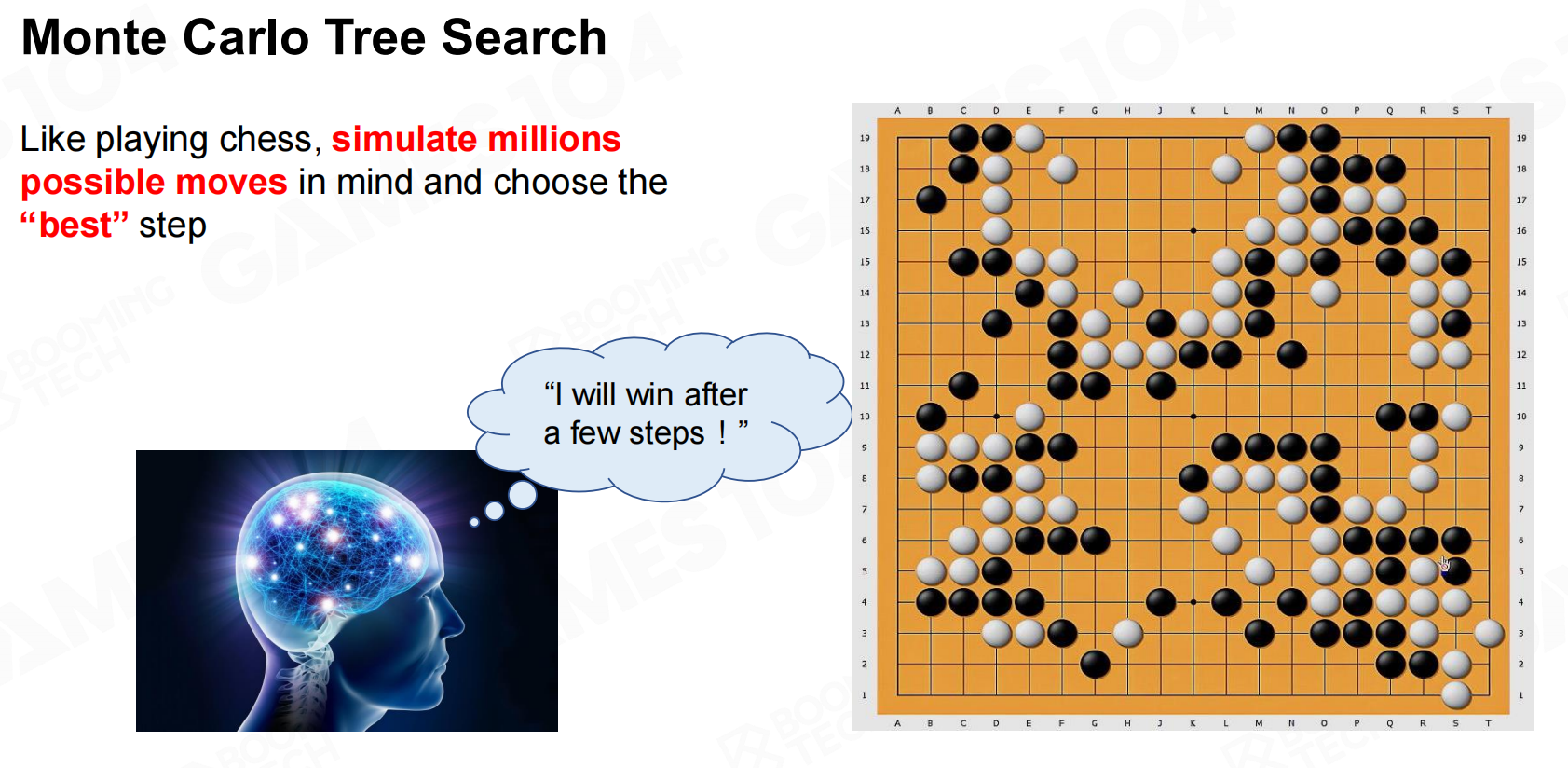 蒙特卡洛树搜索2
蒙特卡洛树搜索2
MCTS的核心是Monte Carlo方法(Monte Carlo method),它指出定积分可以通过随机采样的方法来进行估计。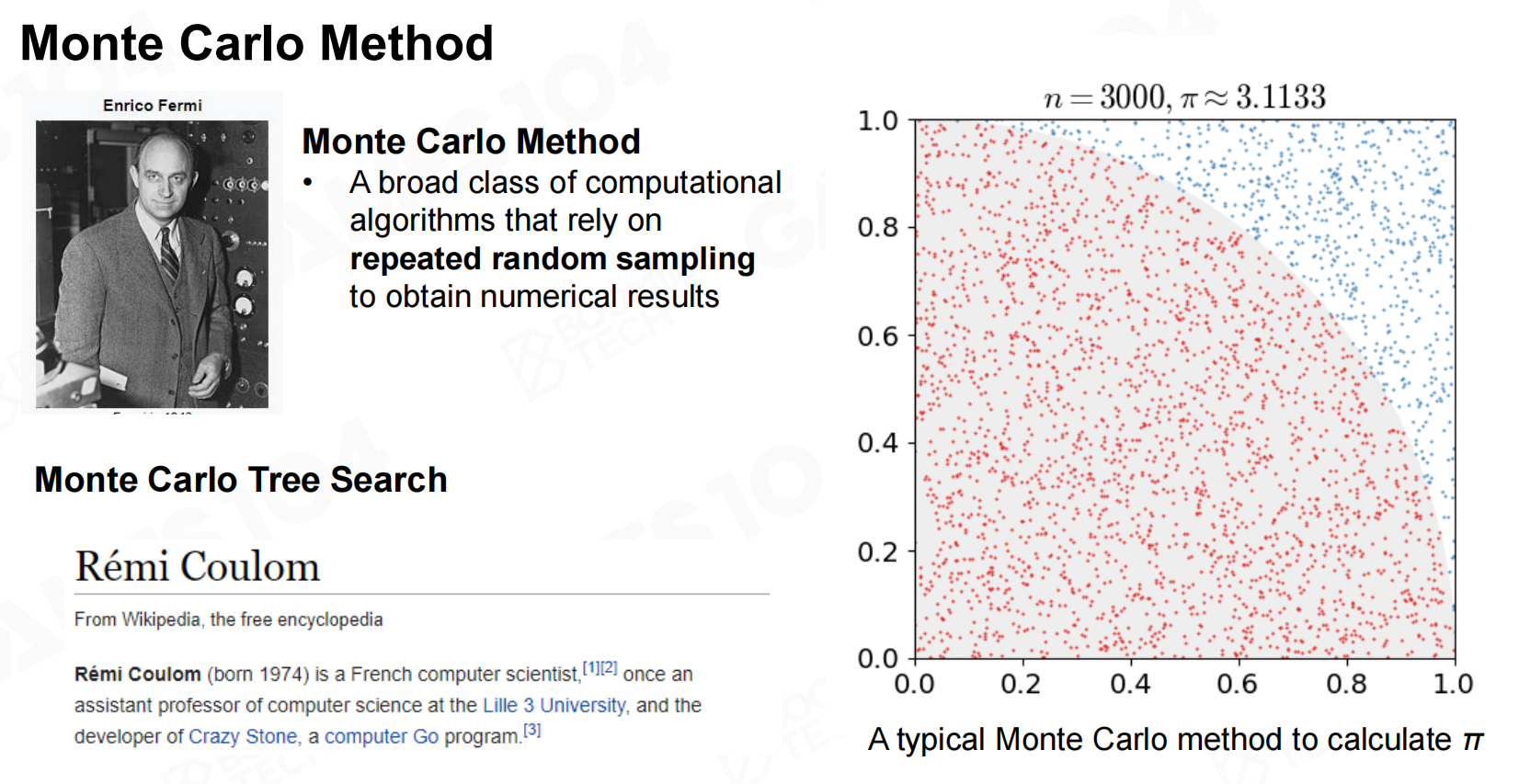 Monte Carlo方法
Monte Carlo方法
以围棋为例,MCTS会根据当前棋盘上的状态来估计落子的位置。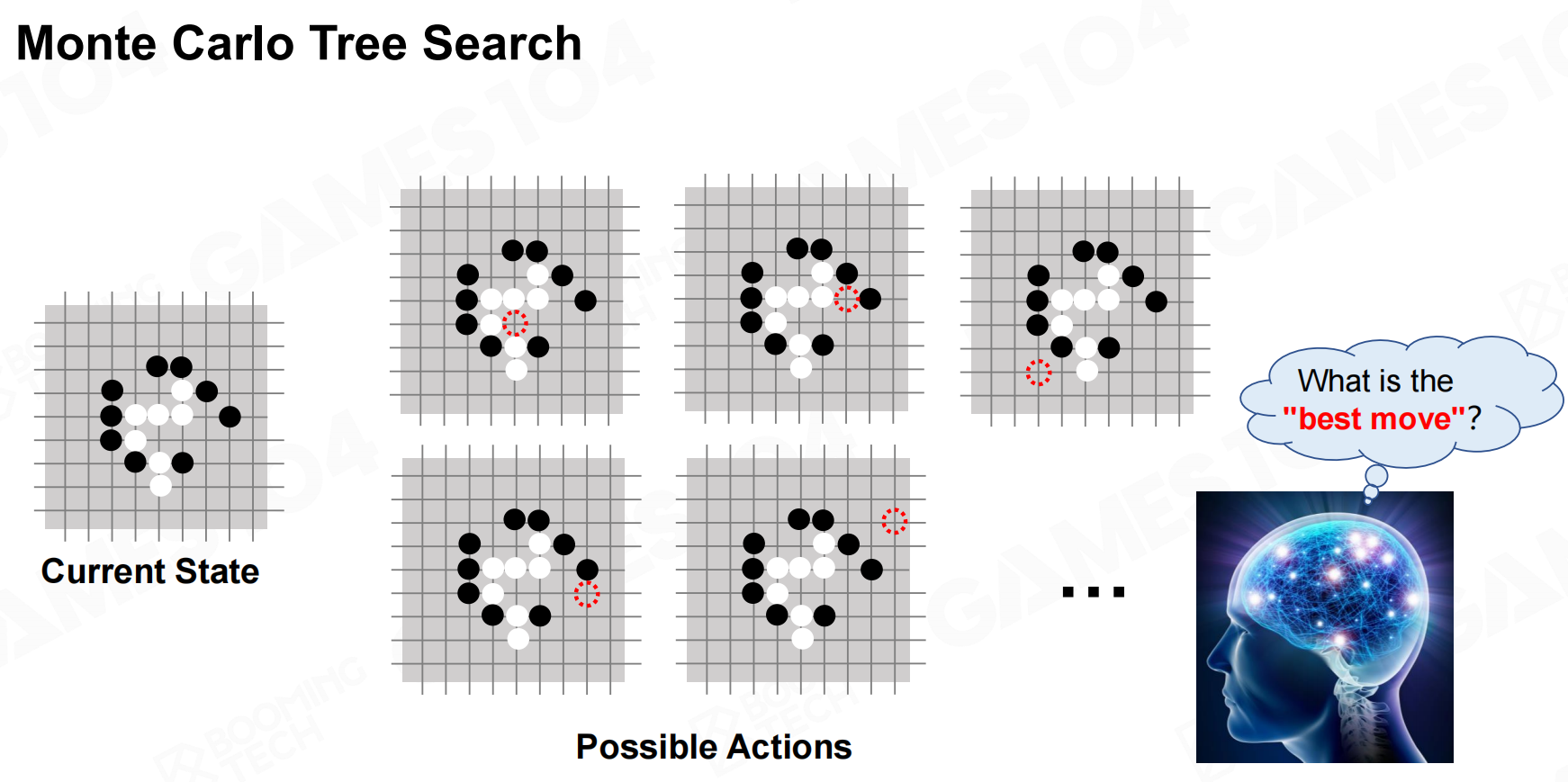 蒙特卡洛树搜索3
蒙特卡洛树搜索3
从数学的角度来看,我们把棋盘上棋子的位置称为状态(state),同时把落子的过程称为行为(action)。这样整个游戏可以建模为从初始节点出发的状态转移过程,而且所有可能的状态转移可以表示为一棵树。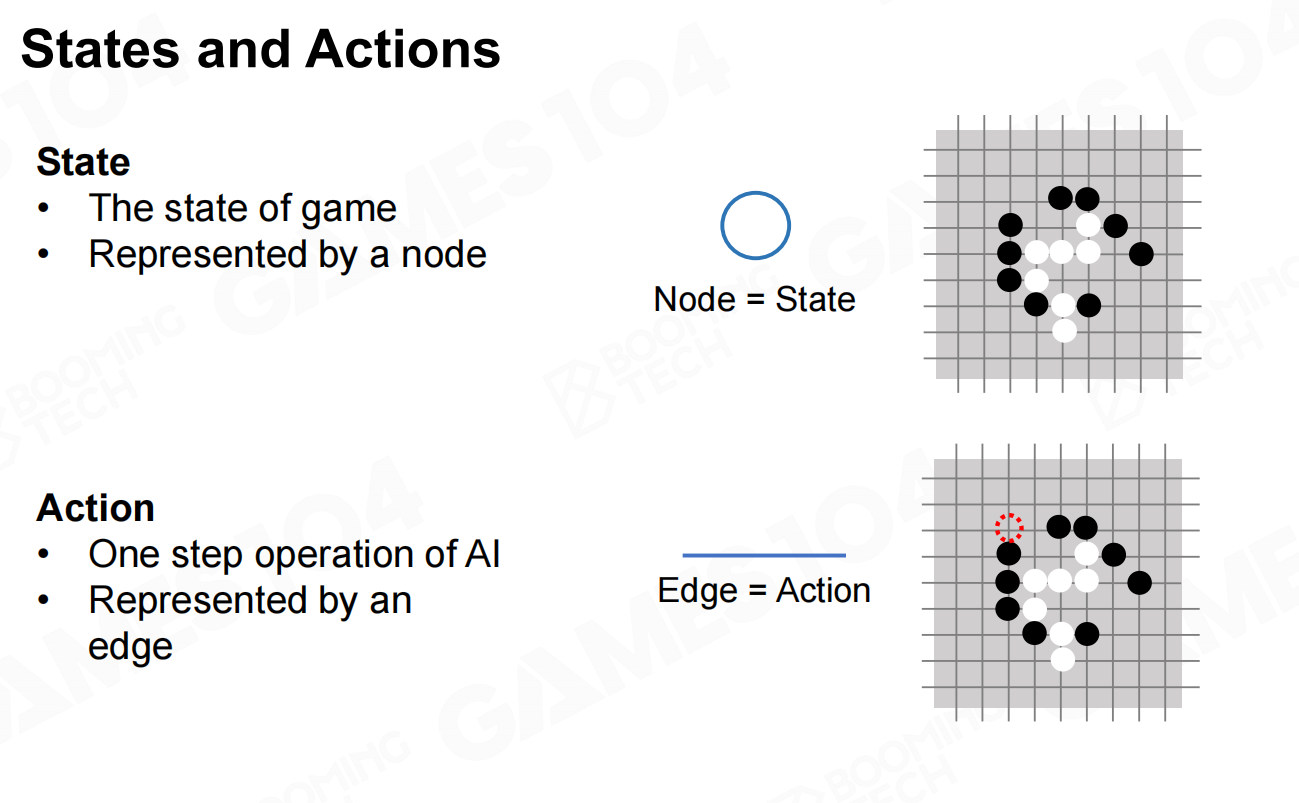 状态和行动
状态和行动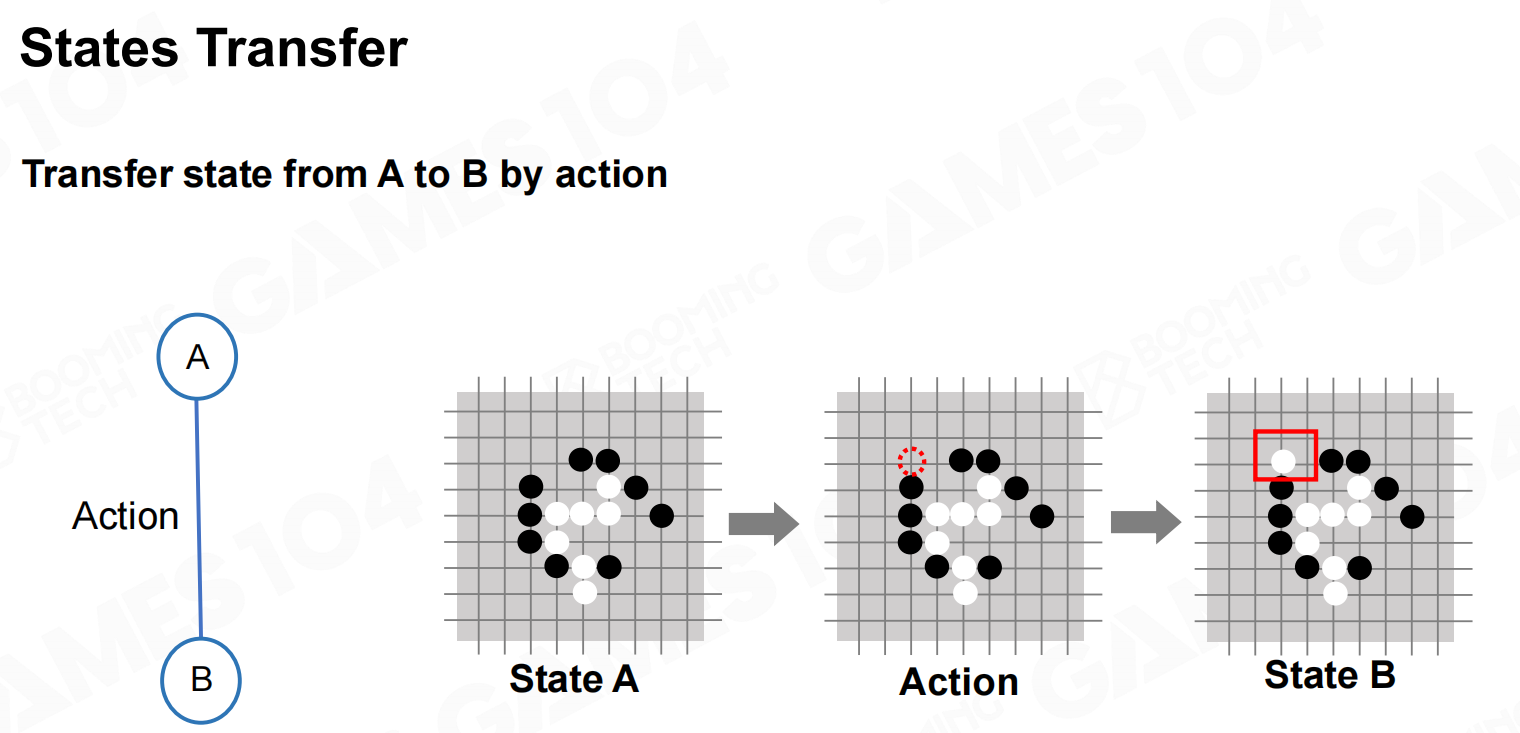 状态转移
状态转移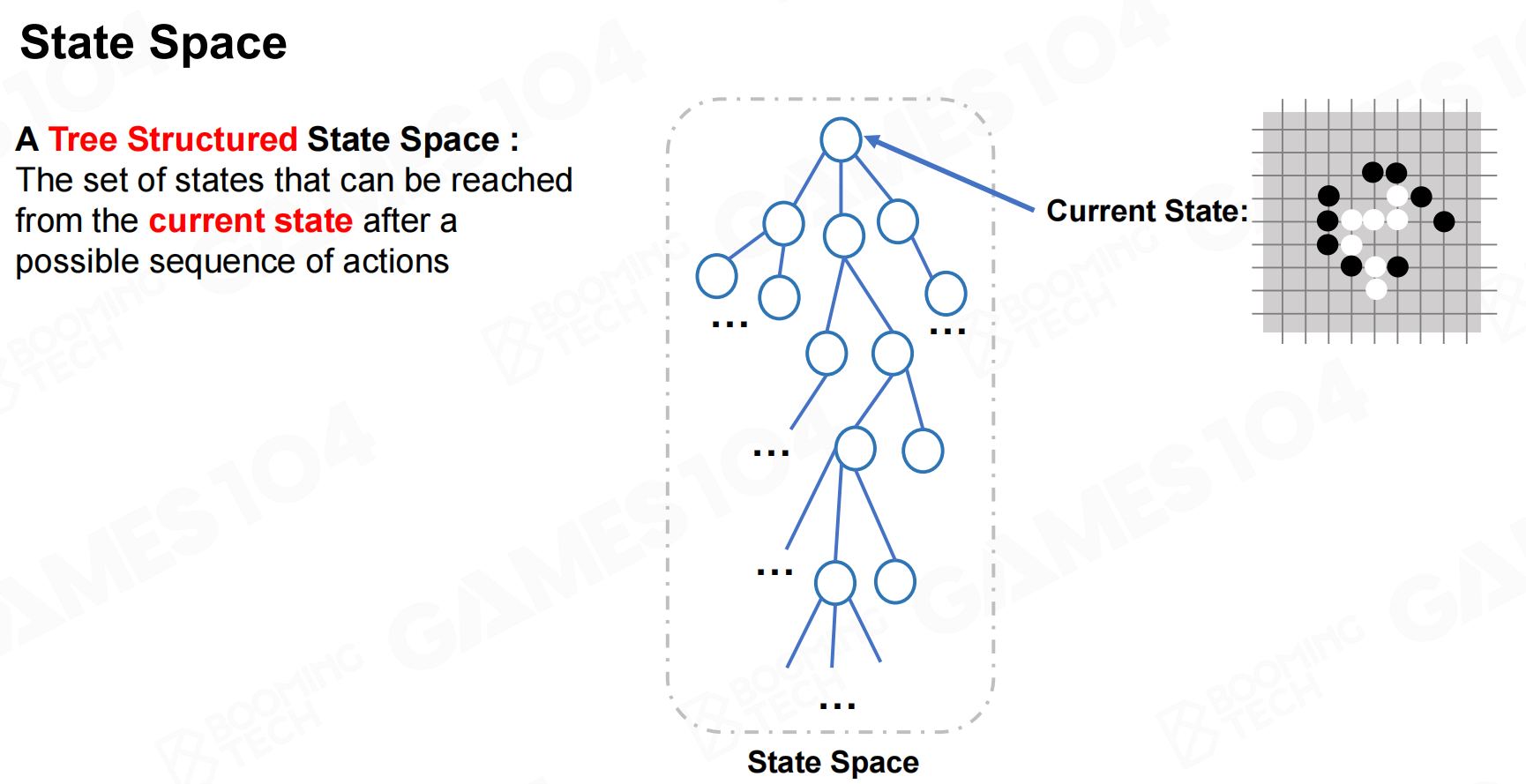 状态空间
状态空间
显然构造出完整的树结构可能是非常困难的,不过实际上我们并不需要完整的树。在使用MCTS时,完成每一个行为后只需要重新以当前状态构造一棵新树即可。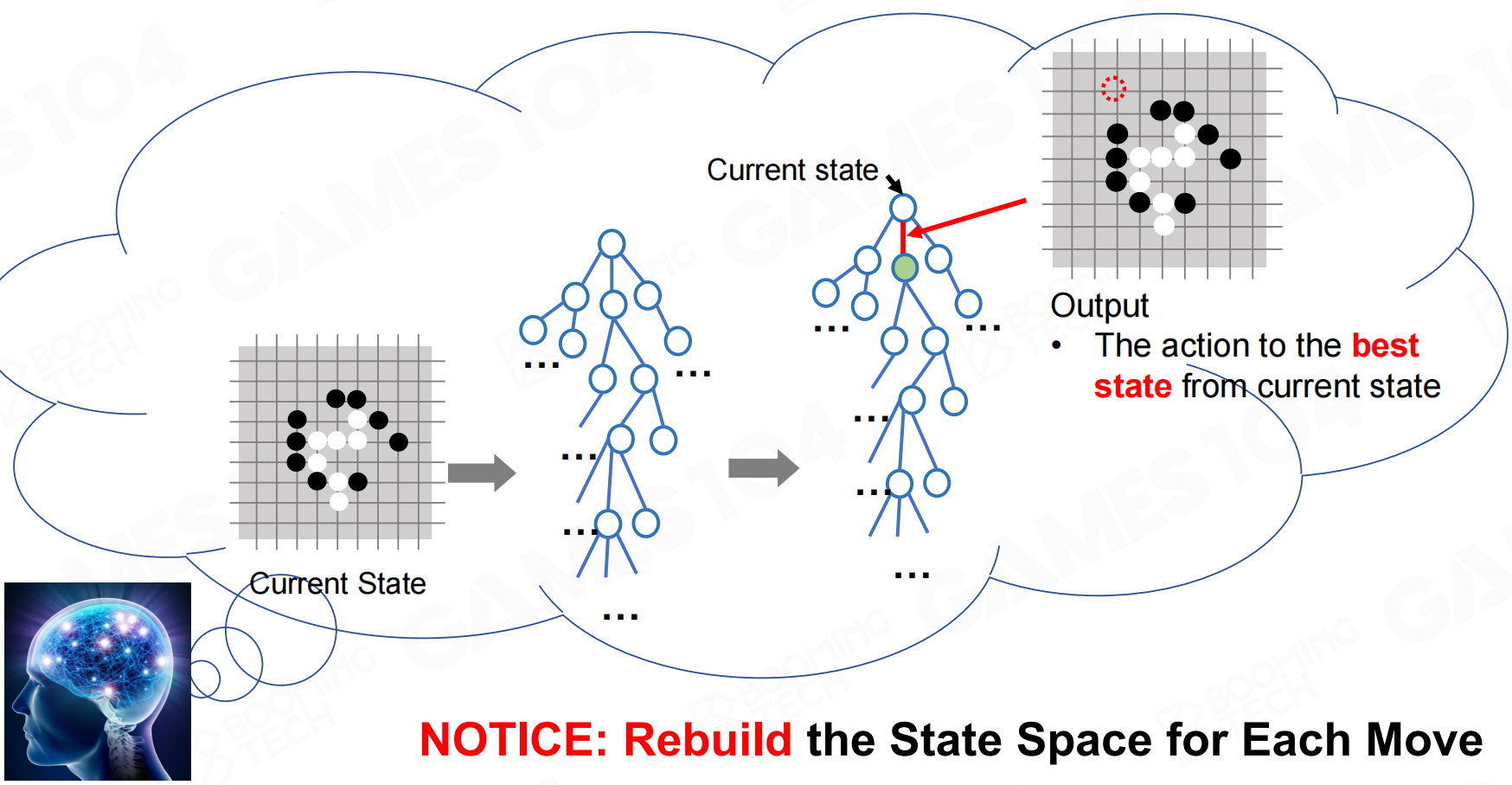 注意:重建每次移动重建状态空间
注意:重建每次移动重建状态空间
模拟(Simulation)
模拟(simulation)是MCTS中的重要一环,这里的”模拟”是指AI利用当前的策略快速地完成整个游戏过程。 模拟:快速地玩游戏
模拟:快速地玩游戏
反向传播(Backpropagate)
我们从同一节点出发进行不断的模拟就可以估计该节点的价值(胜率)。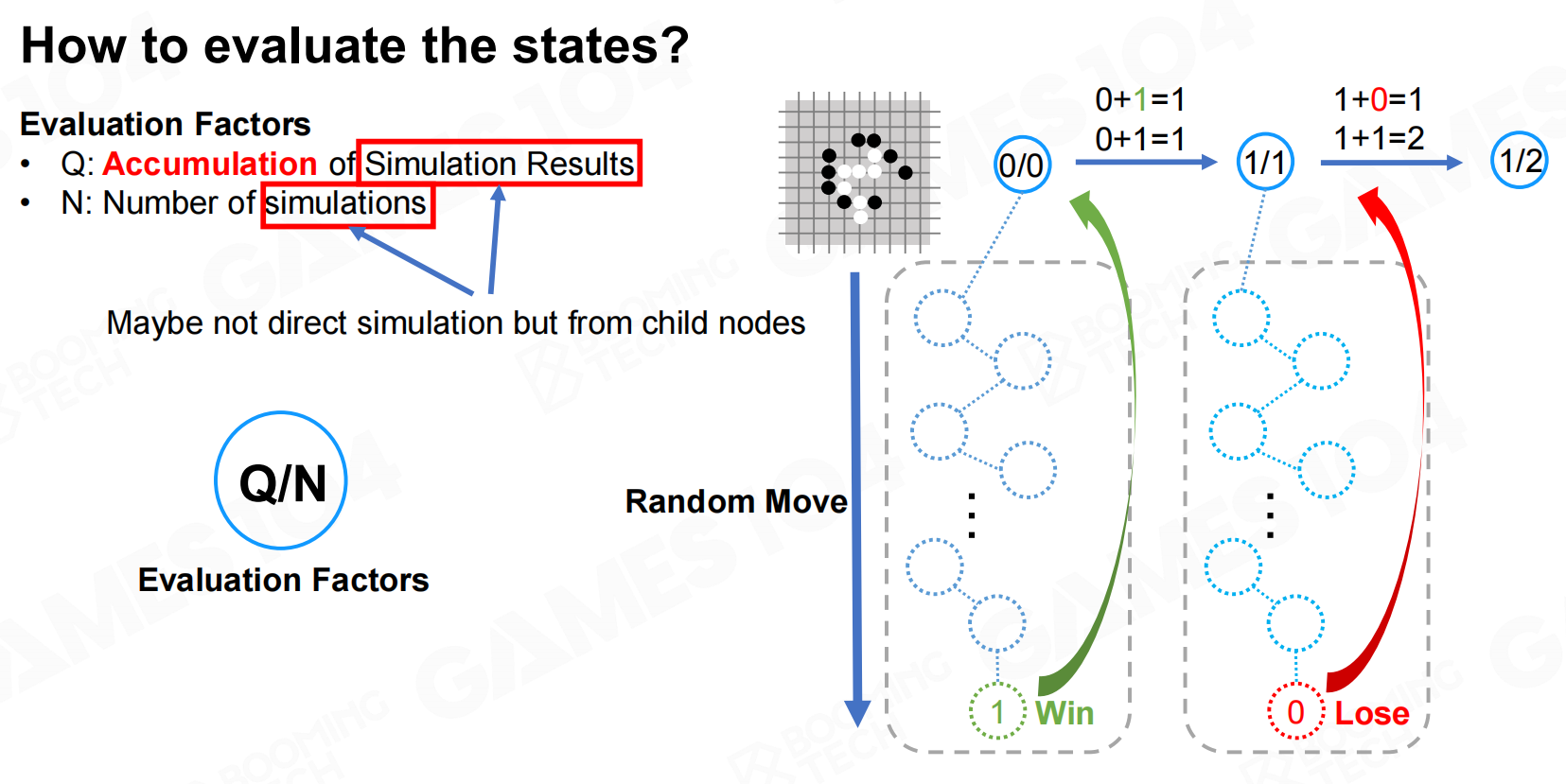 如何评估这些状态?
如何评估这些状态?
然后把模拟的结果从下向上进行传播就可以更新整个决策序列上所有节点的价值。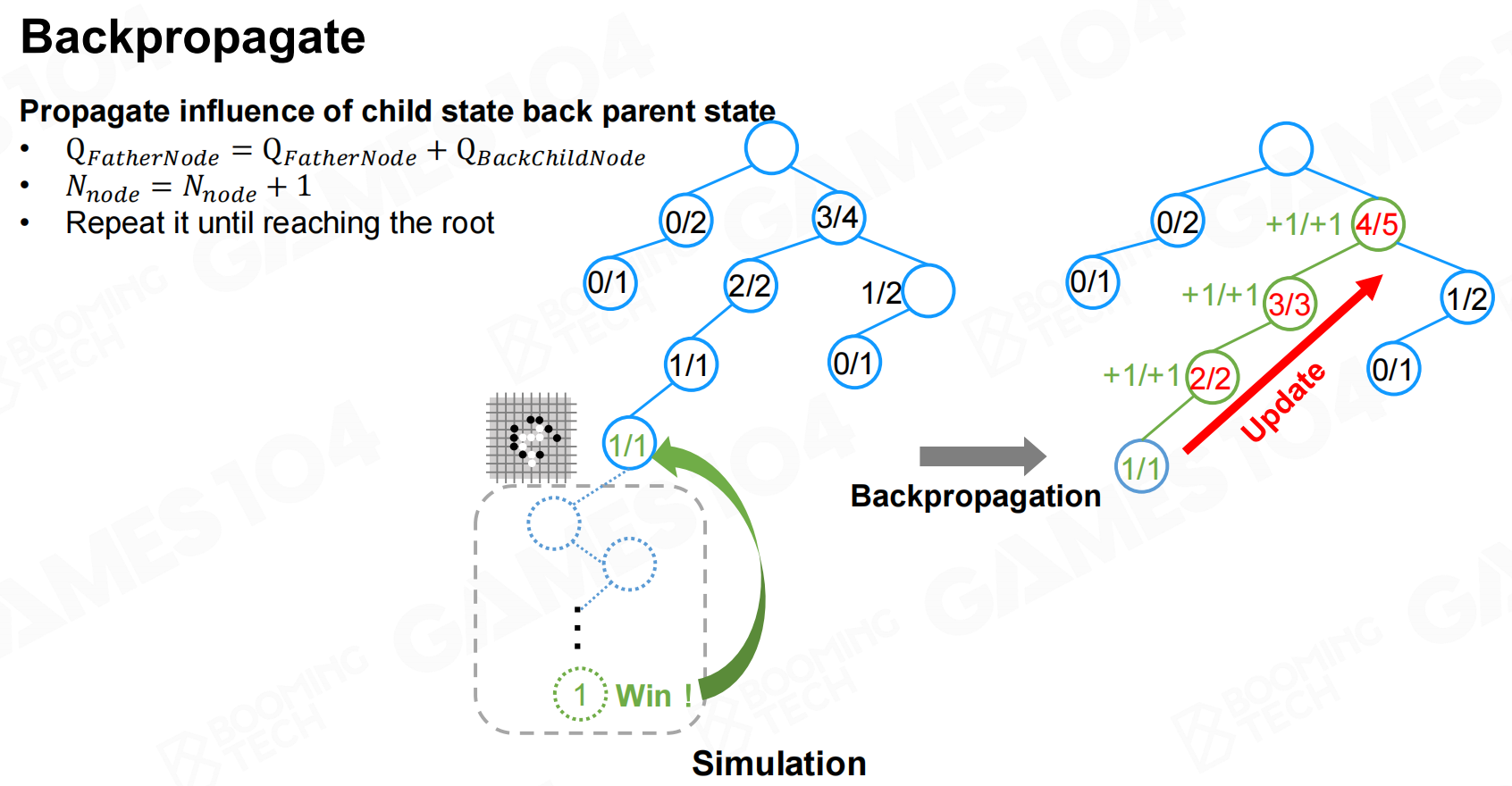 反向传播
反向传播
迭代步骤(Iteration Steps)
这样我们就可以定义MCTS的迭代步骤如下: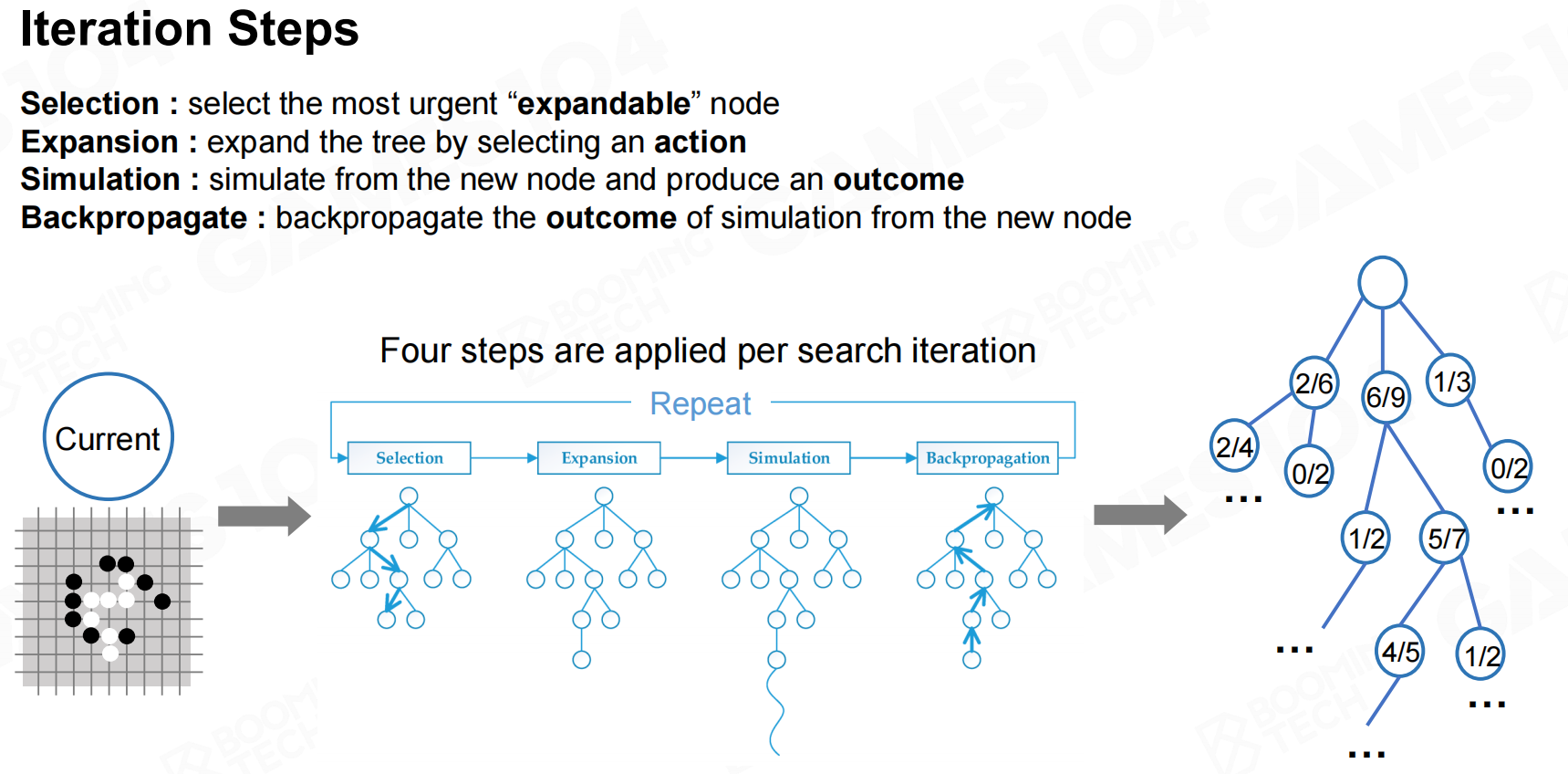 迭代步骤
迭代步骤 在“无限”状态空间中进行搜索
在“无限”状态空间中进行搜索
选择(Selection)
在对节点进行选择时,MCTS会优先选择可拓展的节点。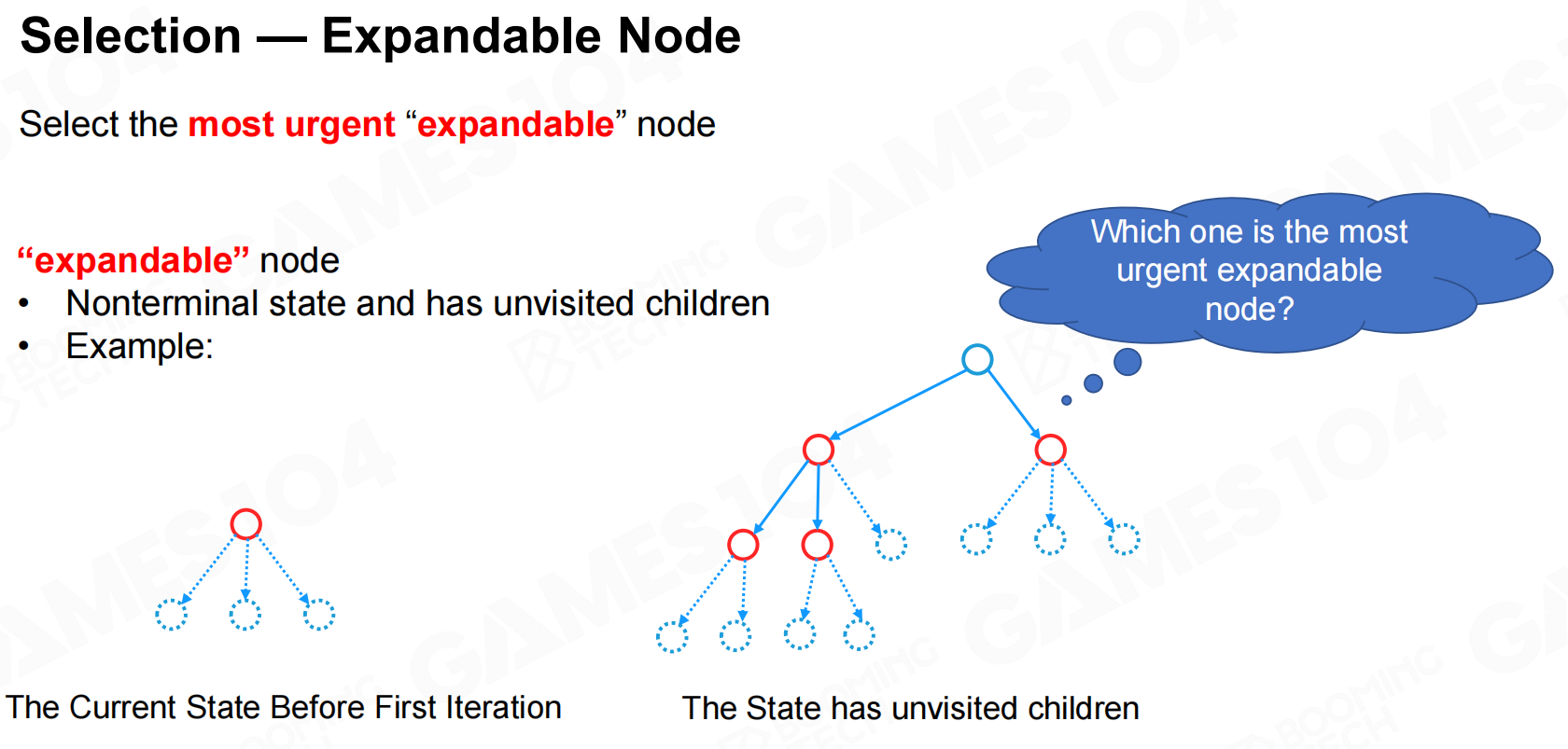 选择-可扩展节点
选择-可扩展节点
在进行拓展时往往还要权衡一些exploitation和exploration,因此我们可以把UCB可以作为一种拓展的准则。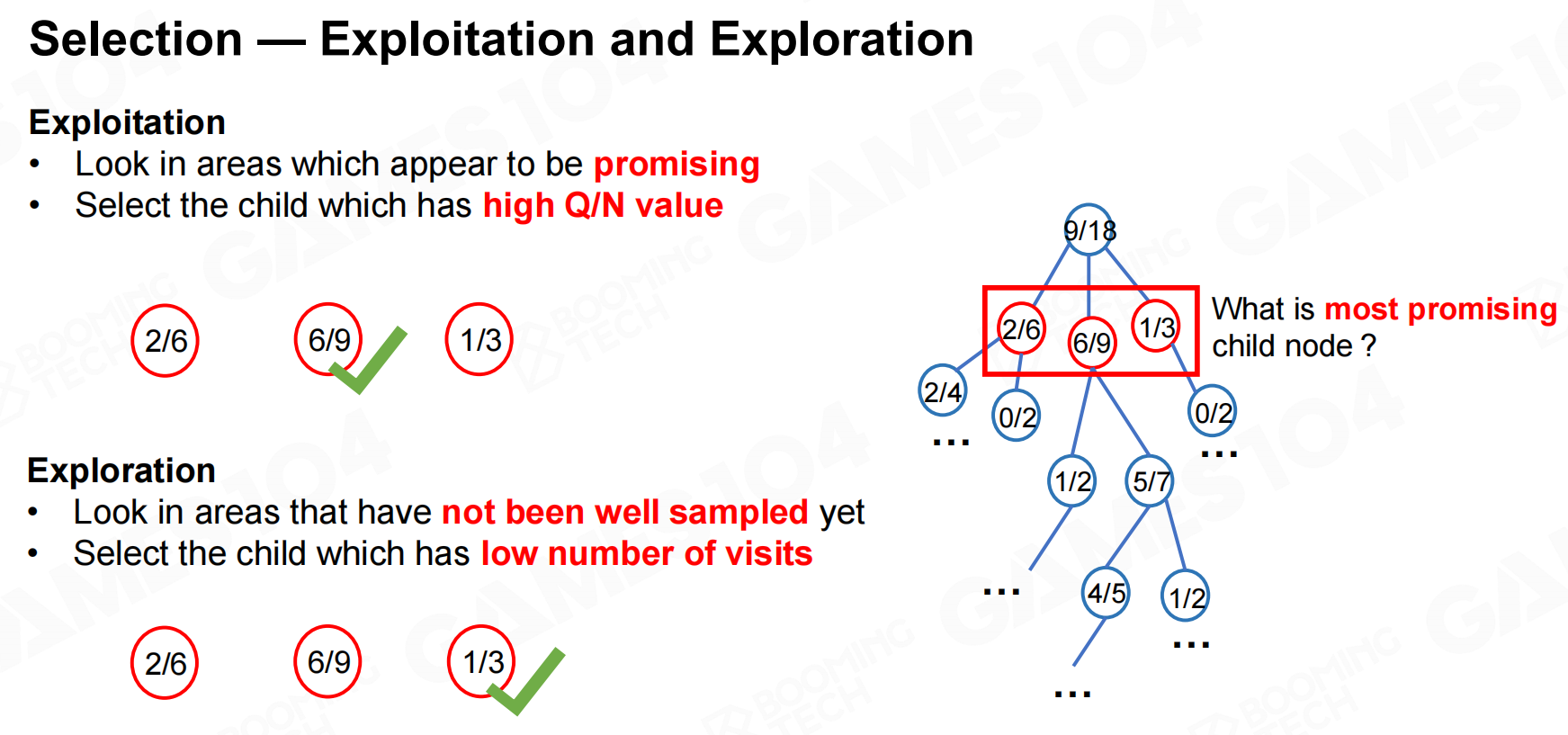 选择-开发与勘探
选择-开发与勘探 UCB(上置信度区间)
UCB(上置信度区间)
这样在进行选择时首先需要从根节点出发然后不断选择当前UCB最大的那个节点向下进行访问,当访问到一个没有拓展过的节点时选择该节点进行展开。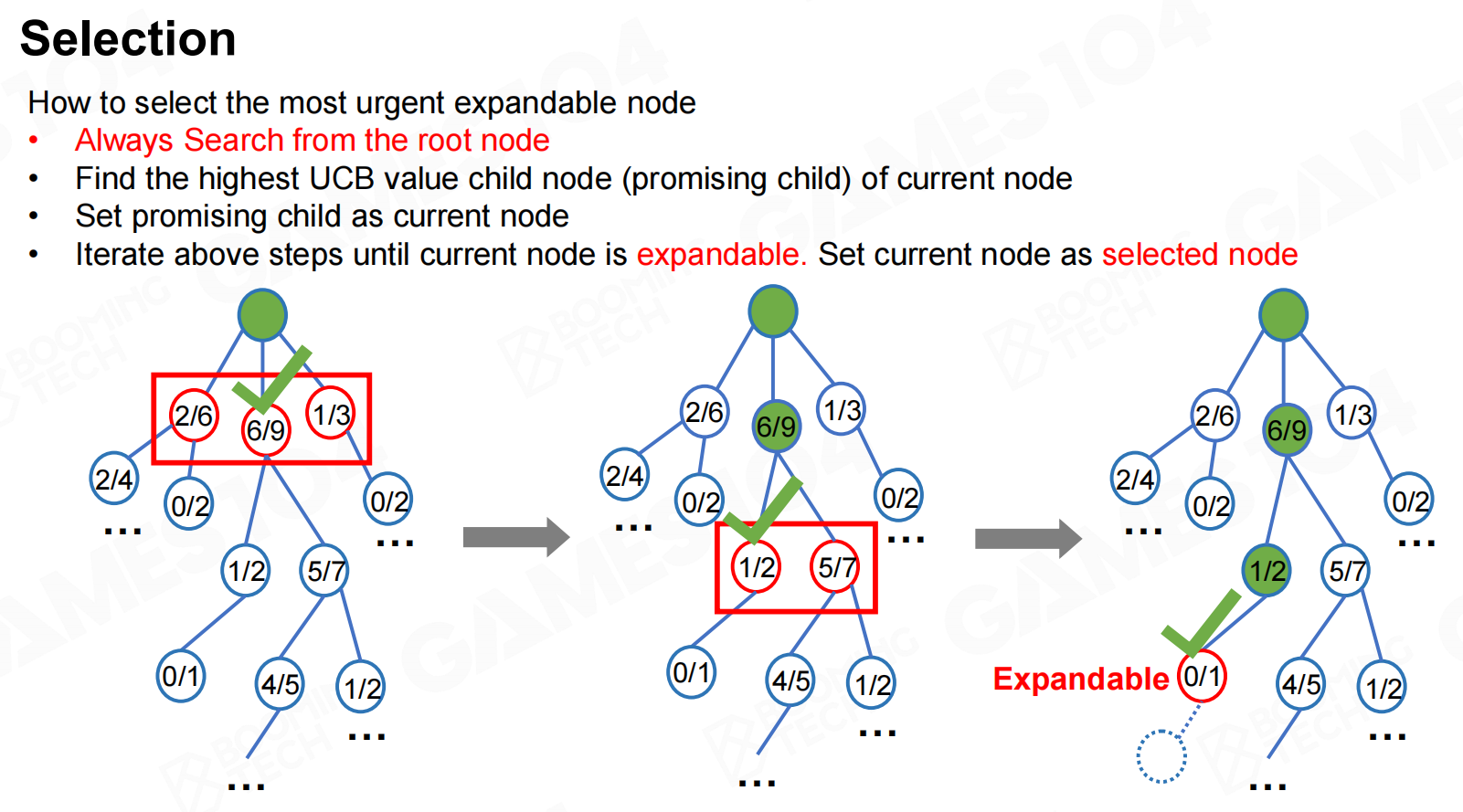 选择
选择
拓展(Expansion)
对节点进行展开时我们需要根据可执行的动作选择一组进行模拟,然后把模拟的结果自下而上进行传播。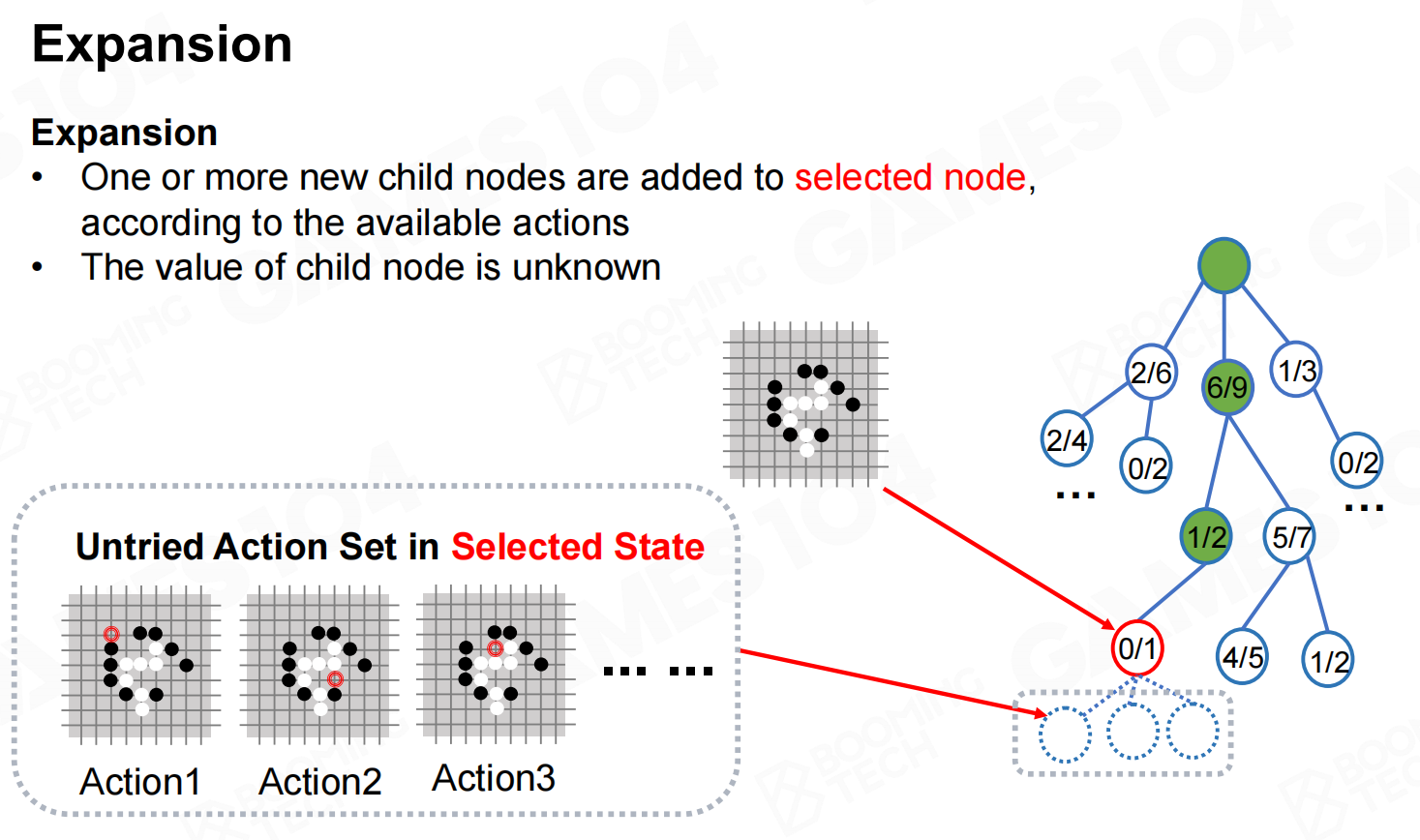 拓展
拓展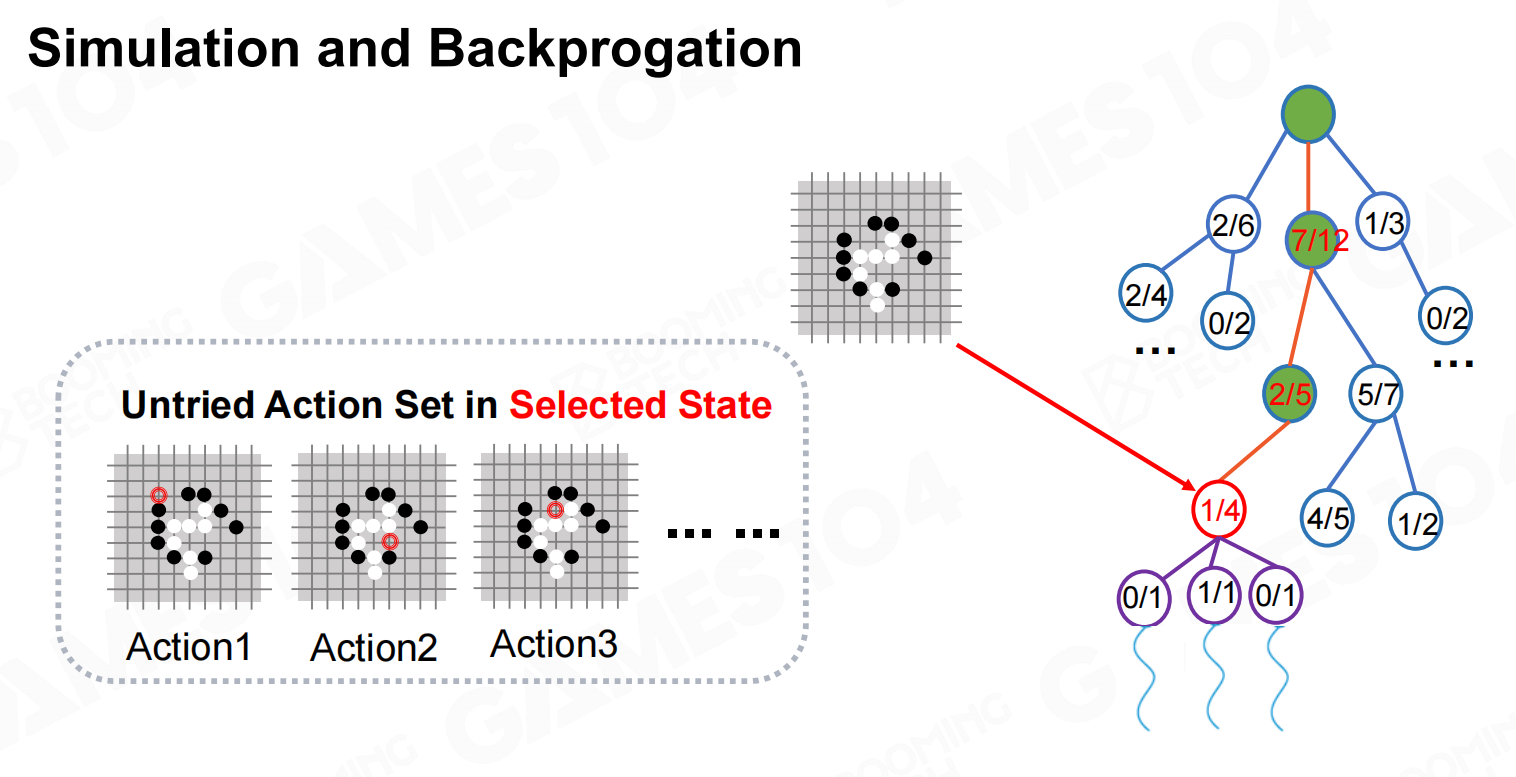 模拟和回溯
模拟和回溯
最终条件(The End Condition)
当对树的探索达到一定程度后就可以终止拓展过程,此时我们就得到了树结构上每个节点的价值。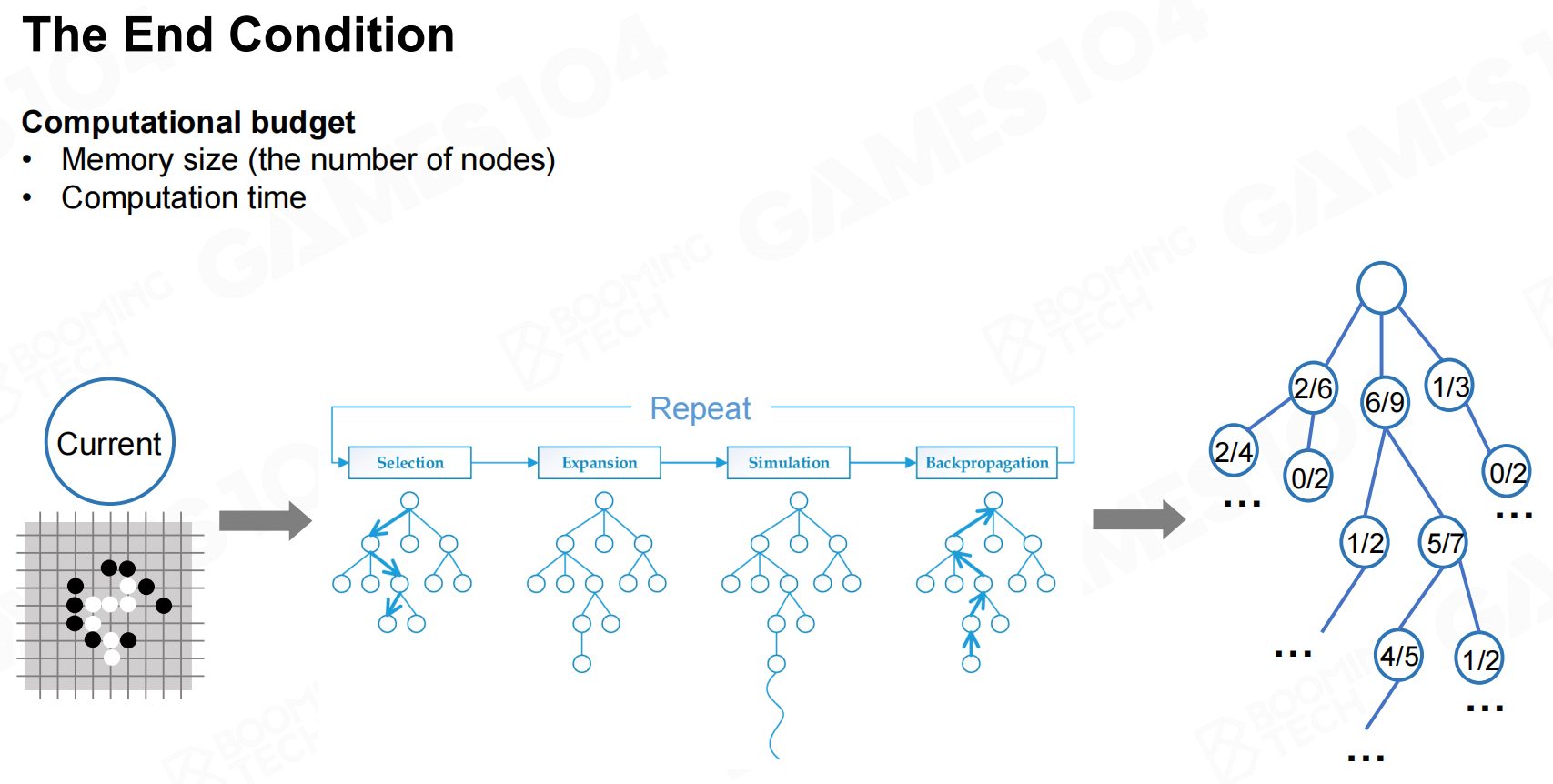 最终条件
最终条件
然后只需要回到根节点选择一个最优的子节点进行执行即可。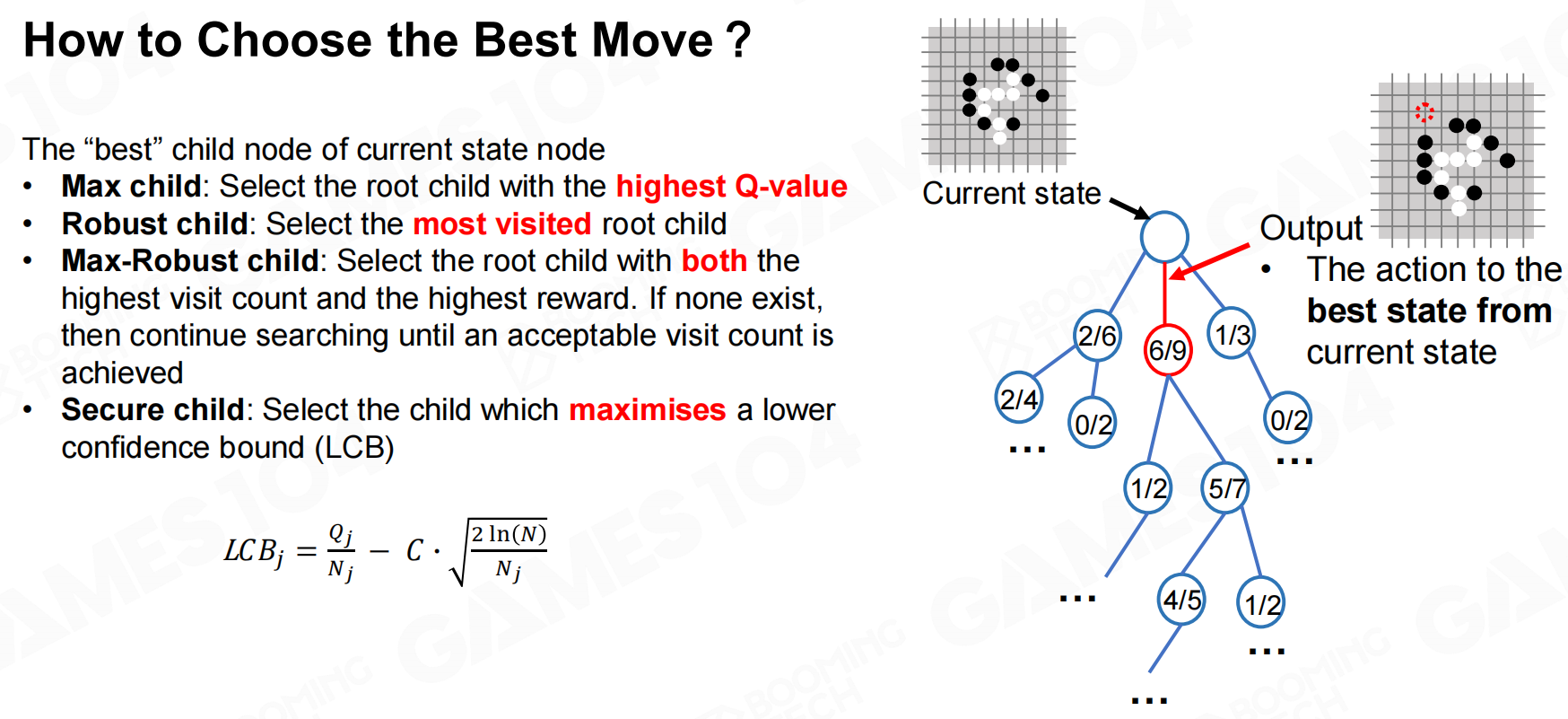 如何选择最好的移动?
如何选择最好的移动?
总结一下,MCTS是一种非常强大的决策算法而且很适合搜索空间巨大的决策问题;而它的主要缺陷在于它具有过大的计算复杂度,而且它的效果很大程度上依赖于状态和行为空间的设计。 总结
总结
机器学习基础(Machine Learning Basic)
机器学习技术(ML Types)
近几年在机器学习(machine learning, ML)技术的不断发展下有越来越多的游戏AI开始使用机器学习来进行实现。根据学习的方式,机器学习大致可以分为监督学习、无监督学习、半监督学习以及强化学习等几类。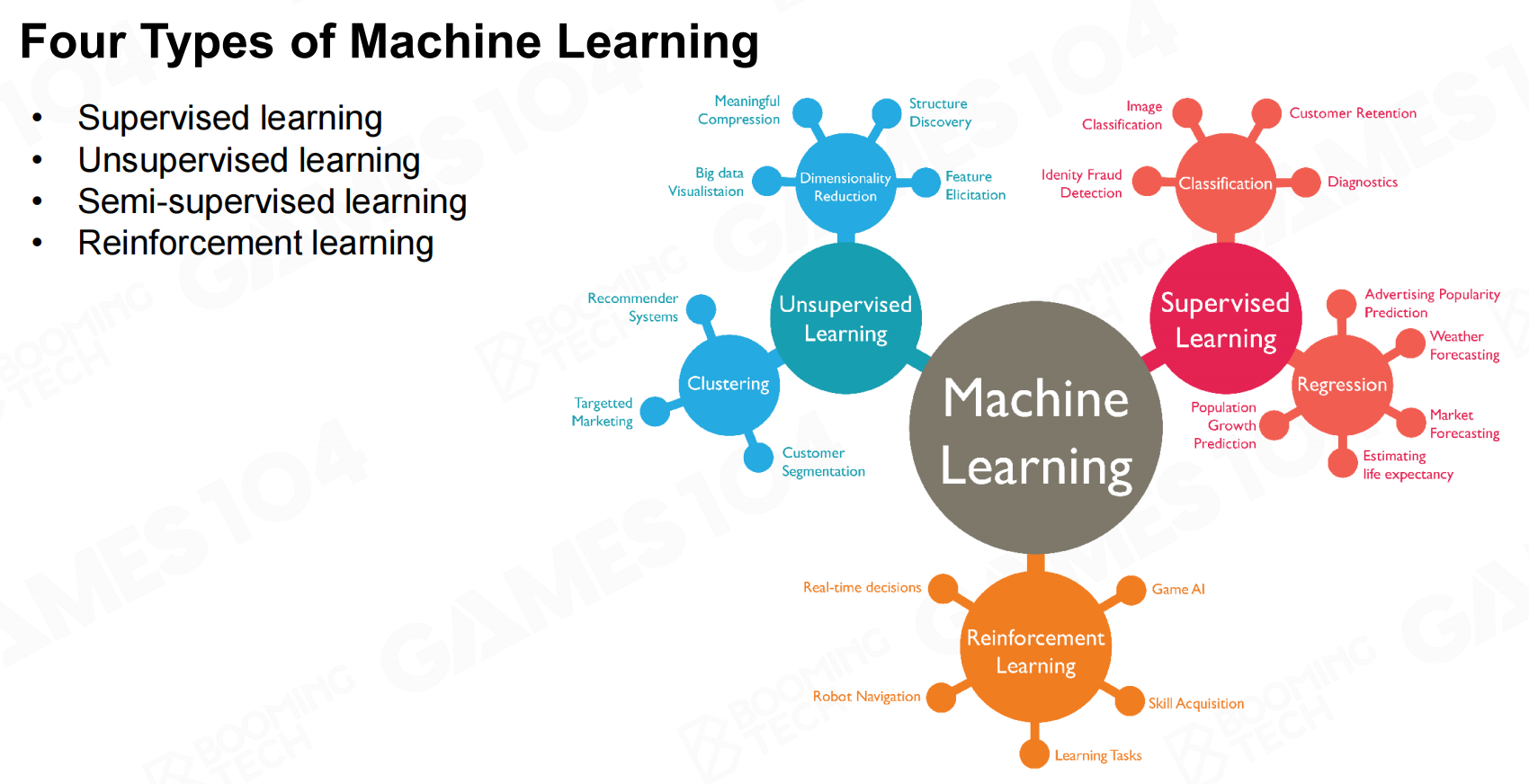 四种类型的机器学习
四种类型的机器学习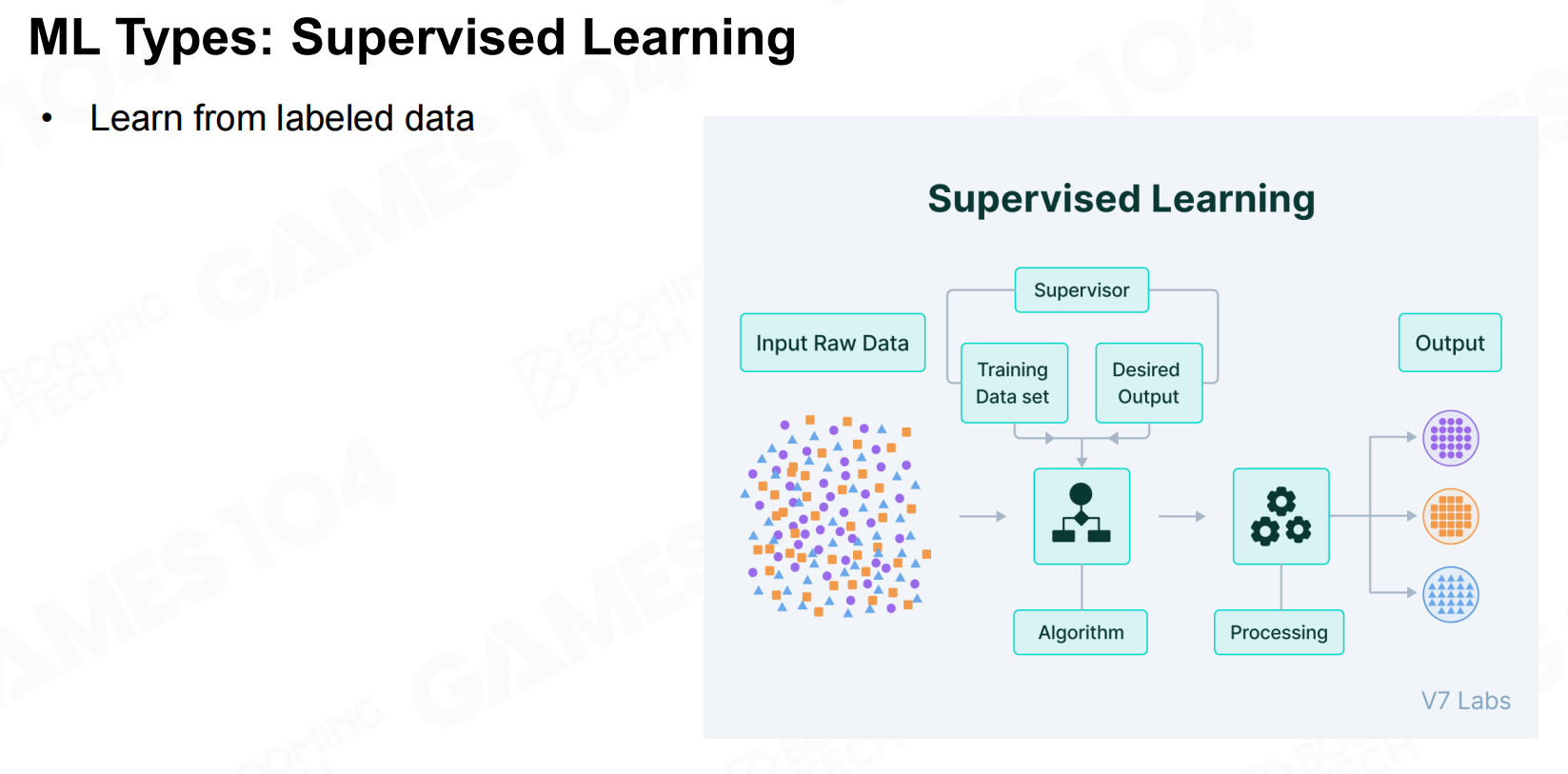 监督学习
监督学习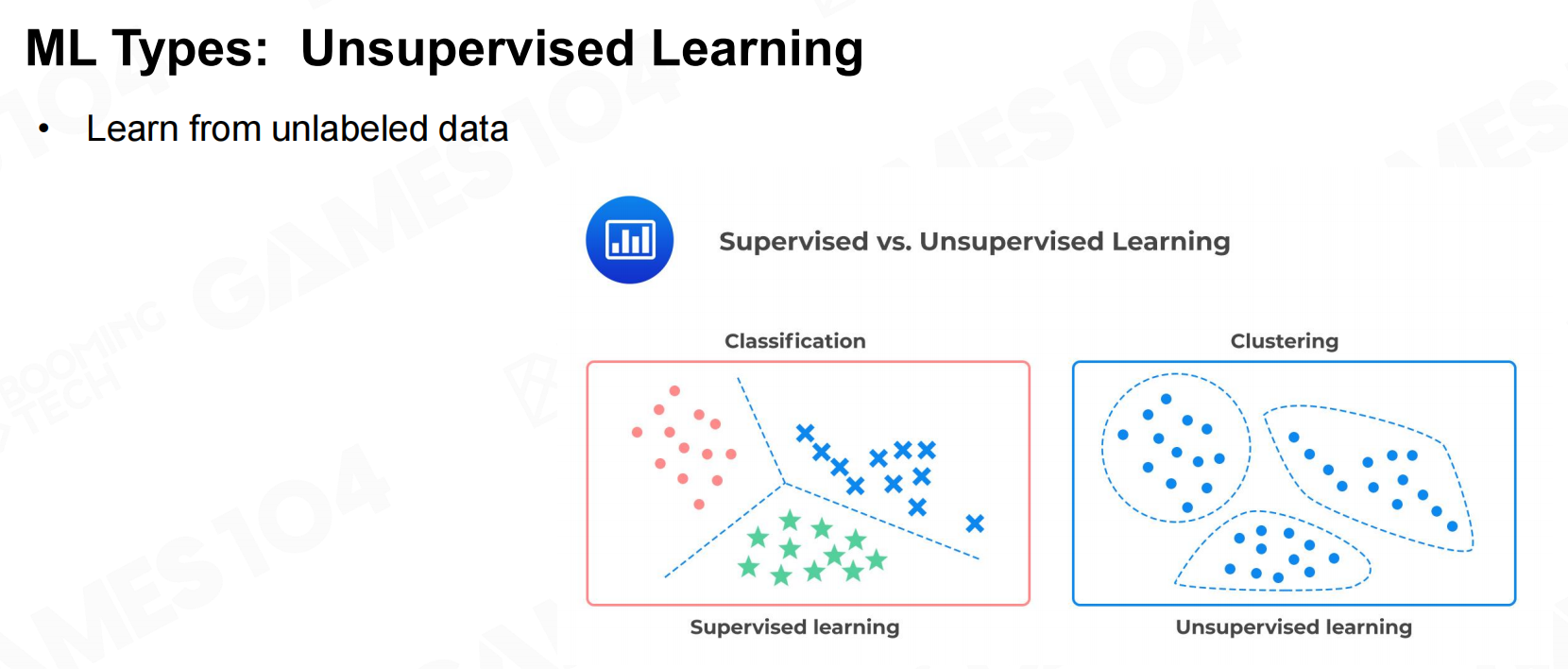 无监督学习
无监督学习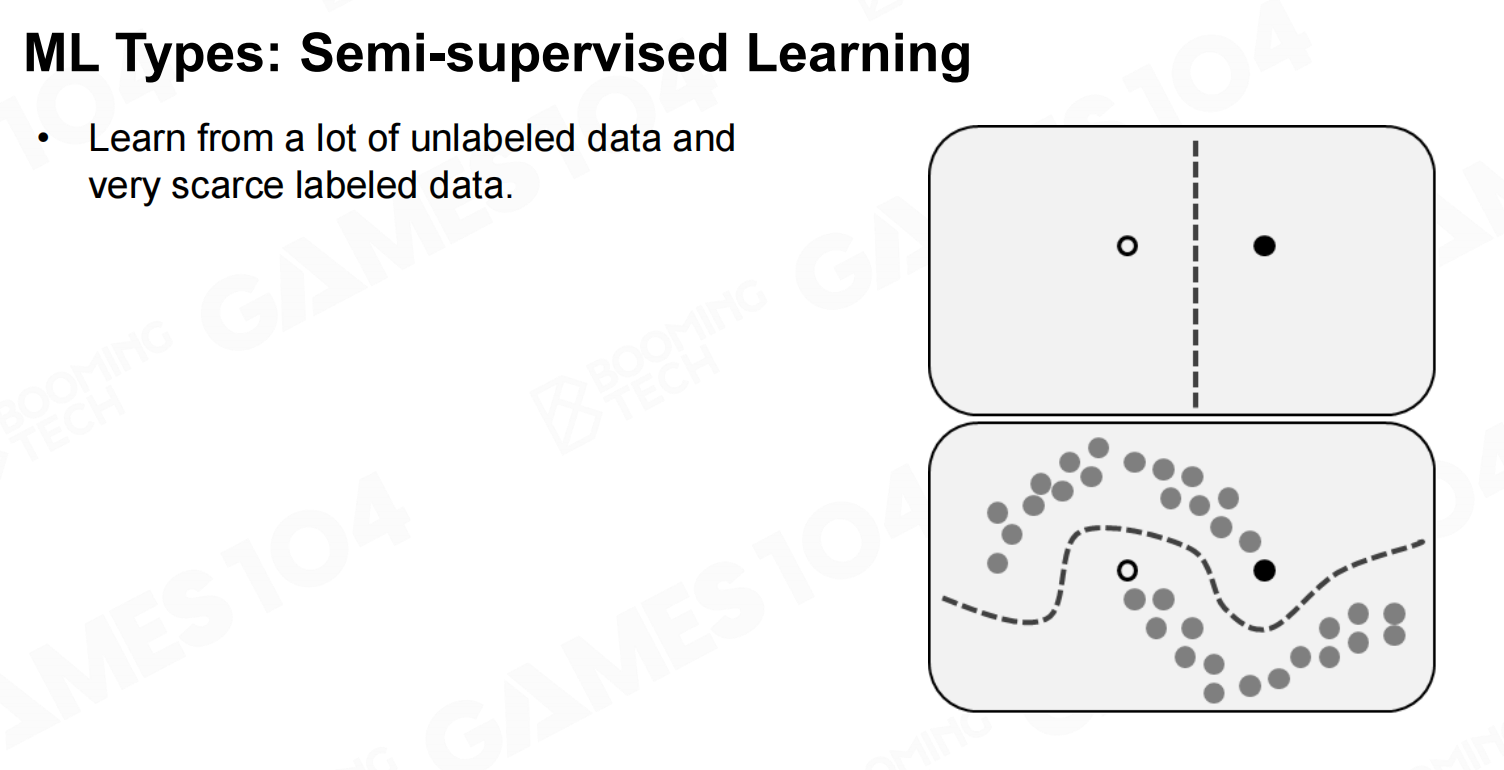 半监督学习
半监督学习
强化学习(reinforcement learning, RL)是游戏AI技术的基础。在强化学习中我们希望AI能够通过和环境的不断互动来学习到一个合理的策略。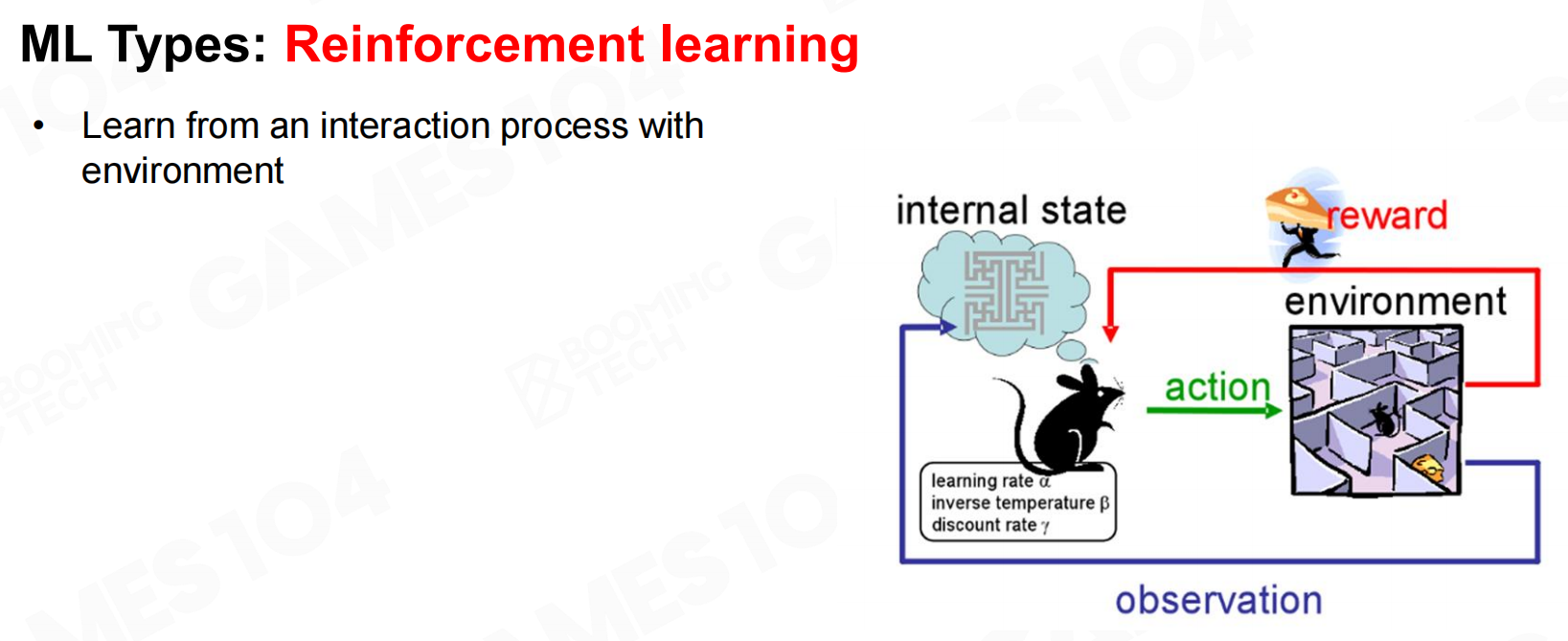 强化学习
强化学习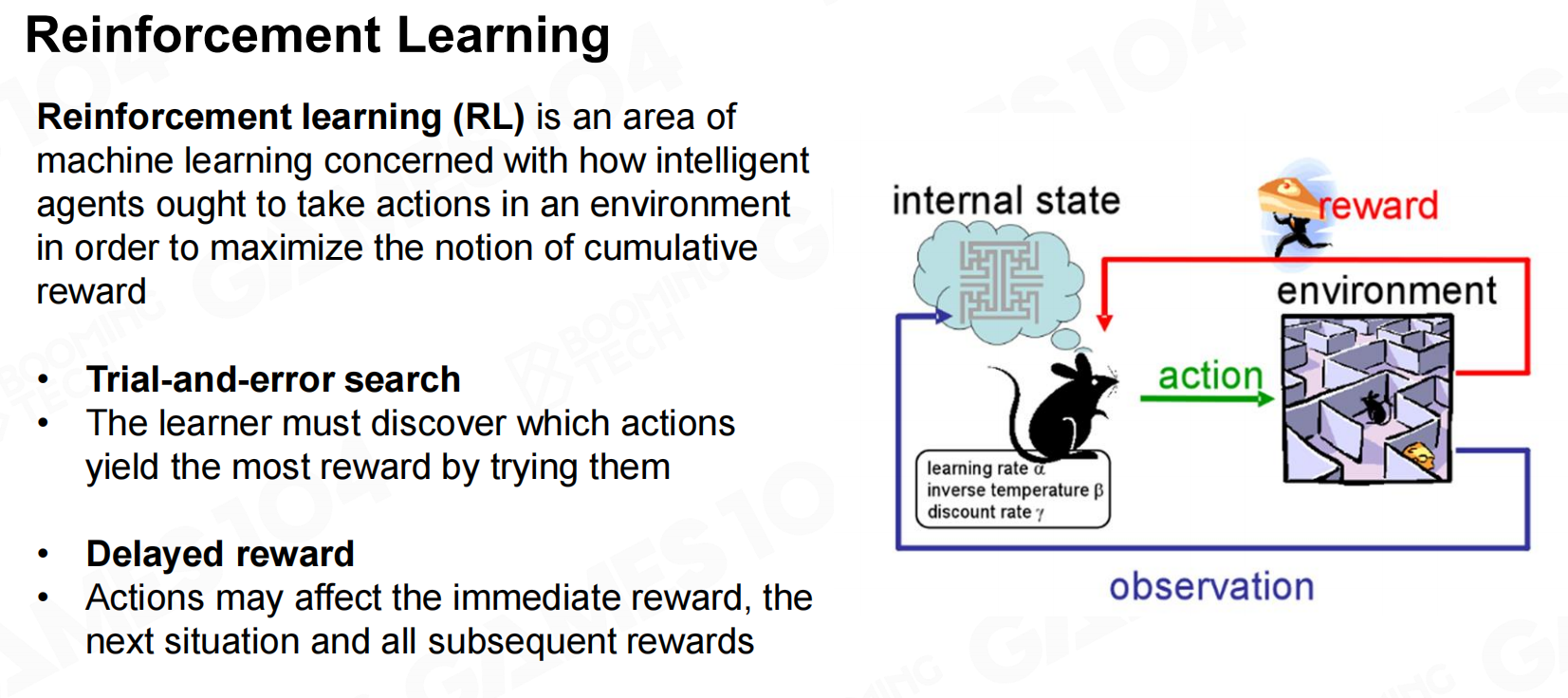 强化学习2
强化学习2
Markov决策过程(Markov Decision Process)
强化学习的理论基础是Markov决策过程(Markov decision process, MDP)。在MDP中智能体对环境的感知称为状态(state),环境对于智能体的反馈称为奖励(reward)。MDP的目标是让智能体通过和环境不断的互动来学习到如何在不同的环境下进行决策,这样的一个决策函数称为策略(policy)。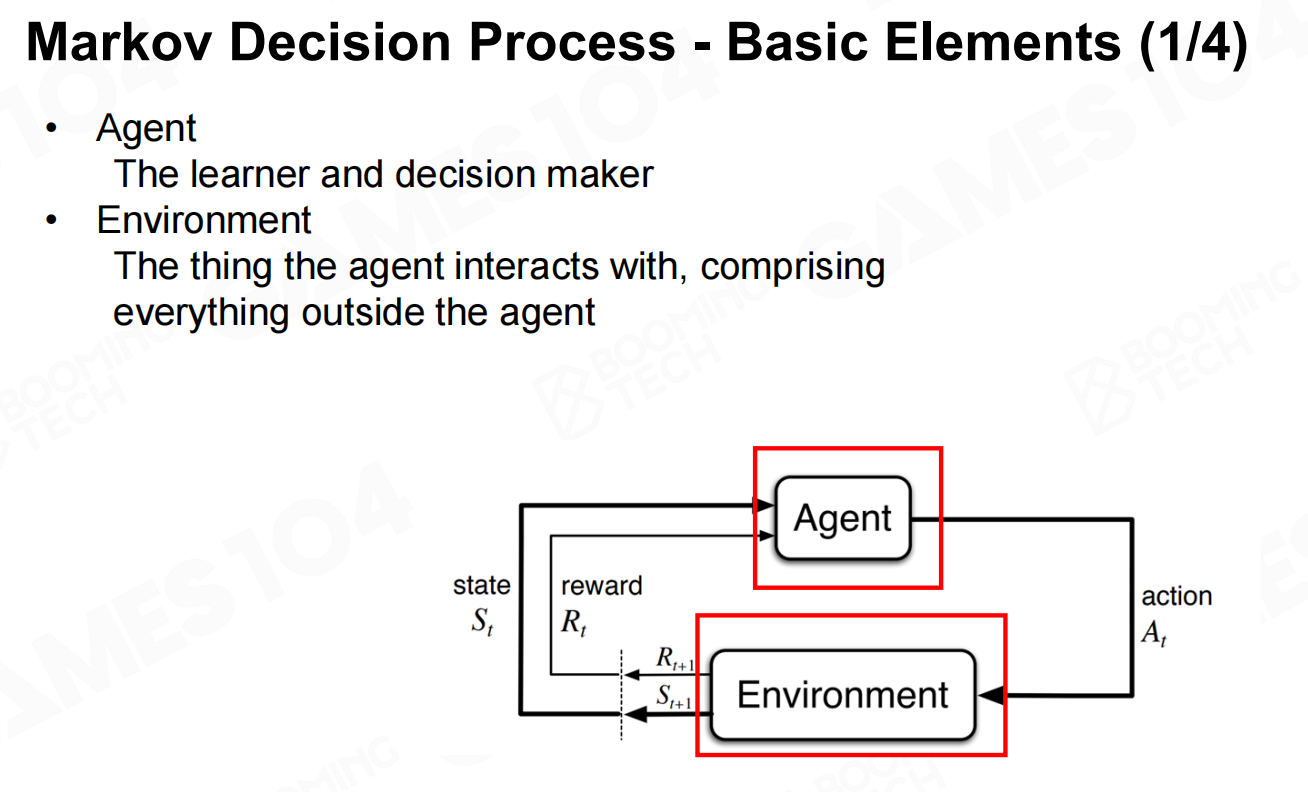 Markov决策过程-基本要素
Markov决策过程-基本要素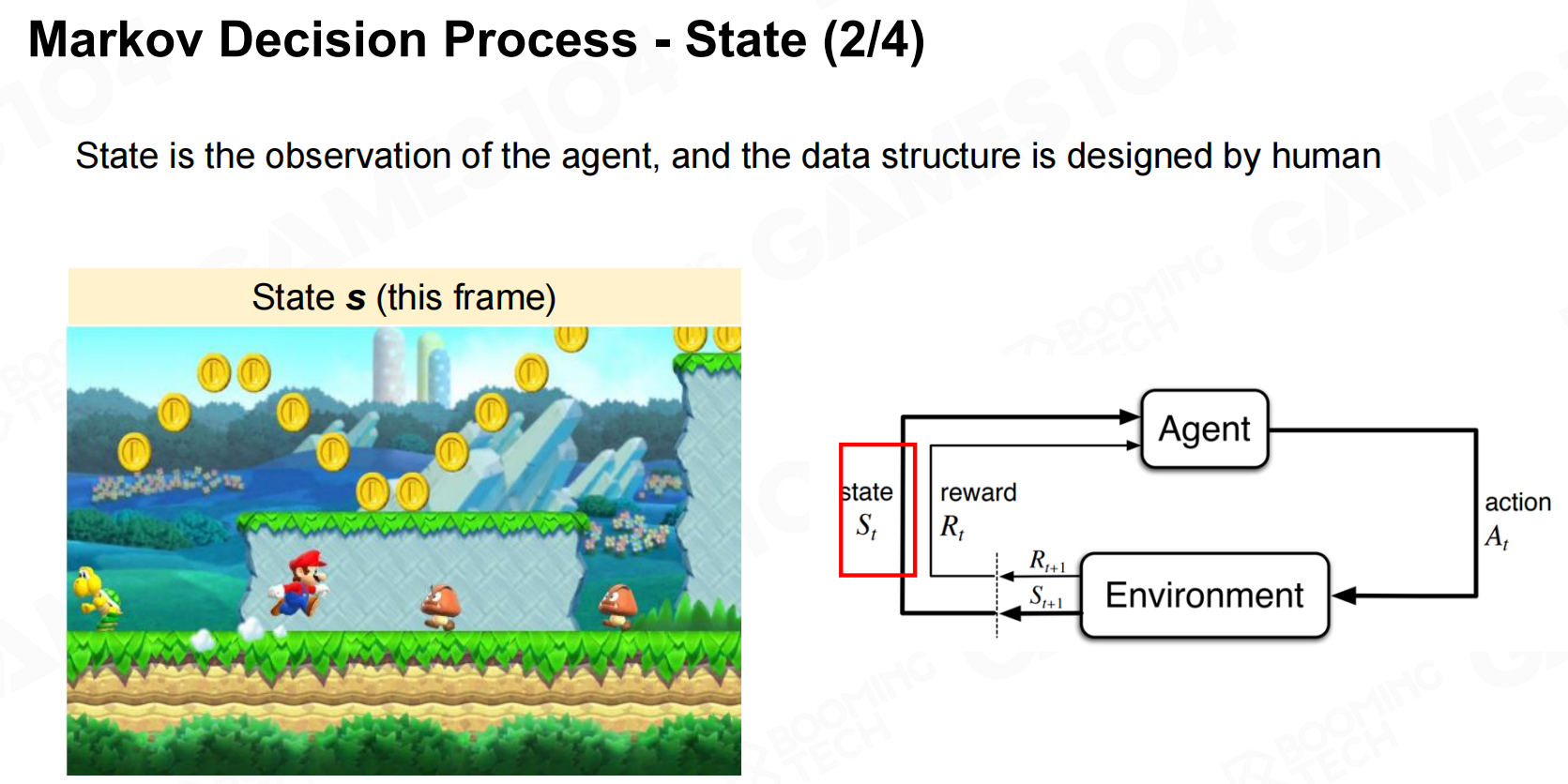 Markov决策过程-状态
Markov决策过程-状态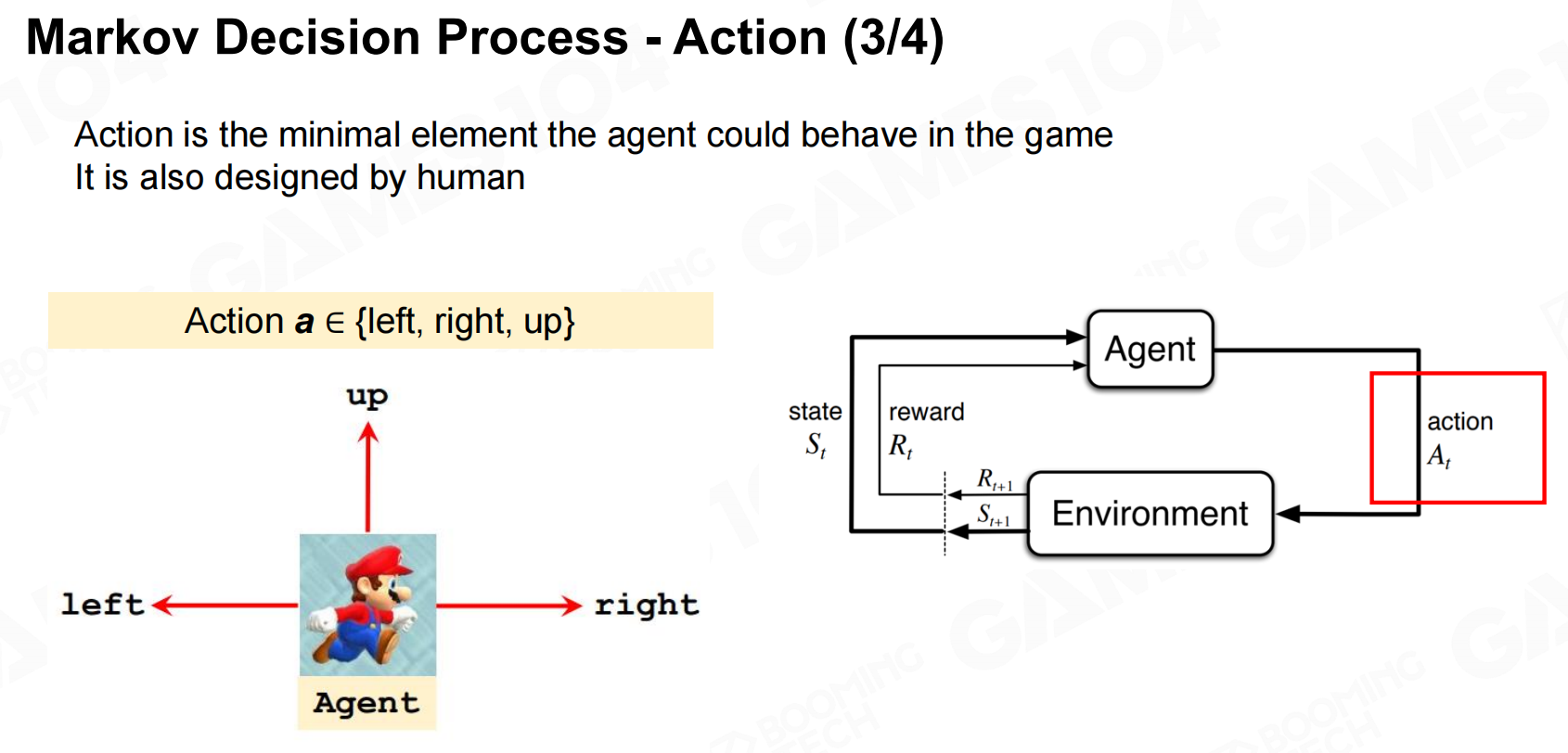 Markov决策过程-行动
Markov决策过程-行动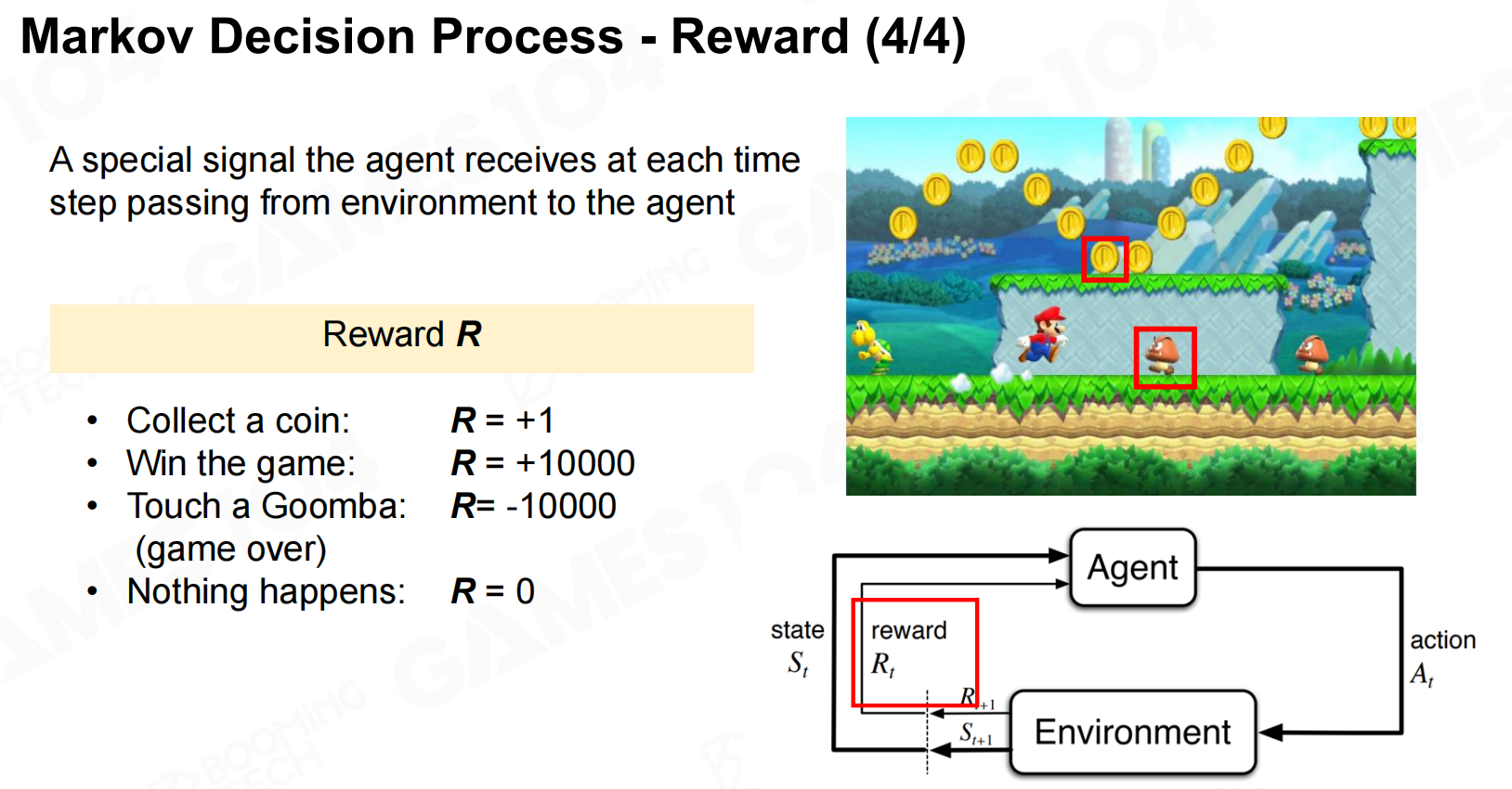 Markov决策过程-奖励
Markov决策过程-奖励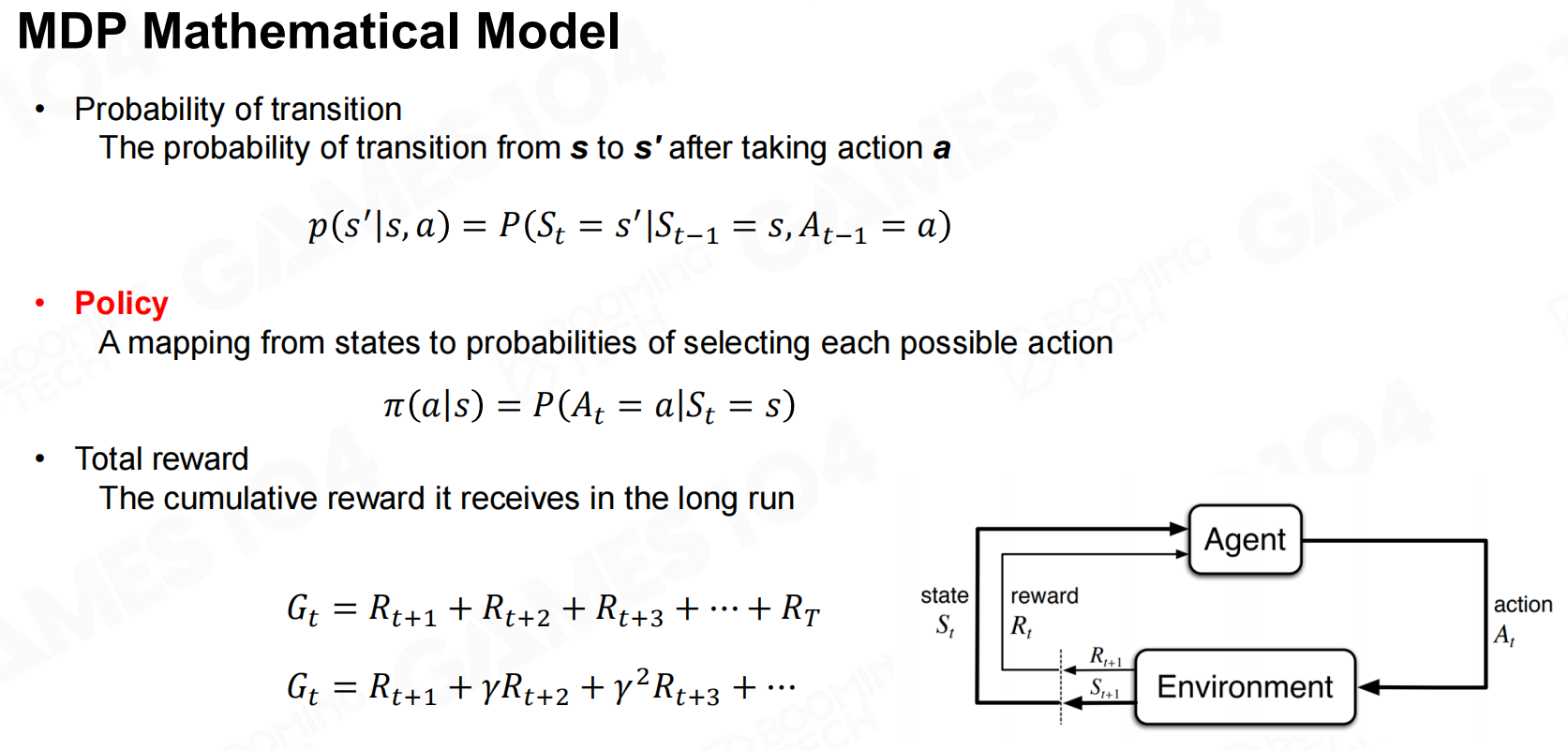 MDP数学模型
MDP数学模型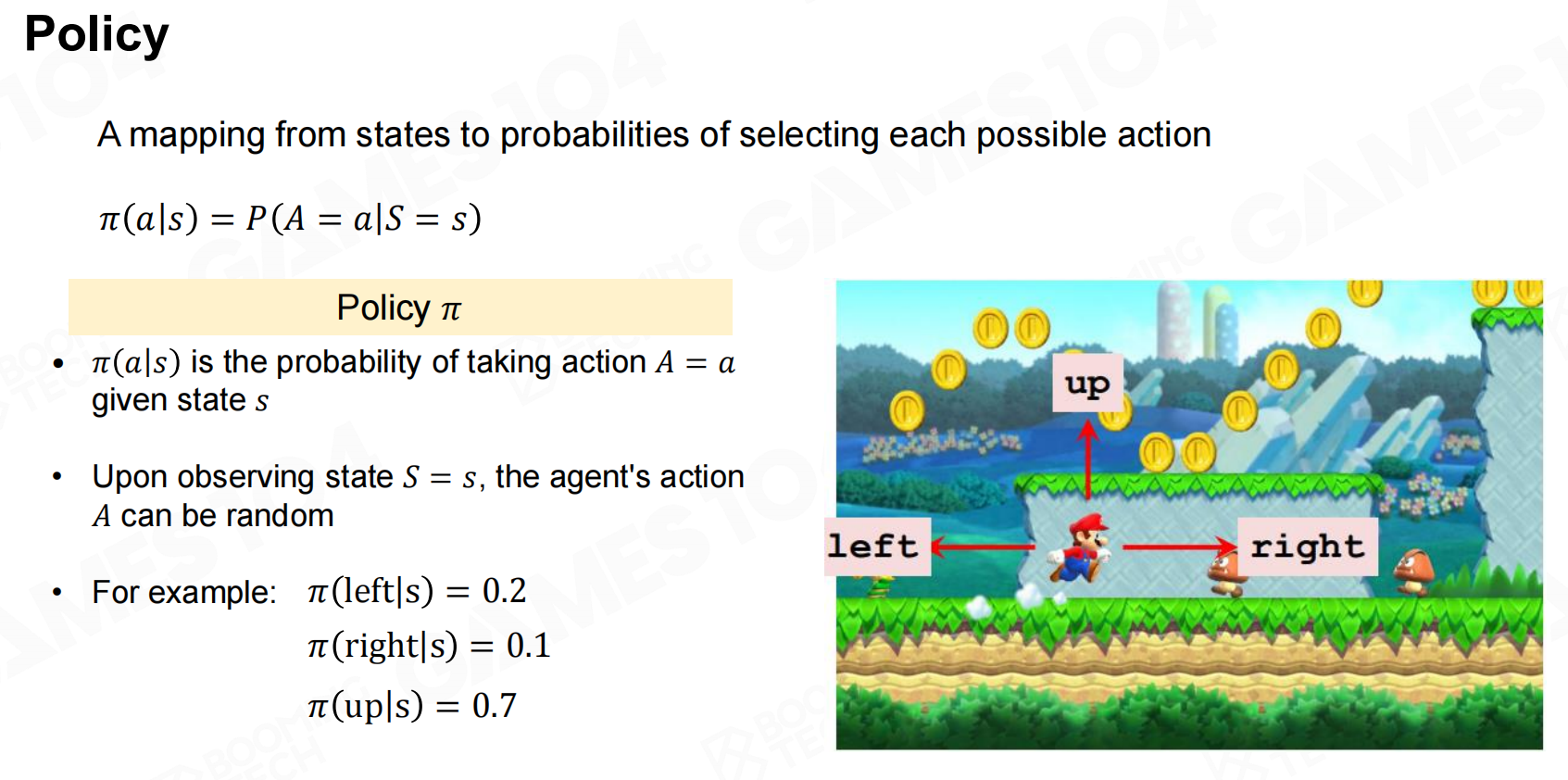 策略
策略
构建高级游戏AI(Build Advanced Game AI)
尽管目前基于机器学习的游戏AI技术大多还处于试验阶段,但已经有一些很优秀的项目值得借鉴和学习,包括DeepMind的AlphaStar以及OpenAI的Five等。 为什么游戏人工智能需要机器学习
为什么游戏人工智能需要机器学习
这些基于深度强化学习(deep reinforcement learning, DRL)的游戏AI都是使用一个深度神经网络来进行决策,整个框架包括接收游戏环境的观测,利用神经网络获得行为,以及从游戏环境中得到反馈。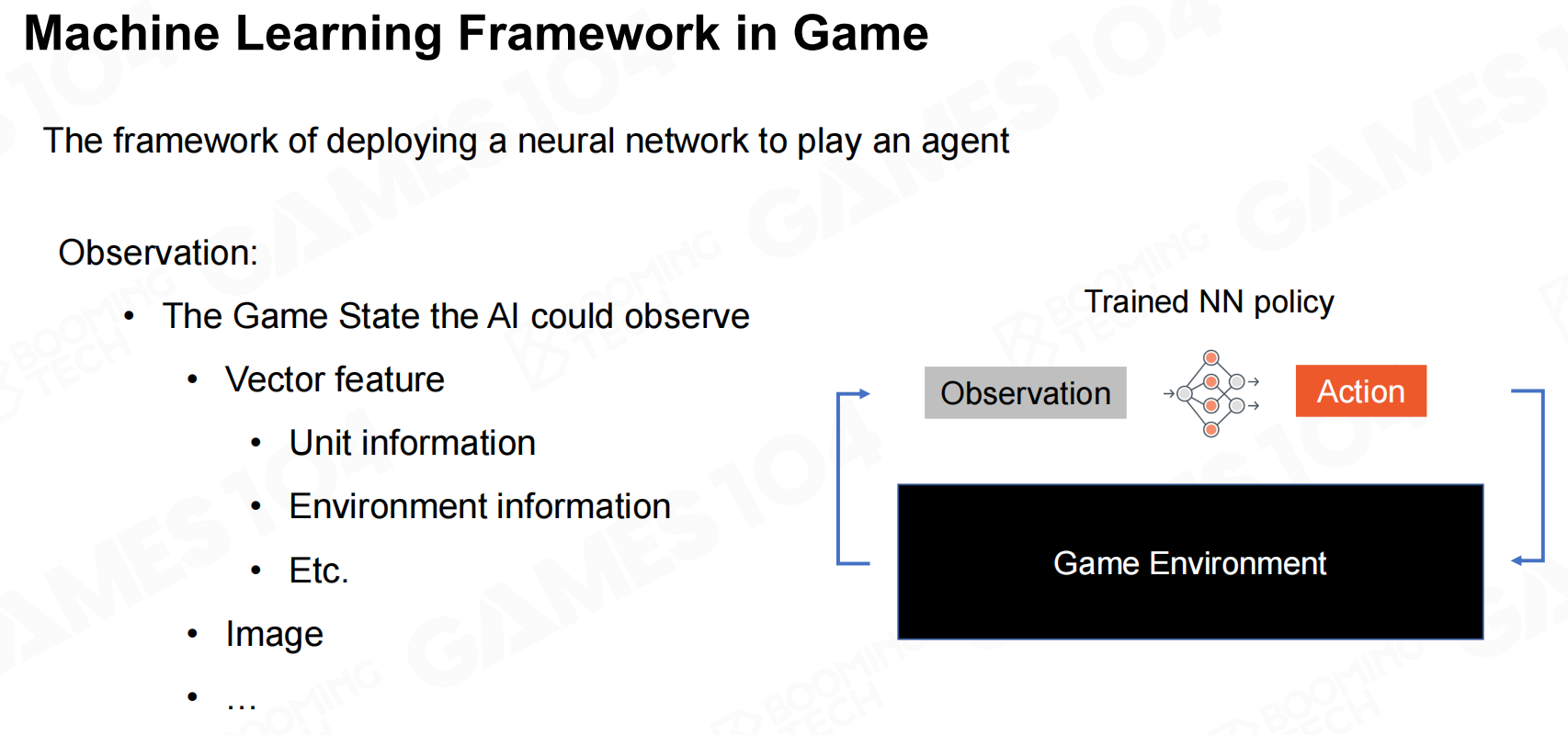 游戏中的机器学习框架
游戏中的机器学习框架
状态(State)
以AlphaStar为例,智能体可以直接从游戏环境获得的信息包括地图、统计数据、场景中的单位以及资源数据等。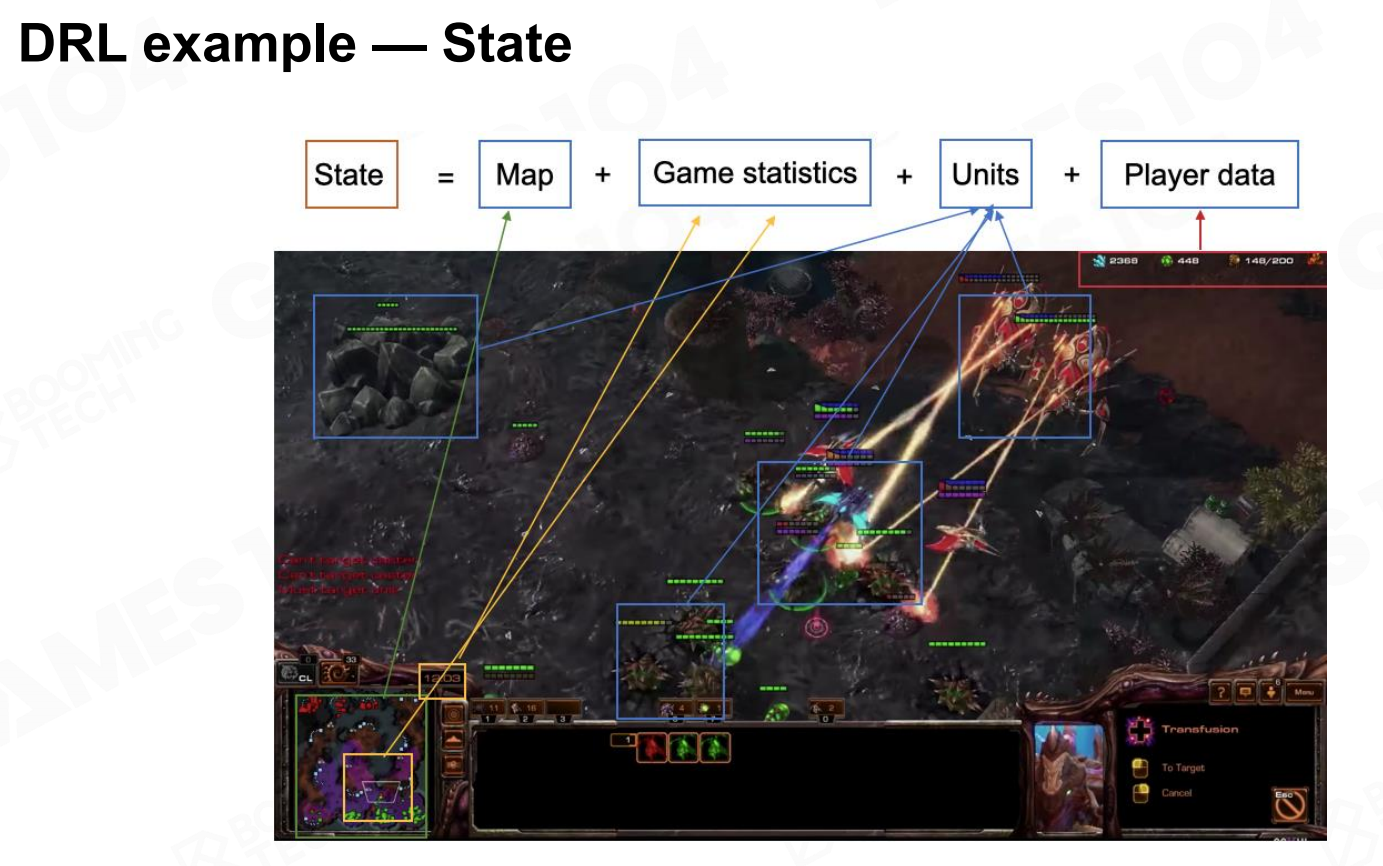 DRL示例-状态
DRL示例-状态 状态-地图
状态-地图 状态2-地图
状态2-地图
行动(Actions)
在AlphaStar中智能体的行为还取决于当前选中的单位。 行动
行动
奖励(Rewards)
奖励函数的设计对于模型的训练以及最终的性能都有着重要的影响。在AlphaStar中使用了非常简单的奖励设计,智能体仅在获胜时获得+1的奖励;而在OpenAI Five中则采用了更加复杂的奖励函数并以此来鼓励AI的进攻性。 奖励
奖励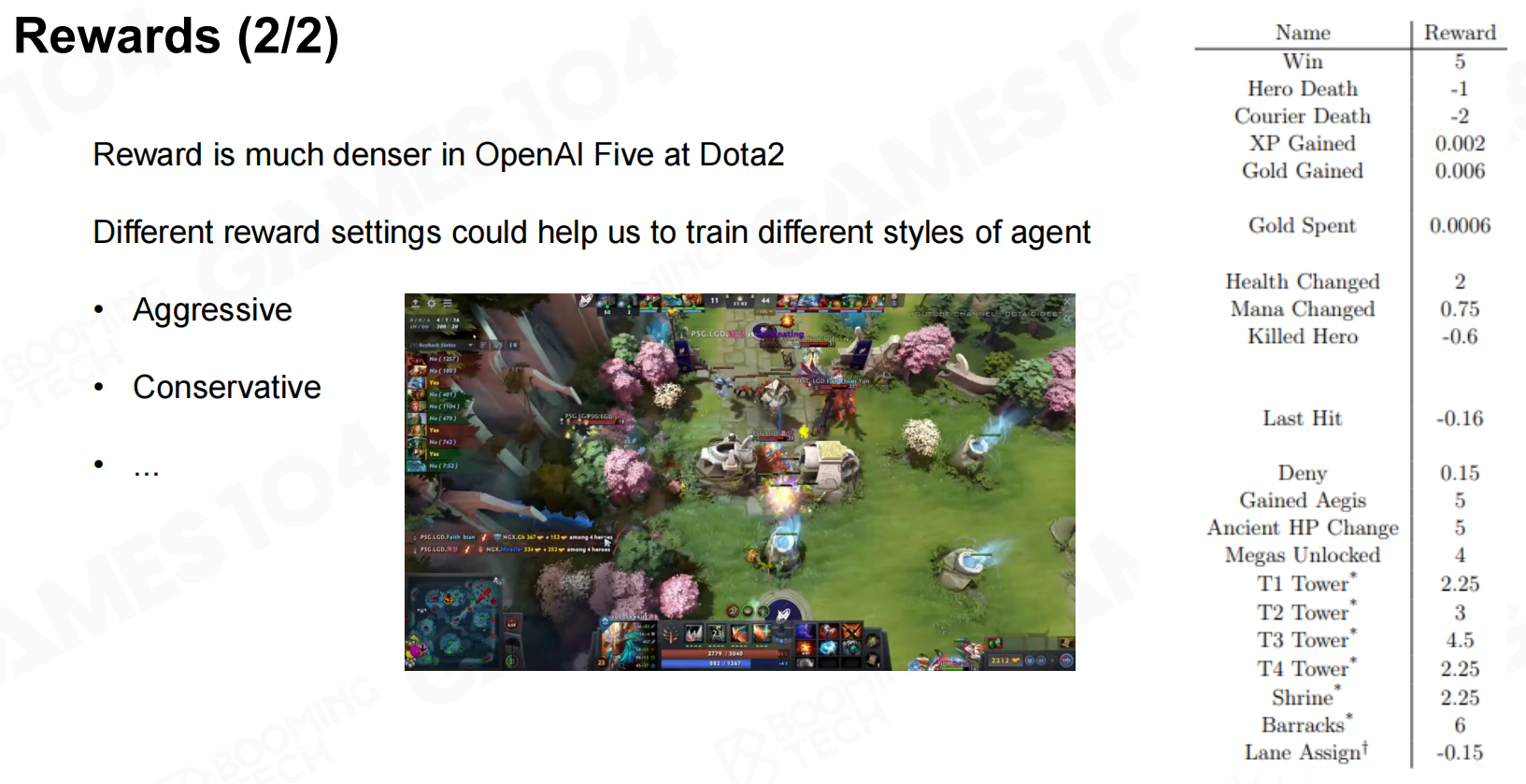 奖励2
奖励2
神经网络(Network)
在AlphaStar中使用了不同种类的神经网络来处理不同类型的输入数据,比如说对于定长的输入使用了MLP,对于图像数据使用了CNN,对于非定长的序列使用了Transformer,而对于整个决策过程还使用了LSTM进行处理。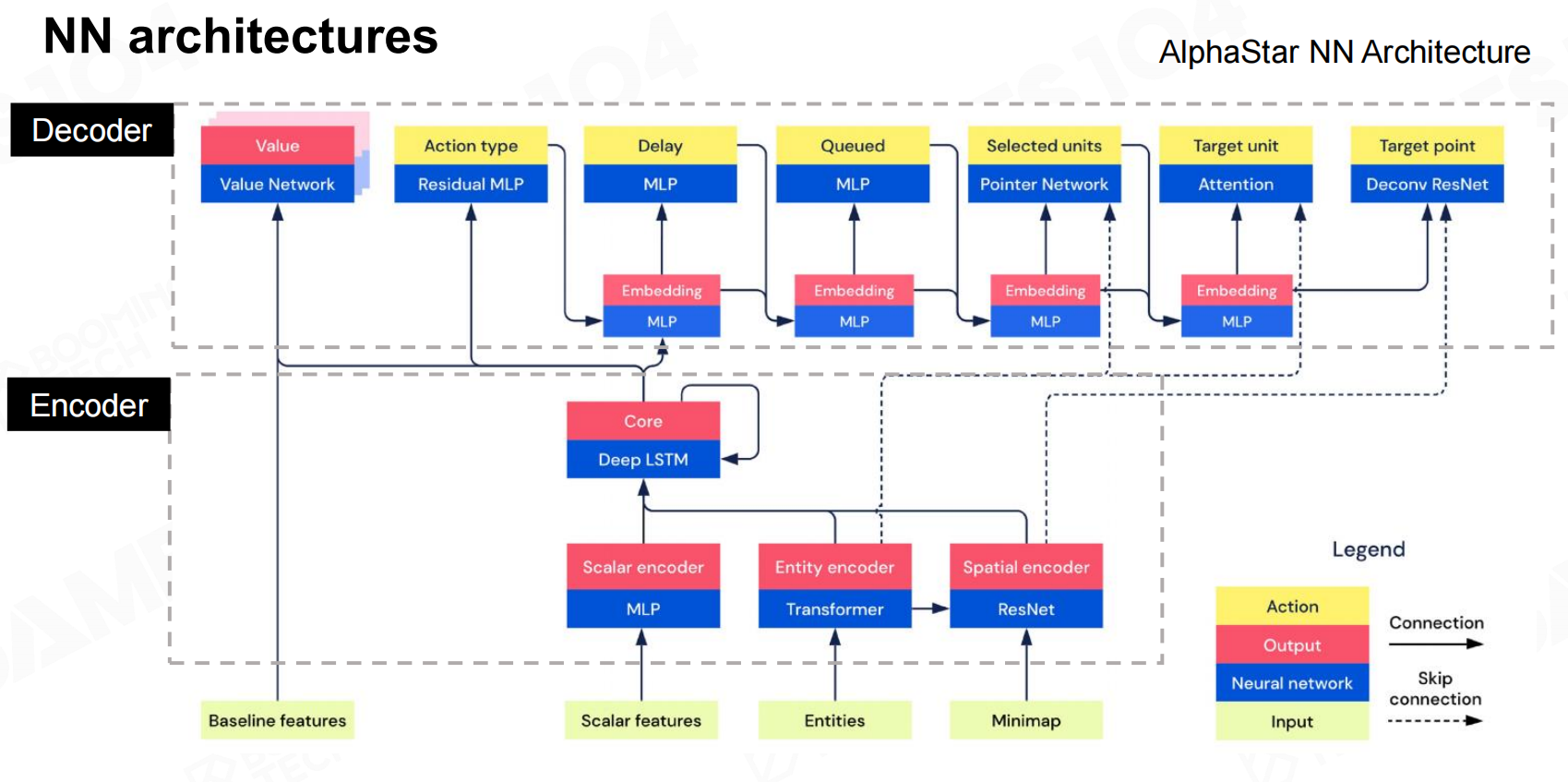 NN体系结构
NN体系结构 DRL示例——多层感知器(MLP)
DRL示例——多层感知器(MLP)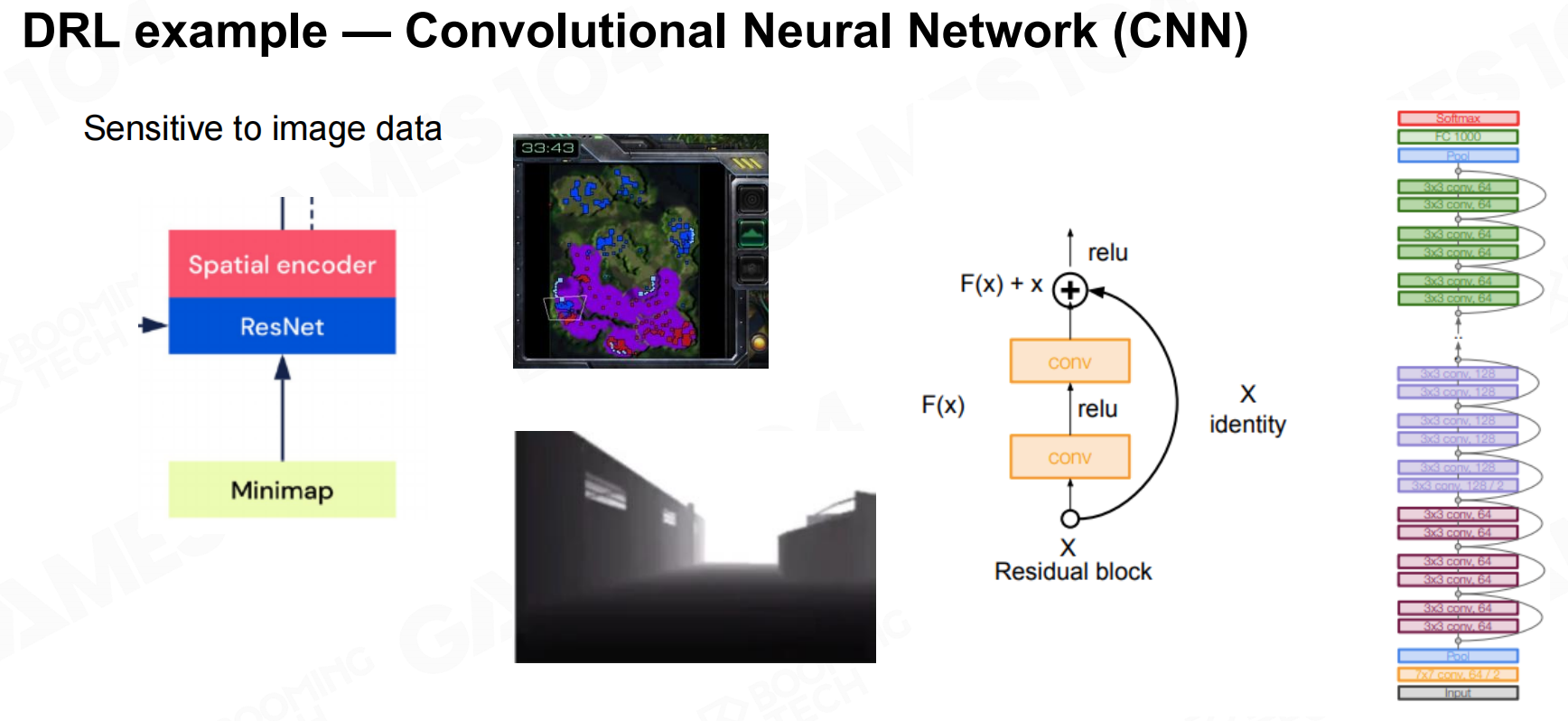 DRL示例-卷积神经网络(CNN)
DRL示例-卷积神经网络(CNN)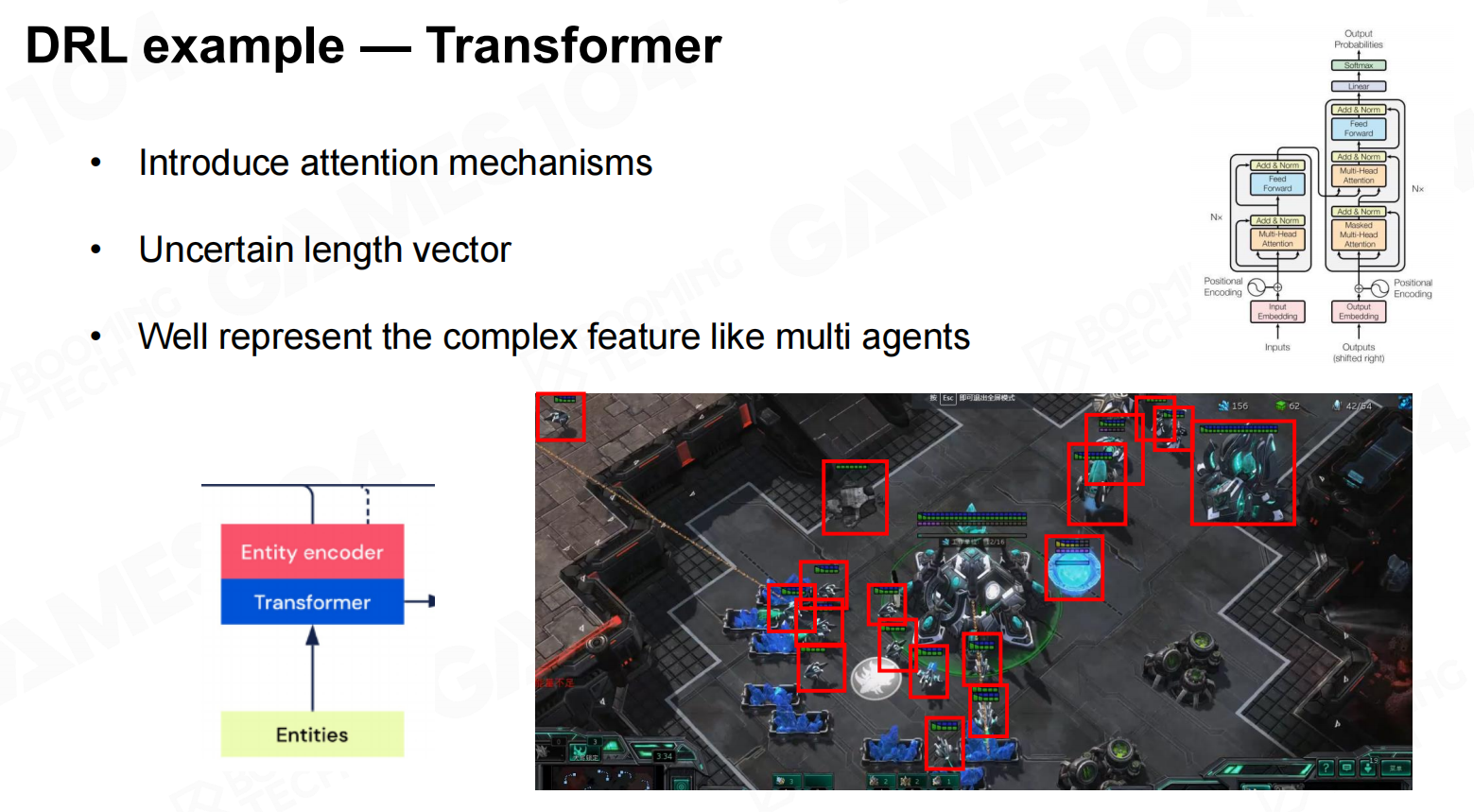 DRL示例-转换器
DRL示例-转换器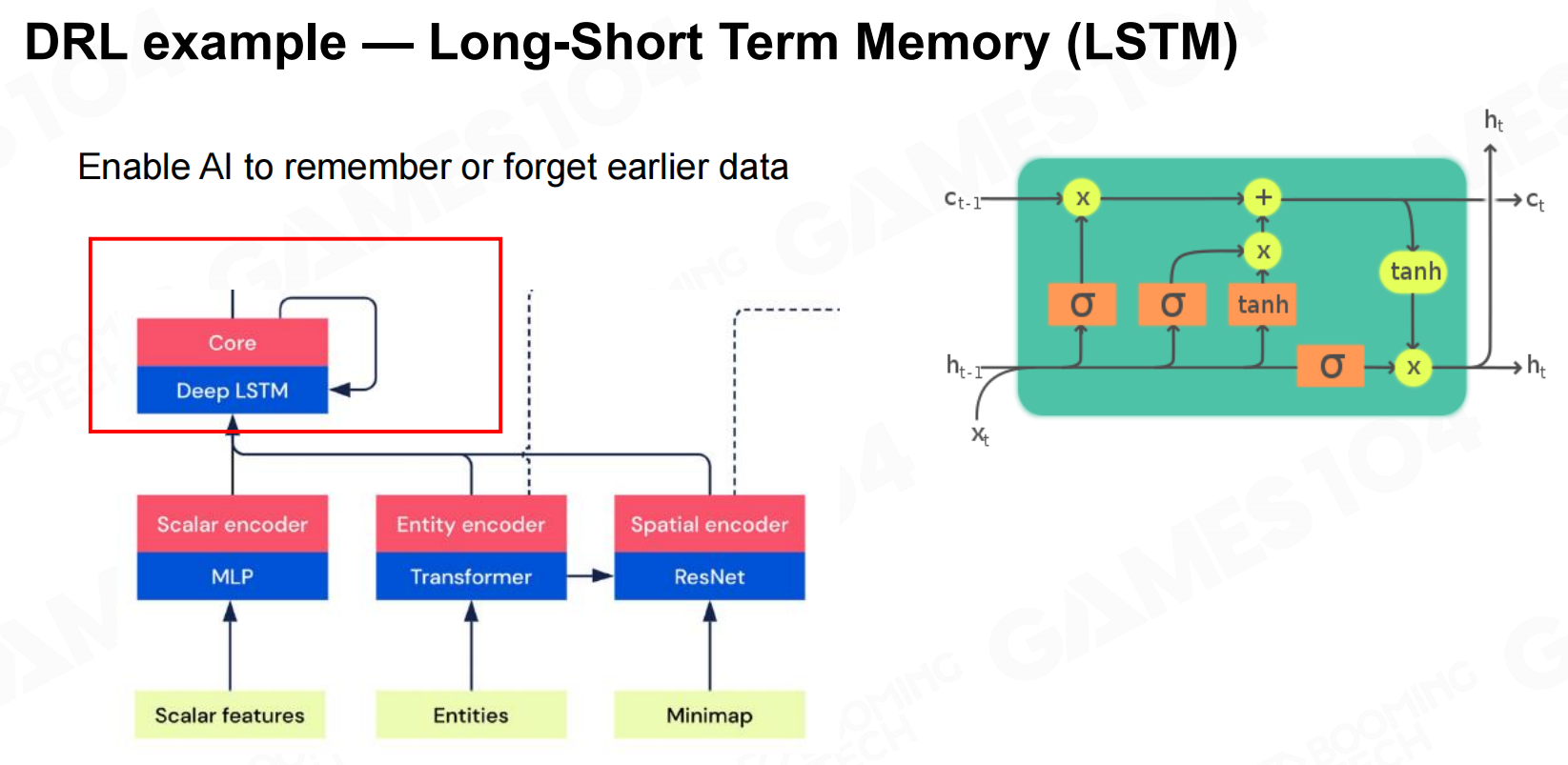 DRL示例-长短期记忆递归(LSTM)
DRL示例-长短期记忆递归(LSTM) DRL示例——神经网络架构的选择
DRL示例——神经网络架构的选择
训练策略(Training Strategy)
除此之外,AlphaStar还对模型的训练过程进行了大规模的革新。在AlphaStar的训练过程中首先使用了监督学习的方式来从人类玩家的录像中进行学习。 训练策略-监督学习
训练策略-监督学习
接着,AlphaStar使用了强化学习的方法来进行自我训练。 训练策略-强化学习
训练策略-强化学习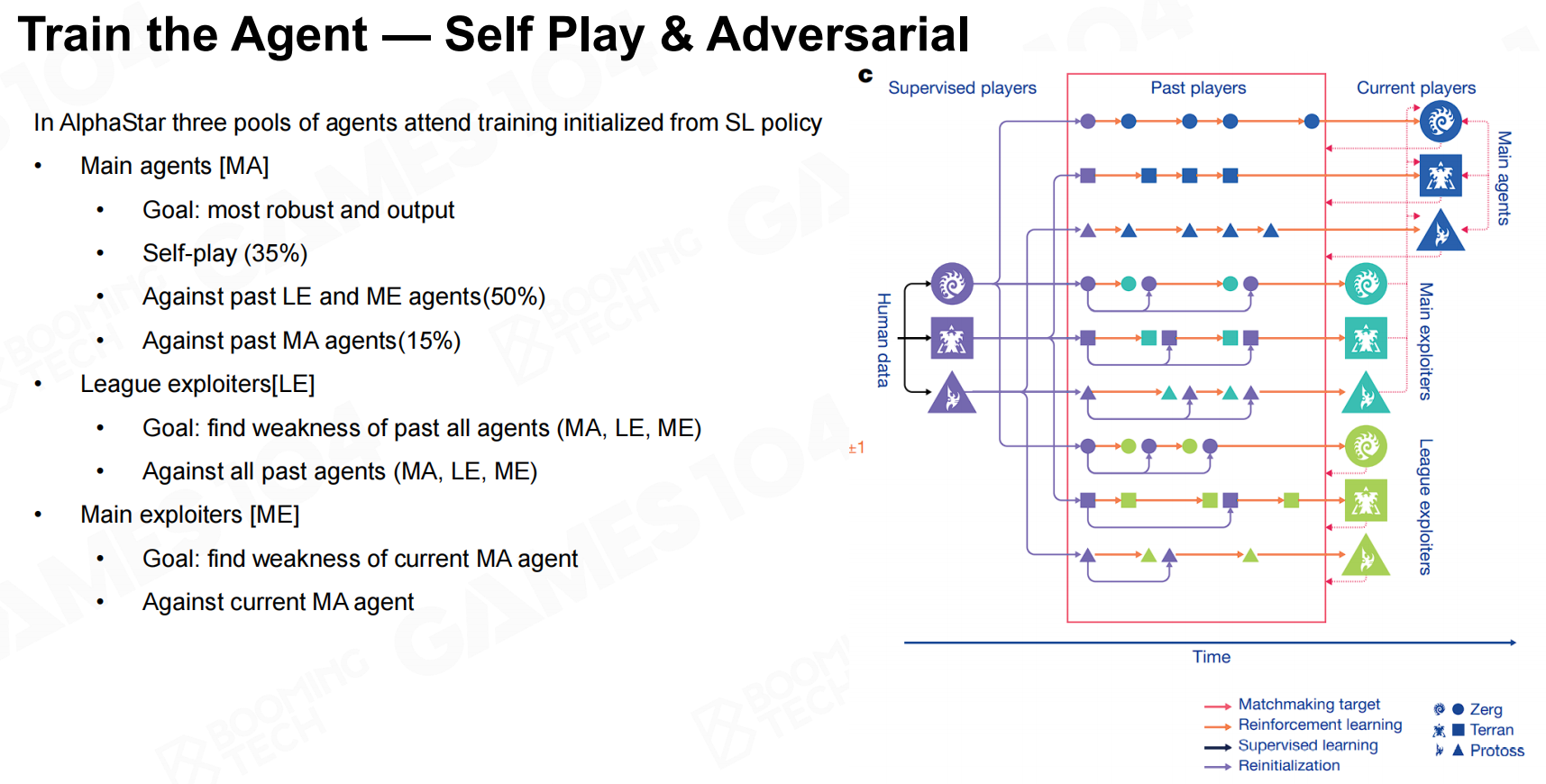 训练代理-自我游戏和对抗性
训练代理-自我游戏和对抗性
试验结果分析表明基于监督学习训练的游戏AI其行为会比较接近于人类玩家,但基本无法超过人类玩家的水平;而基于强化学习训练的AI则可能会有超过玩家的游戏水平,不过需要注意的是使用强化学习可能需要非常多的训练资源。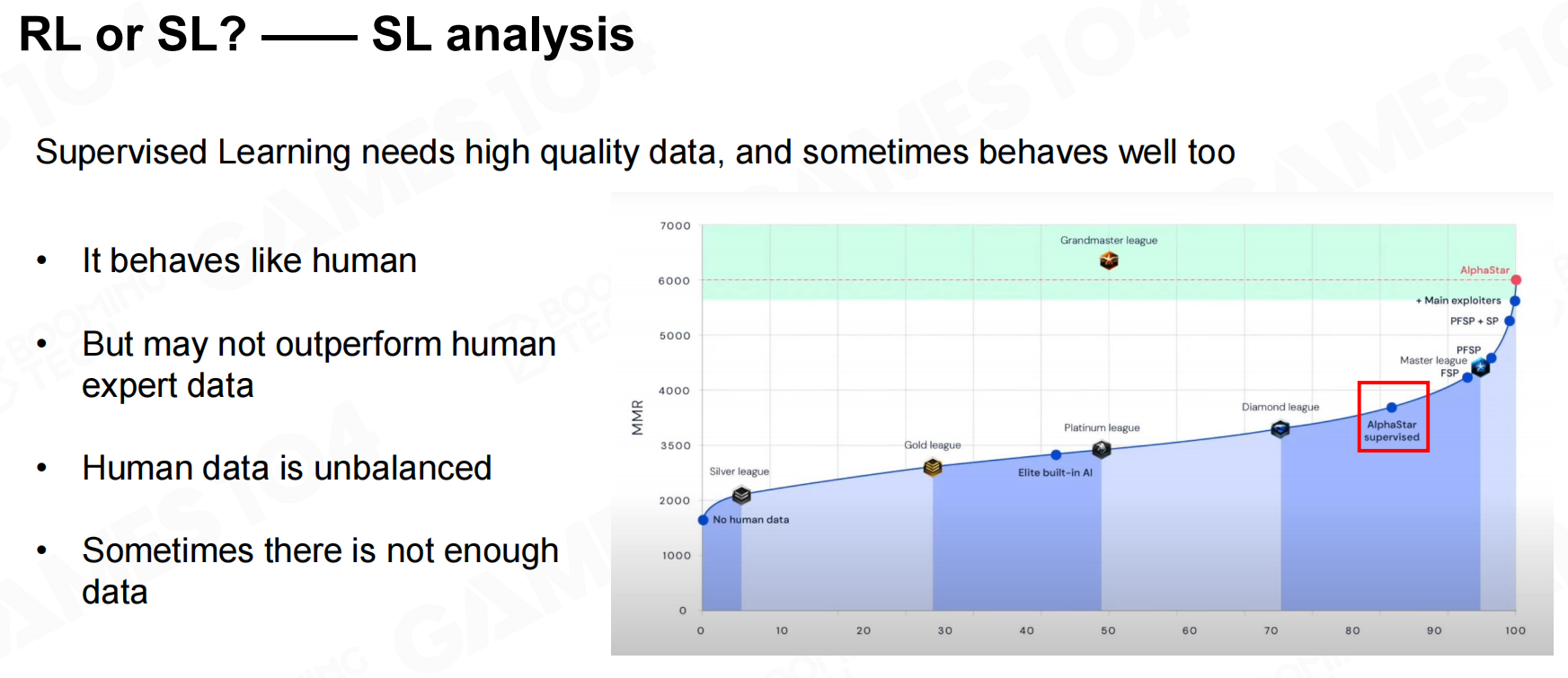 RL还是SL?——SL分析
RL还是SL?——SL分析 RL还是SL?——RL分析
RL还是SL?——RL分析
因此对于游戏AI到底是使用监督学习还是使用强化学习进行训练需要结合实际的游戏环境进行考虑。对于奖励比较密集的环境可以直接使用强化学习进行训练,而对于奖励比较稀疏的环境则推荐使用监督学习。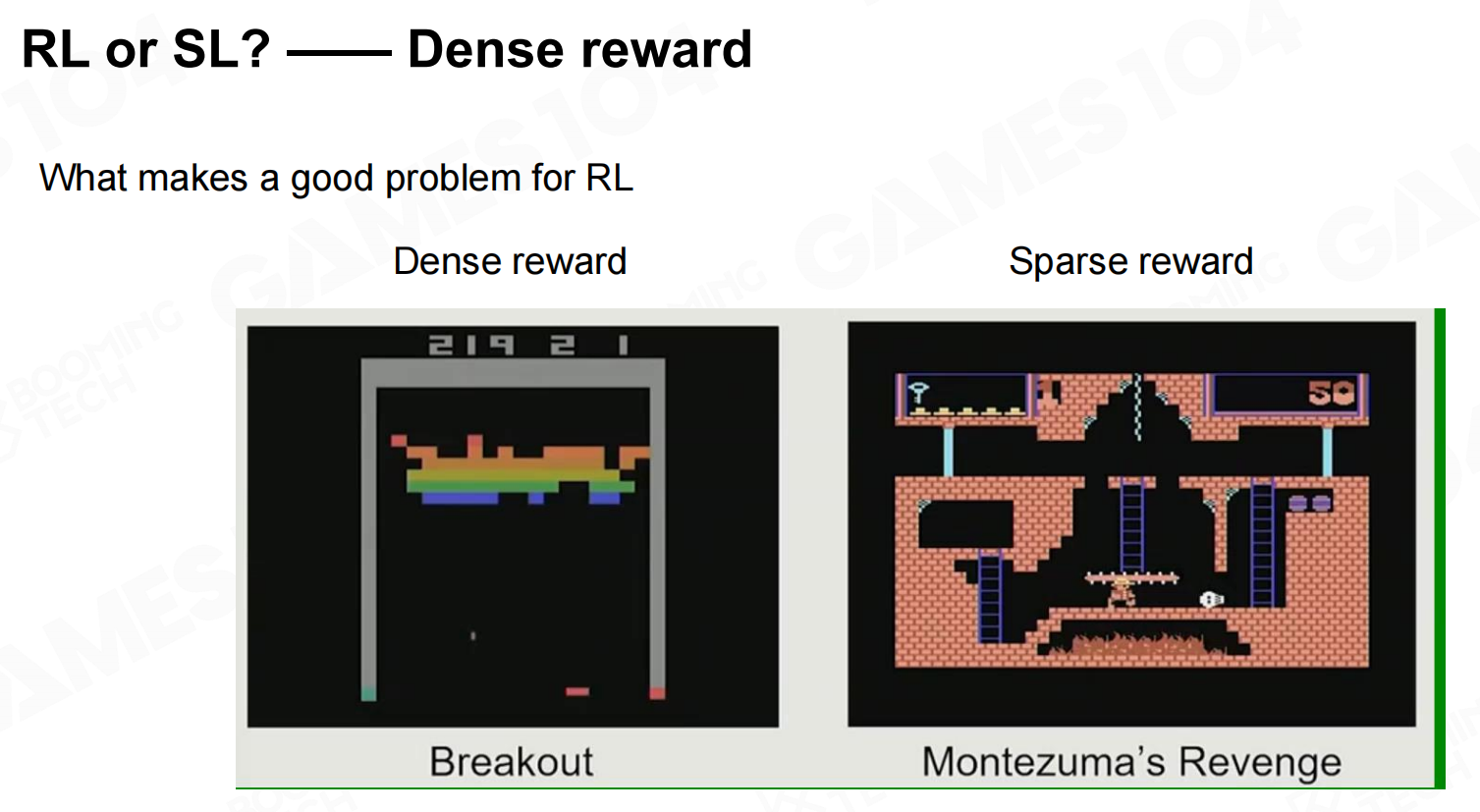 RL还是SL?——密集的奖励
RL还是SL?——密集的奖励 RL还是SL?——总结
RL还是SL?——总结
引用
- 本文作者:樱白 - Cherry White
- 本文链接:https://cherry-white.github.io/posts/3f39b042.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!
☕ 如果这篇文章对你有帮助
欢迎请我喝杯咖啡,支持持续创作