
现代游戏引擎 - 基础AI系统:寻路、转向与行为树(十六)
AI课程大纲
 AI课程大纲
AI课程大纲
寻路系统(Navigation)
游戏AI是玩法系统重要的组成部分,其中最基本的功能是允许玩家选择目的地进行导航(navigation)。 游戏中导航
游戏中导航
导航算法需要考虑游戏地图的不同表达形式,然后寻找到从起点到目的地的最短路径,有时还需要结合一些其它算法来获得更加光滑的路线。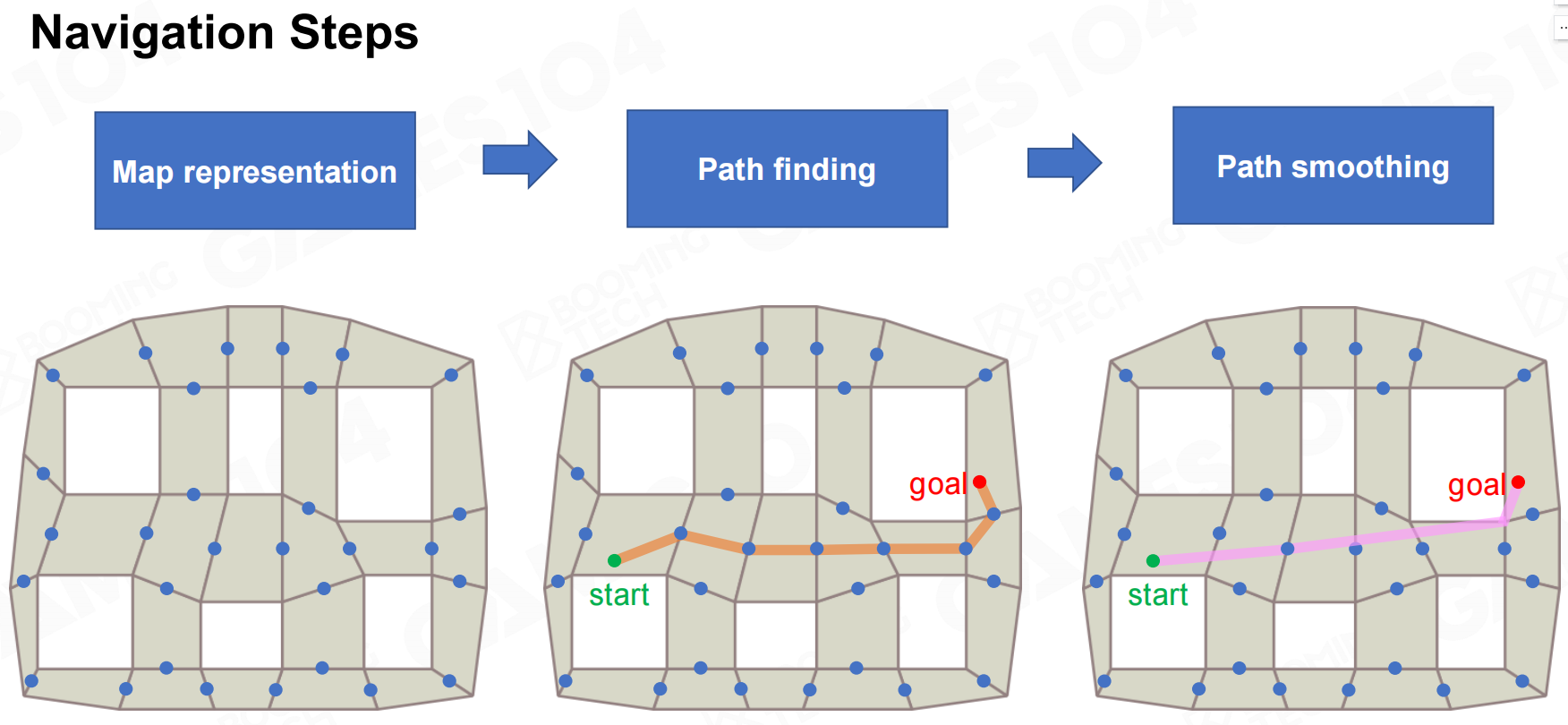 导航步骤
导航步骤
地图制图表达(Map Representation)
因此我们首先需要考虑游戏中如何来表达地图,我们可以认为地图是玩家和NPC可以行动的区域。游戏中常见的地图形式包括路点网络图(waypoint network)、网格(grid)、寻路网格(navigation mesh)以及八叉树(sparse voxel octree)等 地图表达-可走区域
地图表达-可走区域 地图表达-格式
地图表达-格式
网络图(Waypoint Network)
waypoint network是早期游戏中最常用的地图表示方式。我们可以把地图上的路标使用节点来表示,然后可通行的节点使用边来连接起来就形成了一个网络结构。 航路点网络
航路点网络
当玩家需要进行导航时只需要选择距离起点和目的地最近的两个路标,然后在网络图上进行导航即可。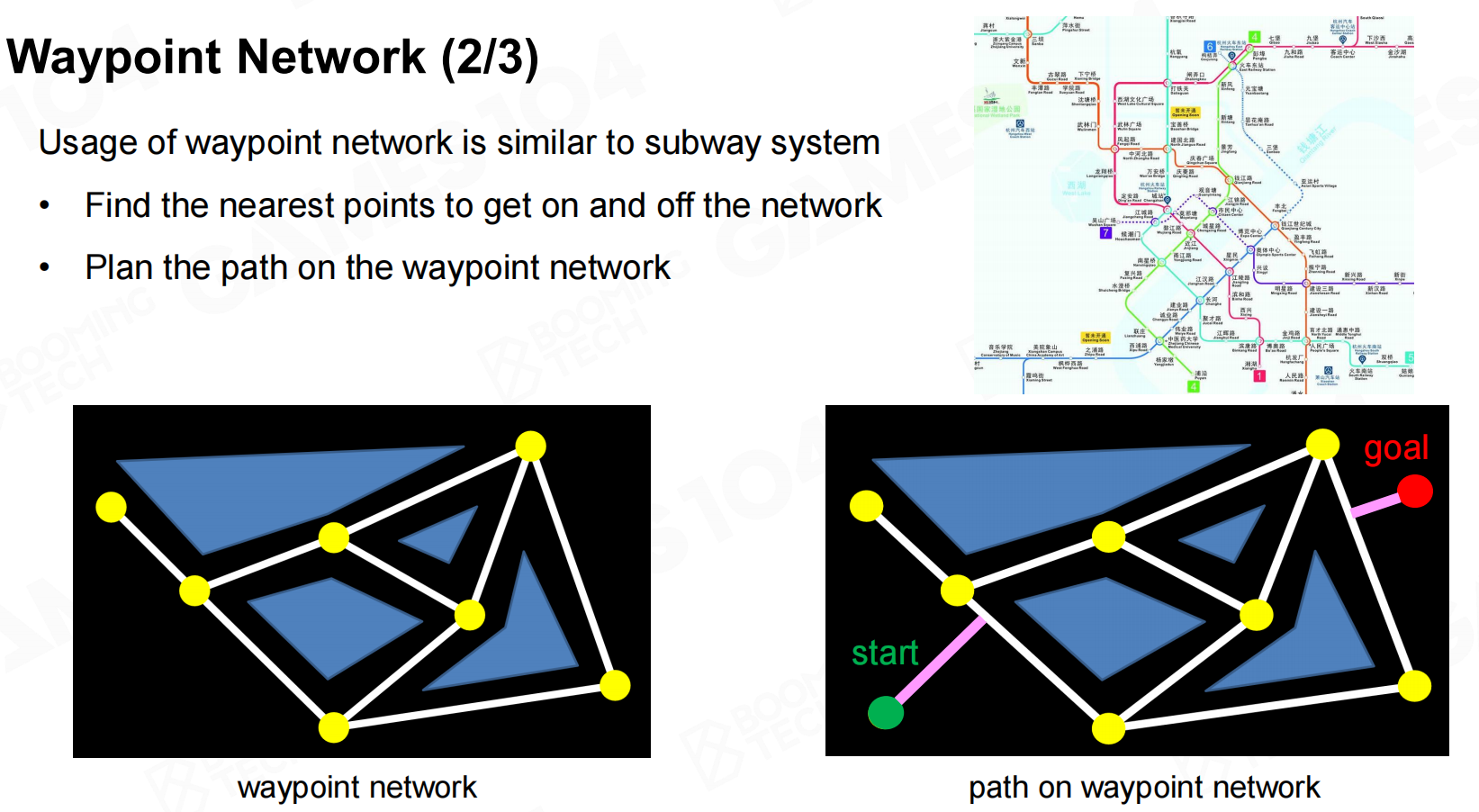 航路点网络2
航路点网络2
waypoint network的优势在于它非常易于实现,而且我们有成熟的路径搜索算法可以直接应用在网络图上;但它的缺陷在于路网图需要不断地和开发中的地图进行更新,而且使用路网进行导航时角色会倾向于沿路径中心前进而无法利用两边的通道。因此在现代游戏中路网的应用并不是很多。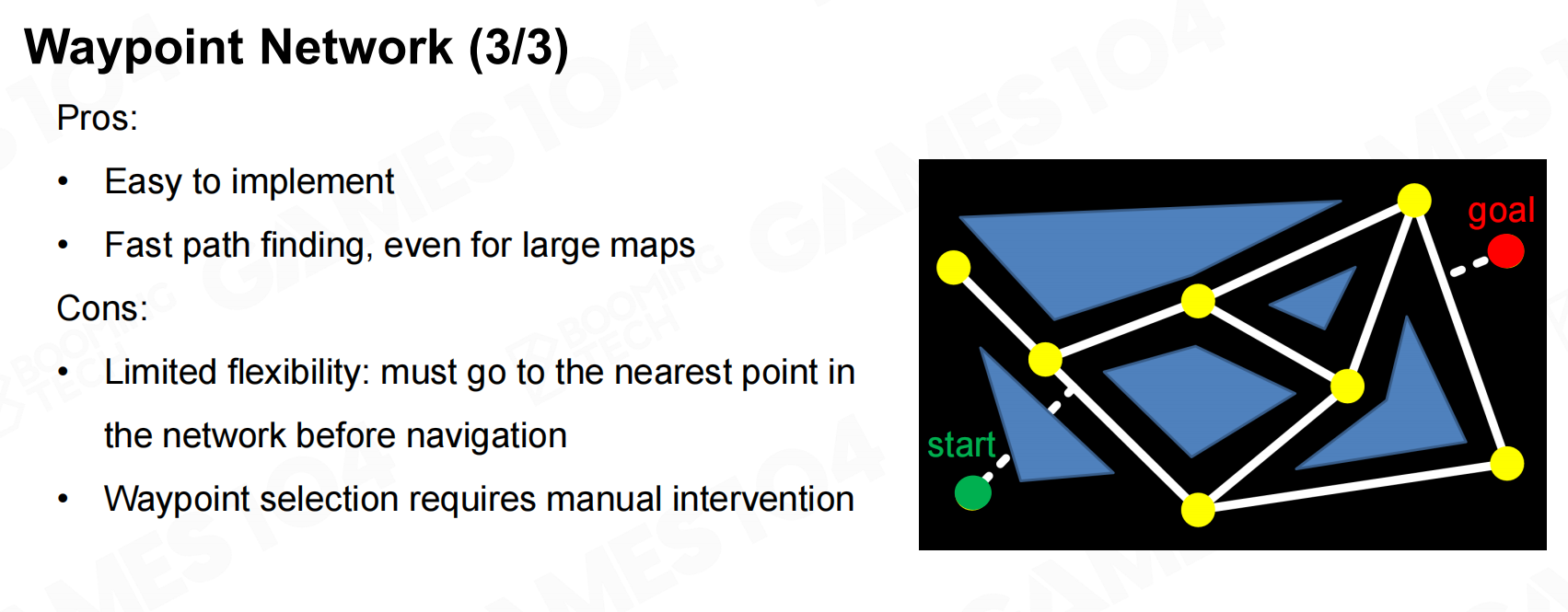 航路点网络3
航路点网络3
网格(Grid)
网格同样是表达游戏地图的经典方法,常用的网格地图包括方格地图、三角形地图或是六边形地图等。 网格
网格
使用网格来表示地图时只需要把不可通行的区域遮挡住就可以了,因此网格可以动态地反映地图环境的变化。 网格2
网格2
显然网格地图同样非常容易实现,而且支持动态更新,也便于调试;而它的缺陷在于网格地图的精度受制于地图分辨率,而且比较占用存储空间,最严重的问题是网格很难表示重叠区域之间的连接关系。 网格3
网格3
寻路网格(Navigation Mesh)
为了克服网格地图的这些问题,人们开发出了寻路网格这样的地图表达形式。在寻路网格中可通行的区域会使用多边形来进行覆盖,这样可以方便地表达不同区域直接相互连接的拓扑关系。 寻路网格
寻路网格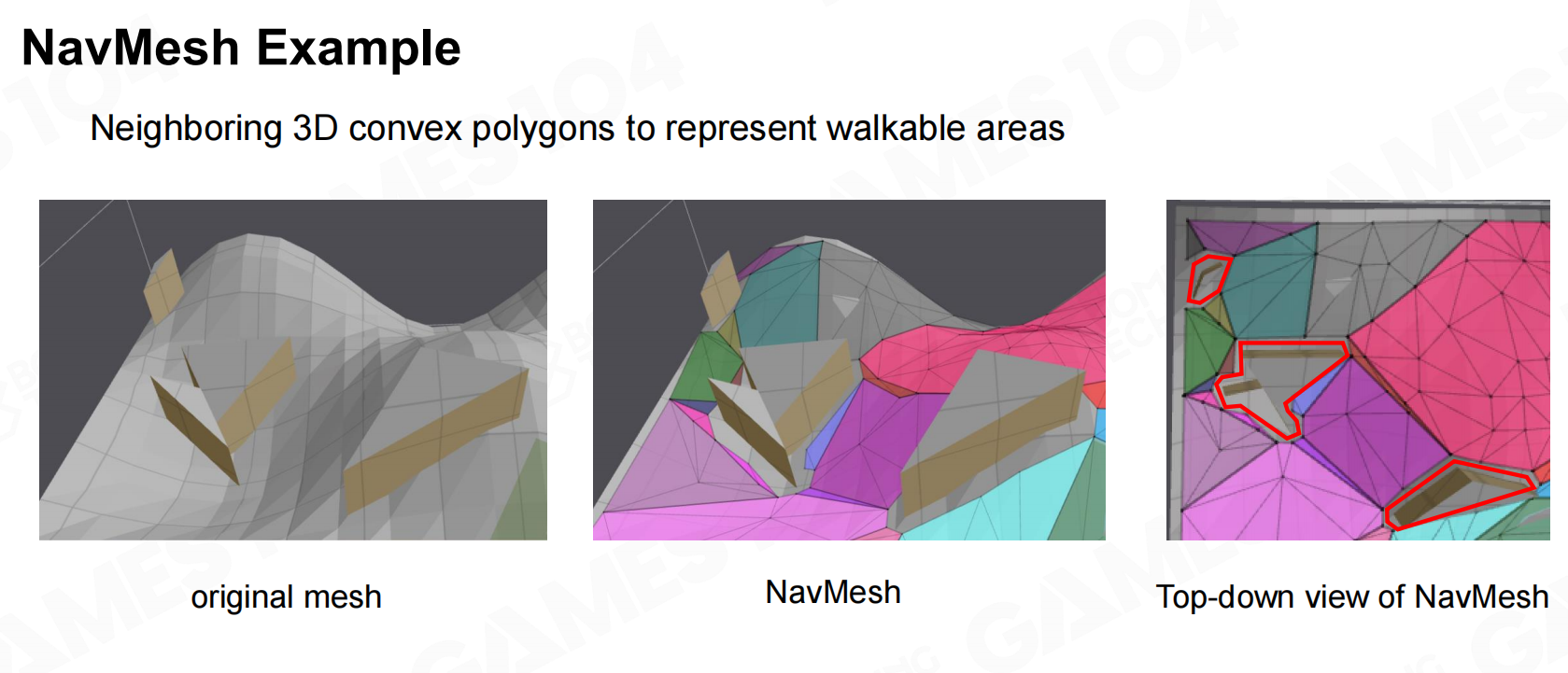 寻路网格例子
寻路网格例子
在寻路网格中我们还会要求每个多边形都必须是凸多边形,这样才能保证角色在行进中不会穿过网格。 寻路网格多边形
寻路网格多边形
寻路网格是现代游戏中广泛应用的地图表达形式,而它的缺陷主要在于生成寻路网格的算法相对比较复杂,而且它无法表达三维空间的拓扑连接关系。 寻路网格优点和缺点
寻路网格优点和缺点
八叉树(Sparse Voxel Octree)
如果要制作三维空间中的地图则可以考虑八叉树这样的数据结构。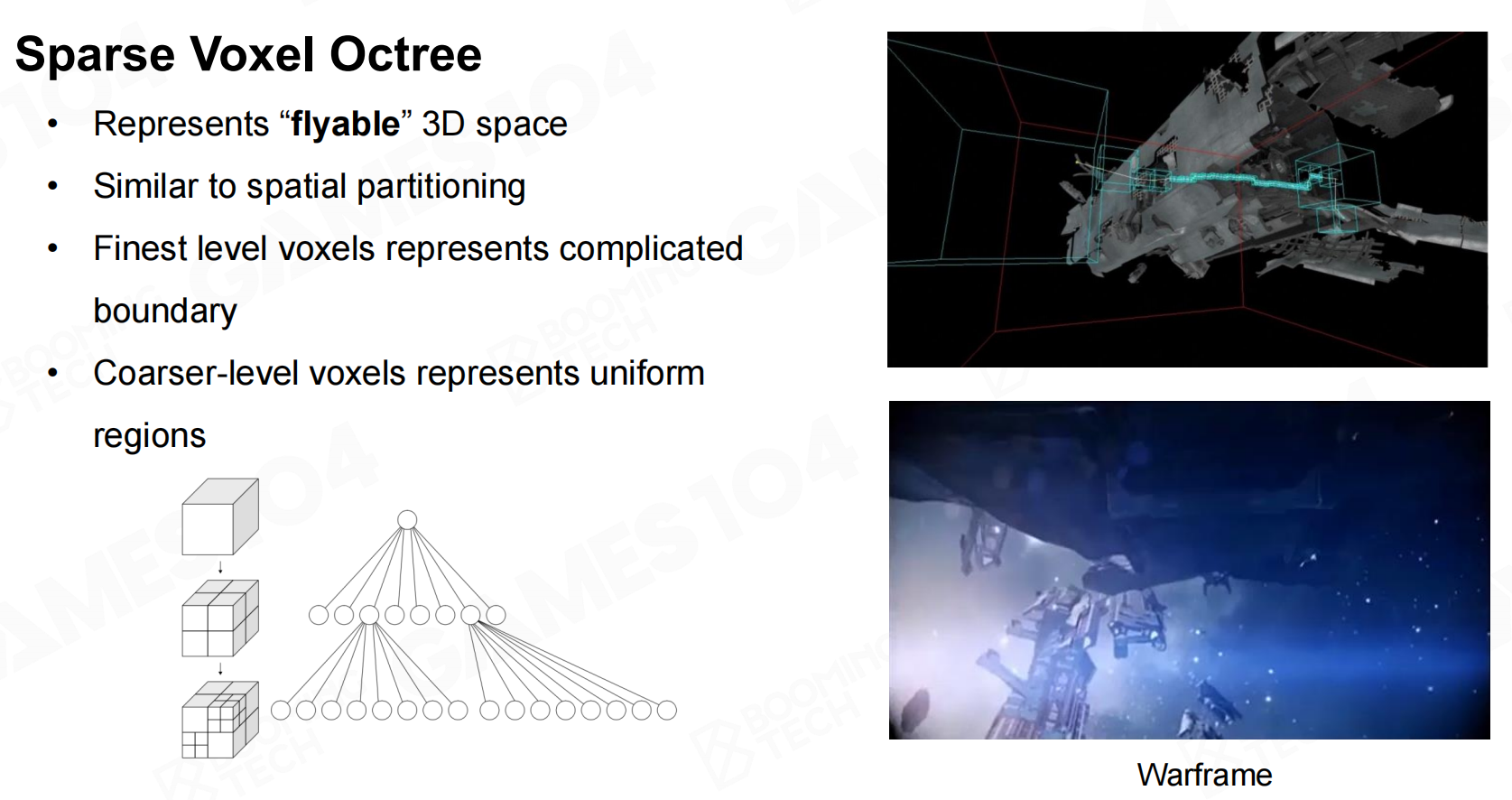 八叉树
八叉树
寻路(Path Finding)
得到游戏地图后就可以使用寻路算法来计算路径了,当然无论我们使用什么样的地图表达方式我们首先都需要把游戏地图转换为拓扑地图,然后再使用相应的算法进行寻路。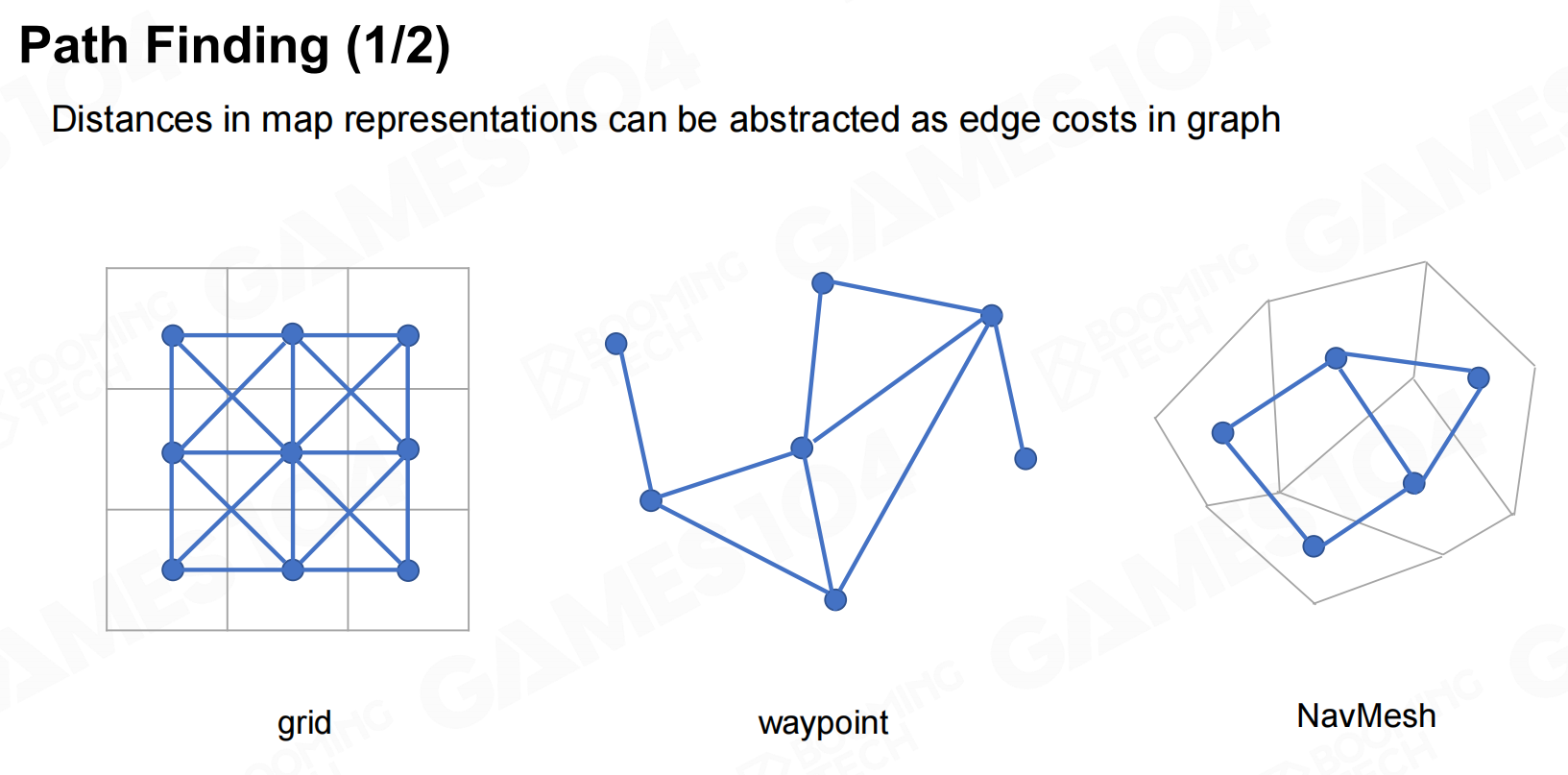 寻路
寻路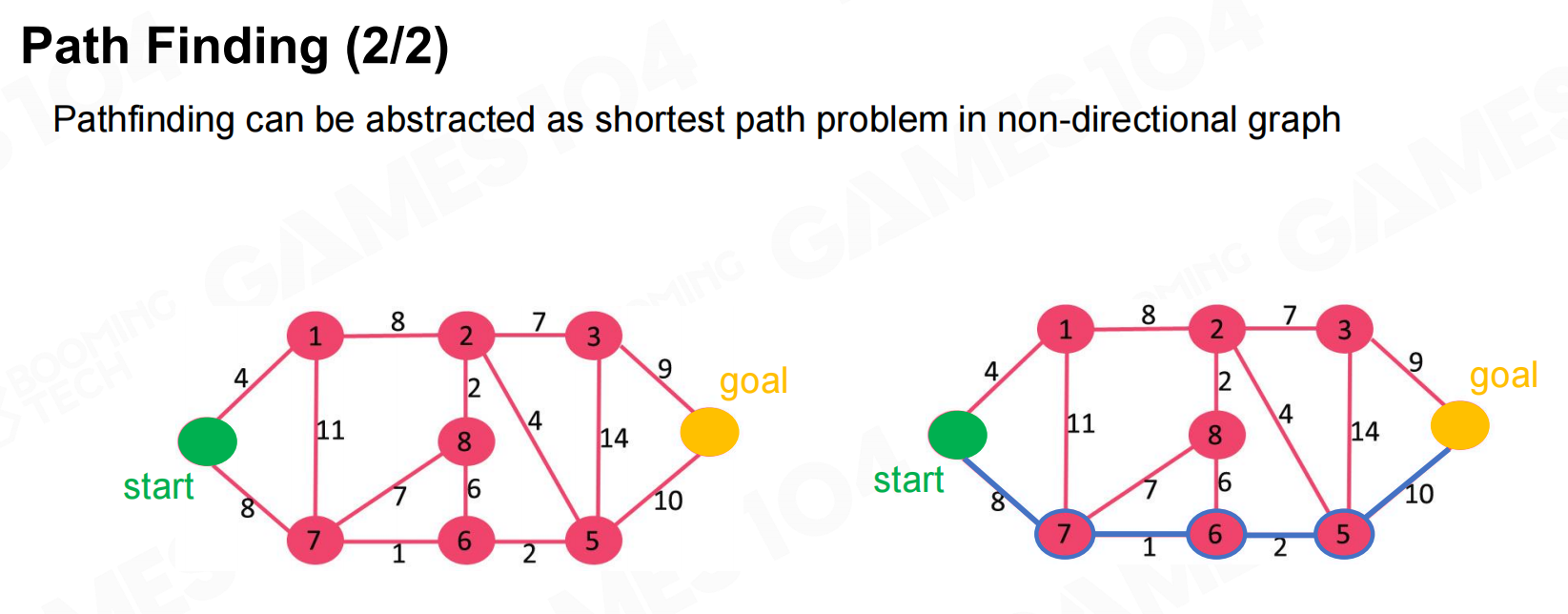 寻路2
寻路2
深度优先搜索(Depth-First Search)
寻路算法的本质是在图上进行搜索,因此我们可以使用深度优先搜索(depth-first search, DFS)来进行求解。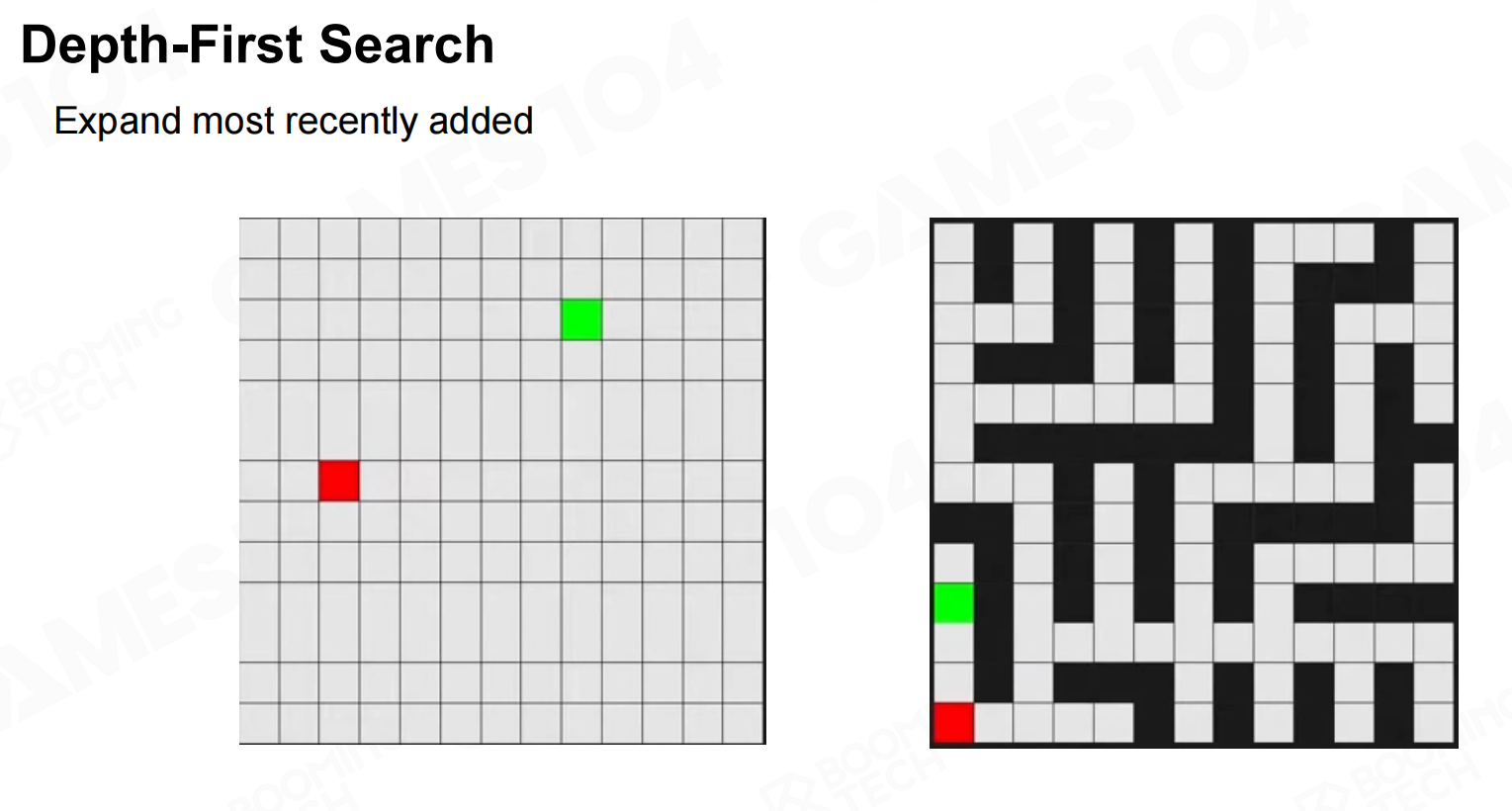 深度优先搜索
深度优先搜索
广度优先搜索(Breadth-First Search)
另一种常用的图搜索算法是广度优先搜索(breadth-first search, BSF)。 广度优先搜索
广度优先搜索
Dijkstra算法(Dijkstra Algorithm)
直接使用DFS或是BFS往往是过于低效的,实践中更常用的寻路算法是Dijkstra算法(Dijkstra algorithm)。 Dijkstra算法
Dijkstra算法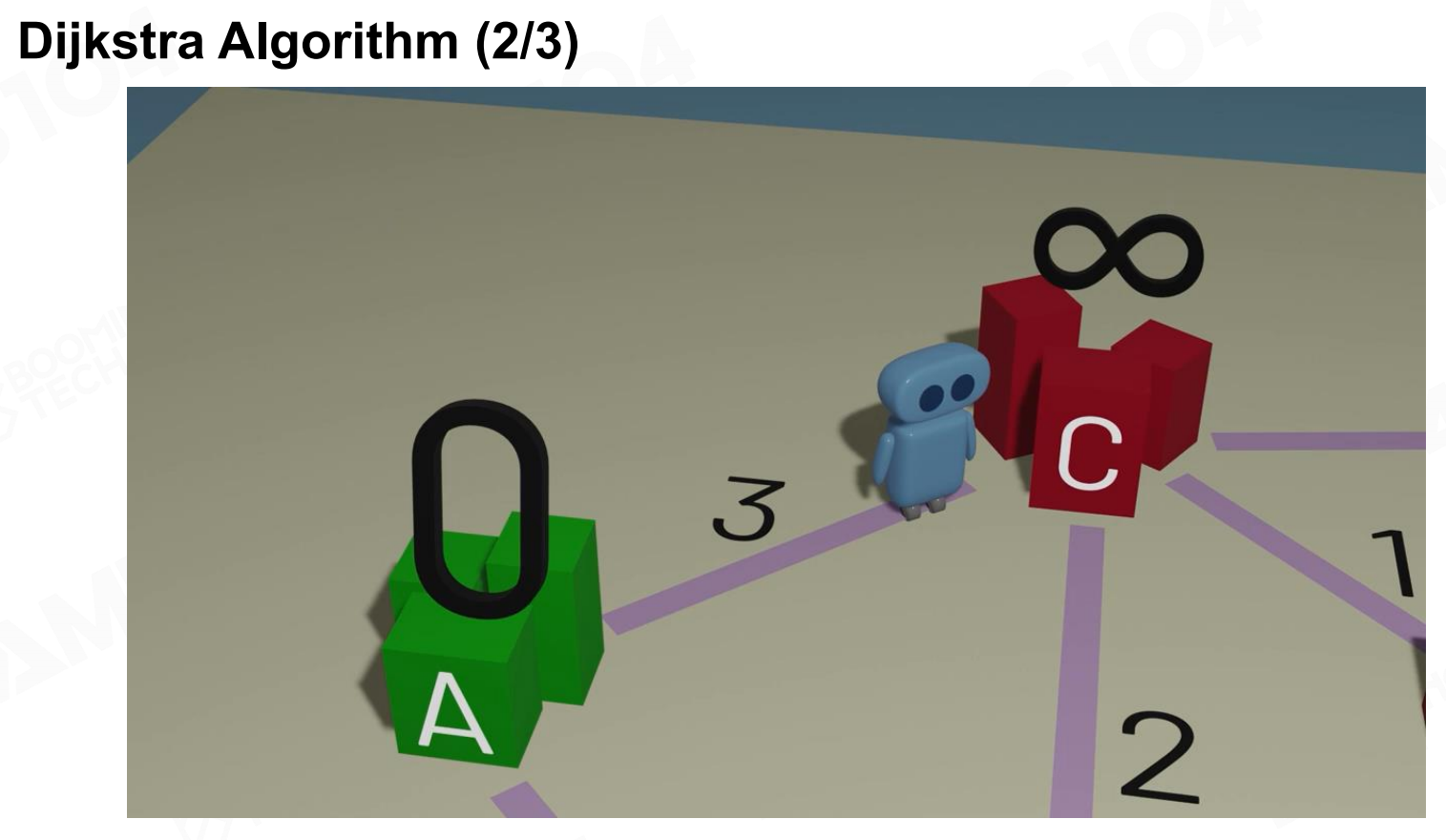 Dijkstra算法2
Dijkstra算法2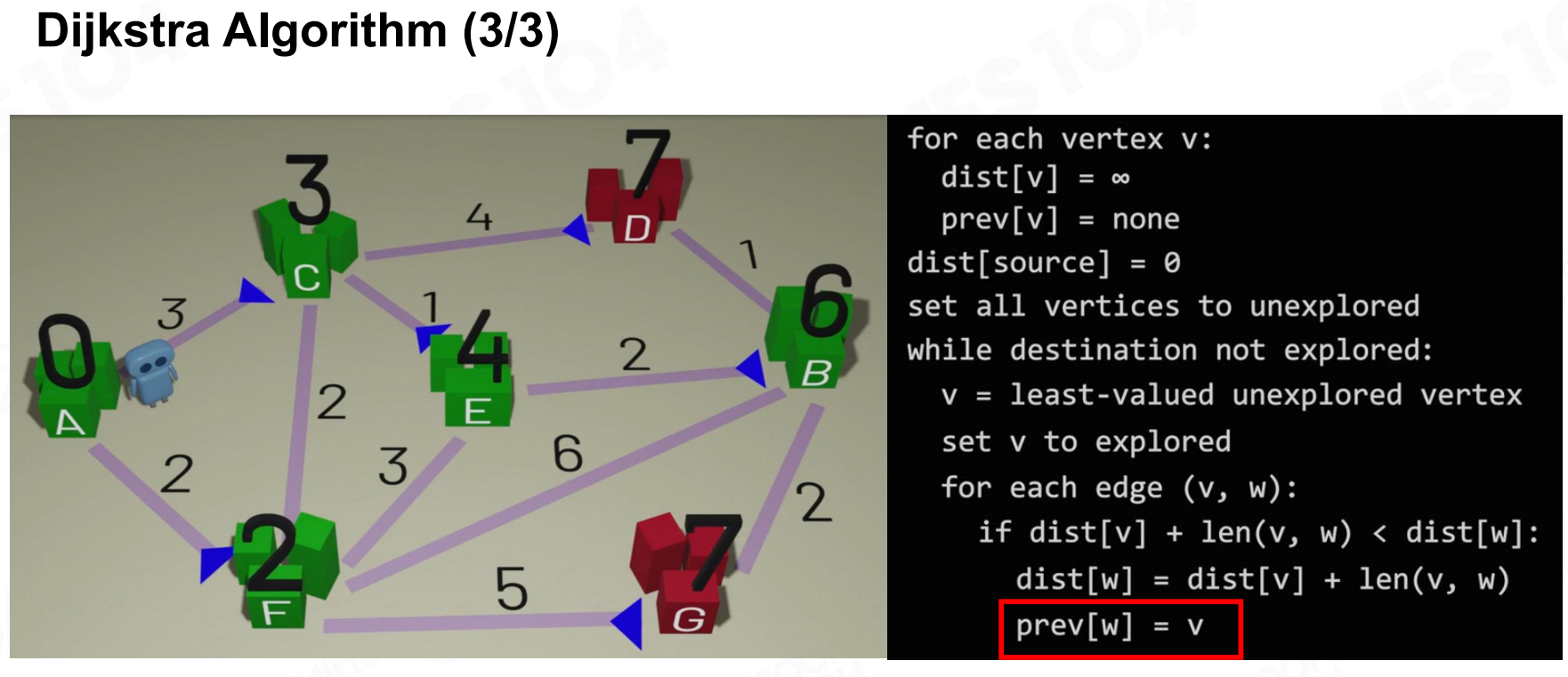 Dijkstra算法3
Dijkstra算法3
A Star(A*)
Dijkstra算法可以计算从起始节点出发到图上任意节点的最短路径,但它的缺陷在于图上很多节点对于我们想要计算的路径是没有意义的。因此人们还提出了A star算法来进行改进,在A star算法中通过引入一个启发式函数来控制节点访问的倾向性,使得路径的搜索会更倾向于访问目标点。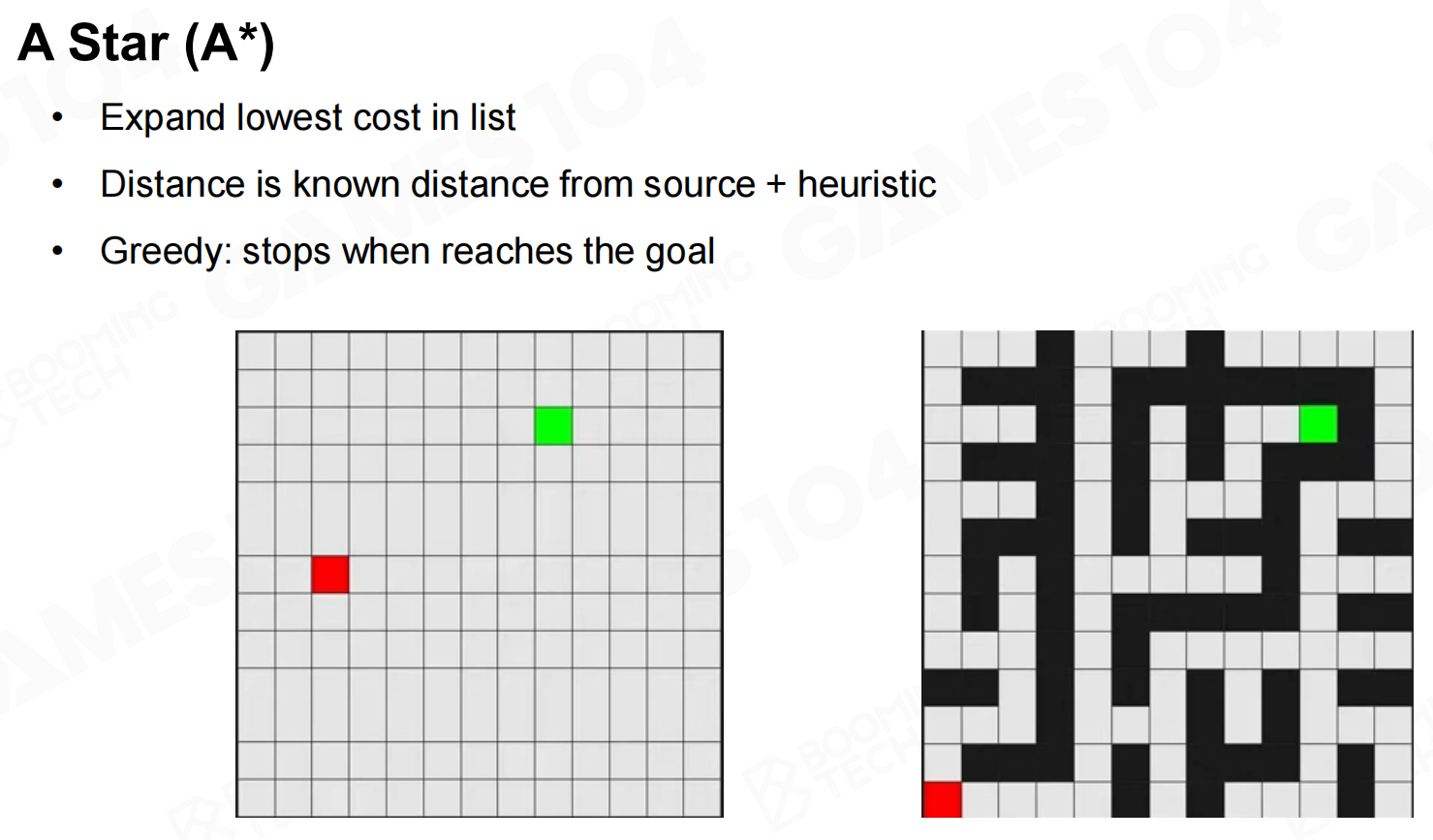 A*
A* A*-成本计算
A*-成本计算
在网格地图中常用的启发函数包括Manhattan距离等。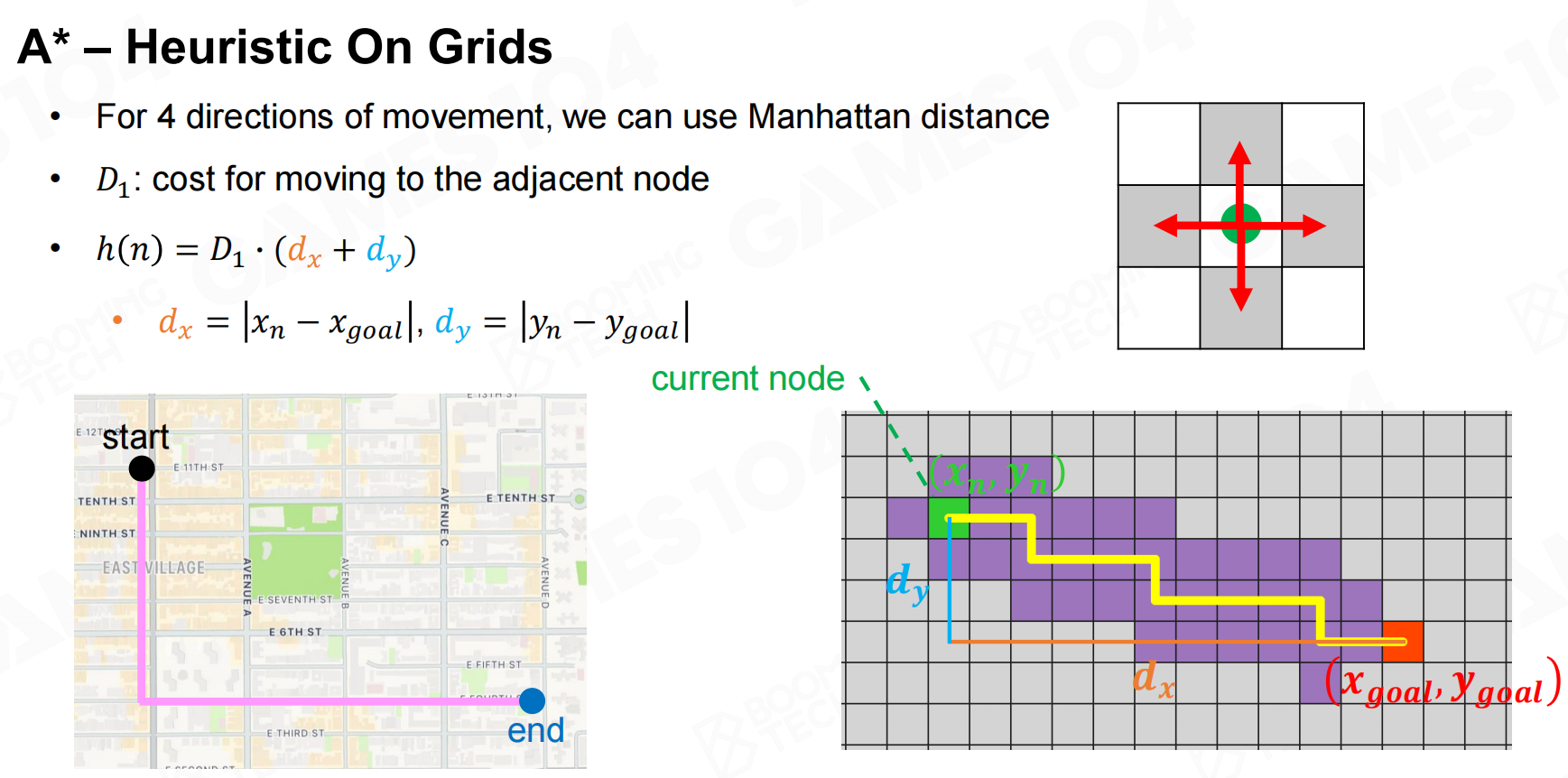 A*-网格上的启发
A*-网格上的启发
而在寻路网格中则可以使用欧氏距离作为启发函数。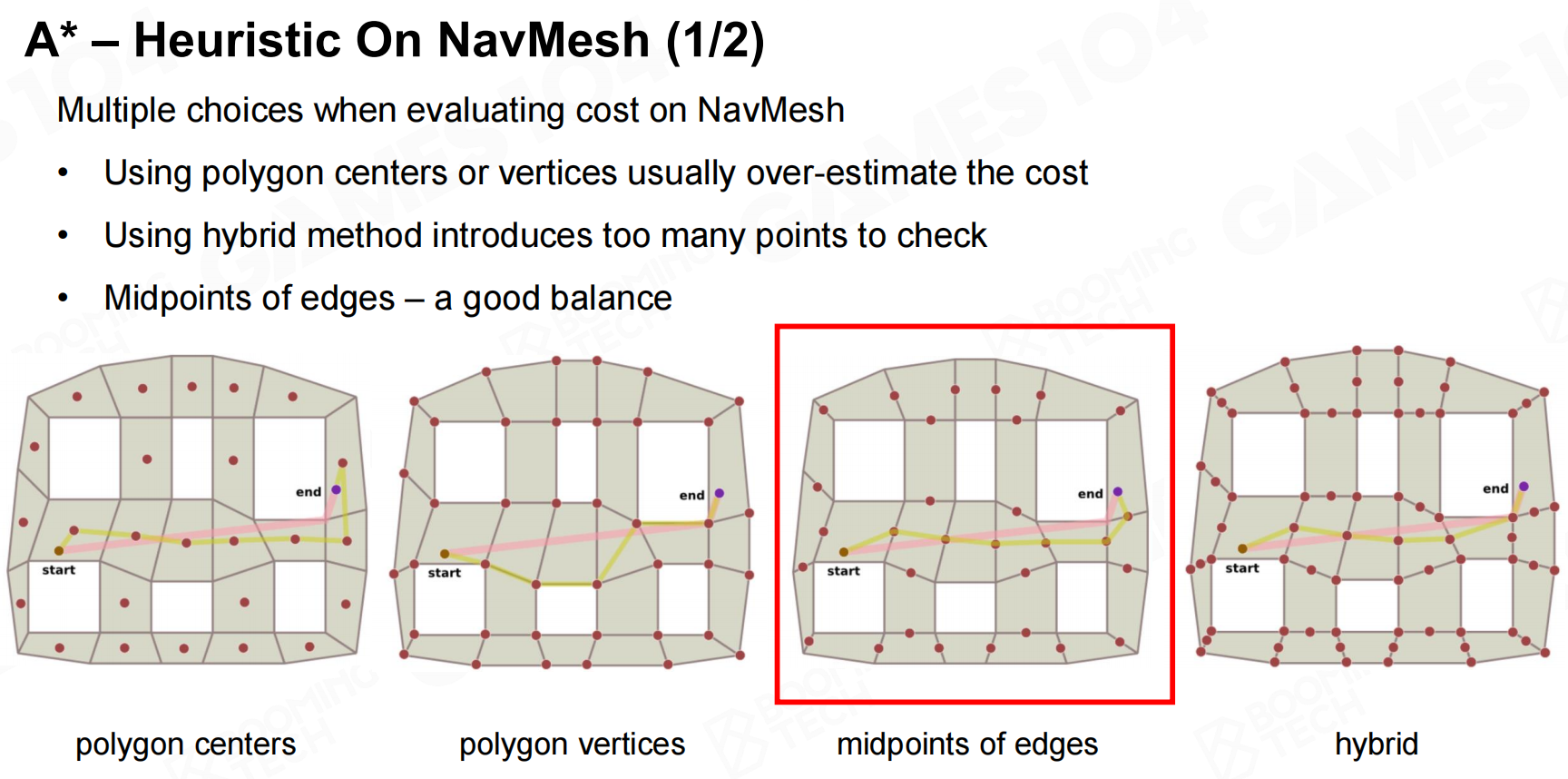 A*-寻路网格上的启发
A*-寻路网格上的启发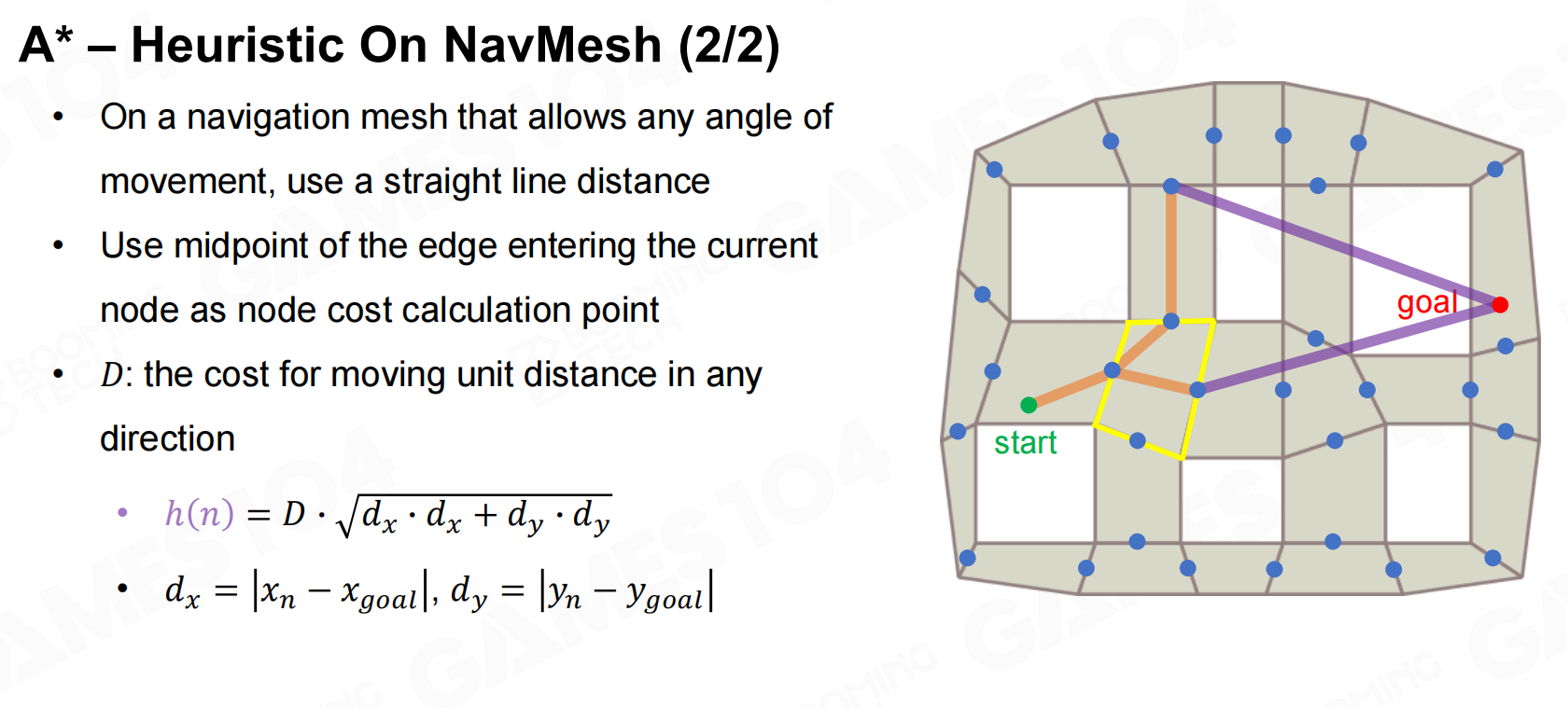 A*-寻路网格上的启发2
A*-寻路网格上的启发2 A*-寻路网格预排
A*-寻路网格预排
显然启发式算法的设计对于最终计算得到的路径会产生显著的影响。当启发函数的值过低时可能会需要更多次循环才能寻找到路径,而当启发函数值过高时则可能无法找到最短路径。因此在实际应用中需要进行一定的权衡。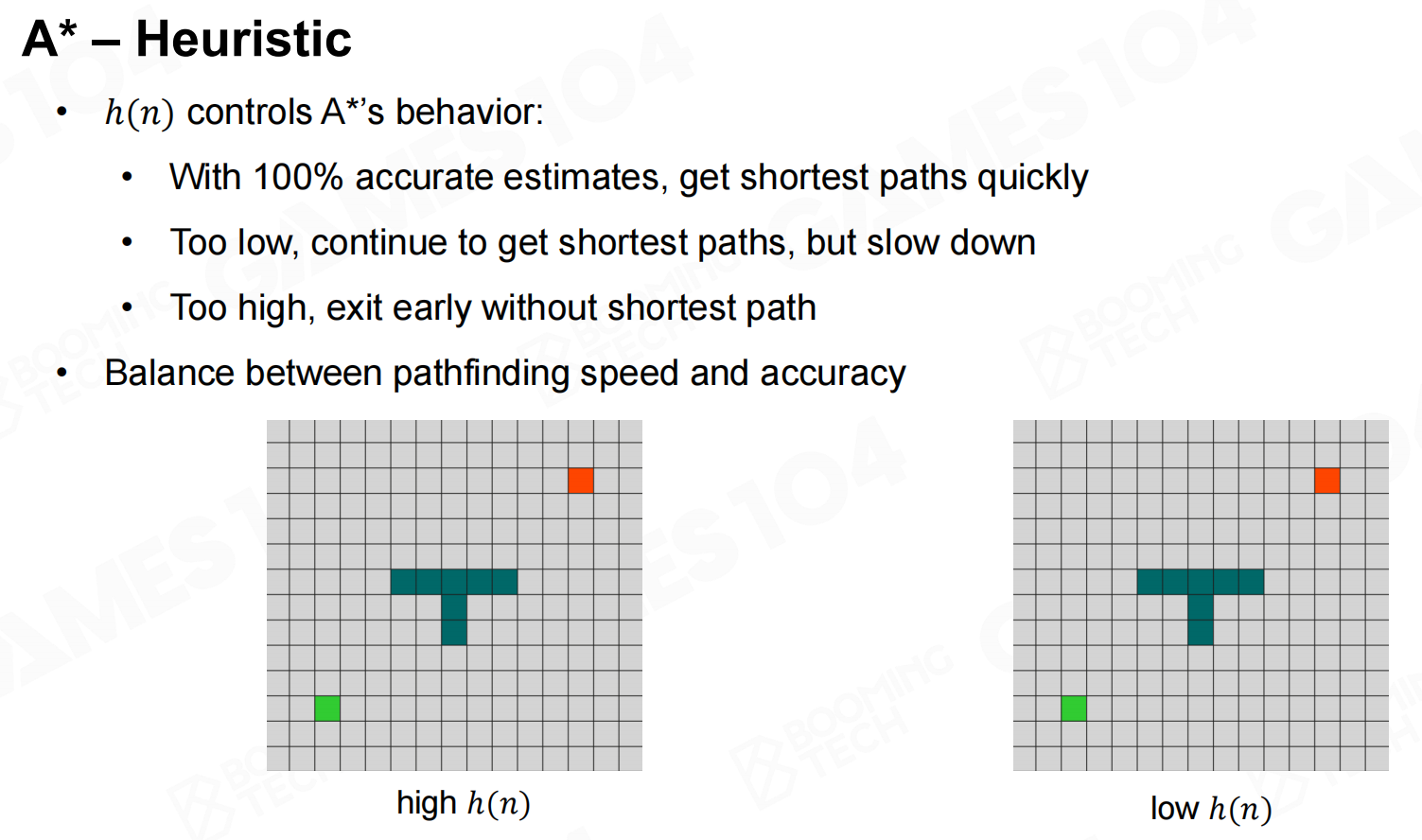 A*-启发
A*-启发
路径平滑(Path Smoothing)
直接使用寻路算法得到的路径往往包含各种各样的折线不够光滑,因此我们还需要使用一些路径平滑的算法来获得更加光滑的路径。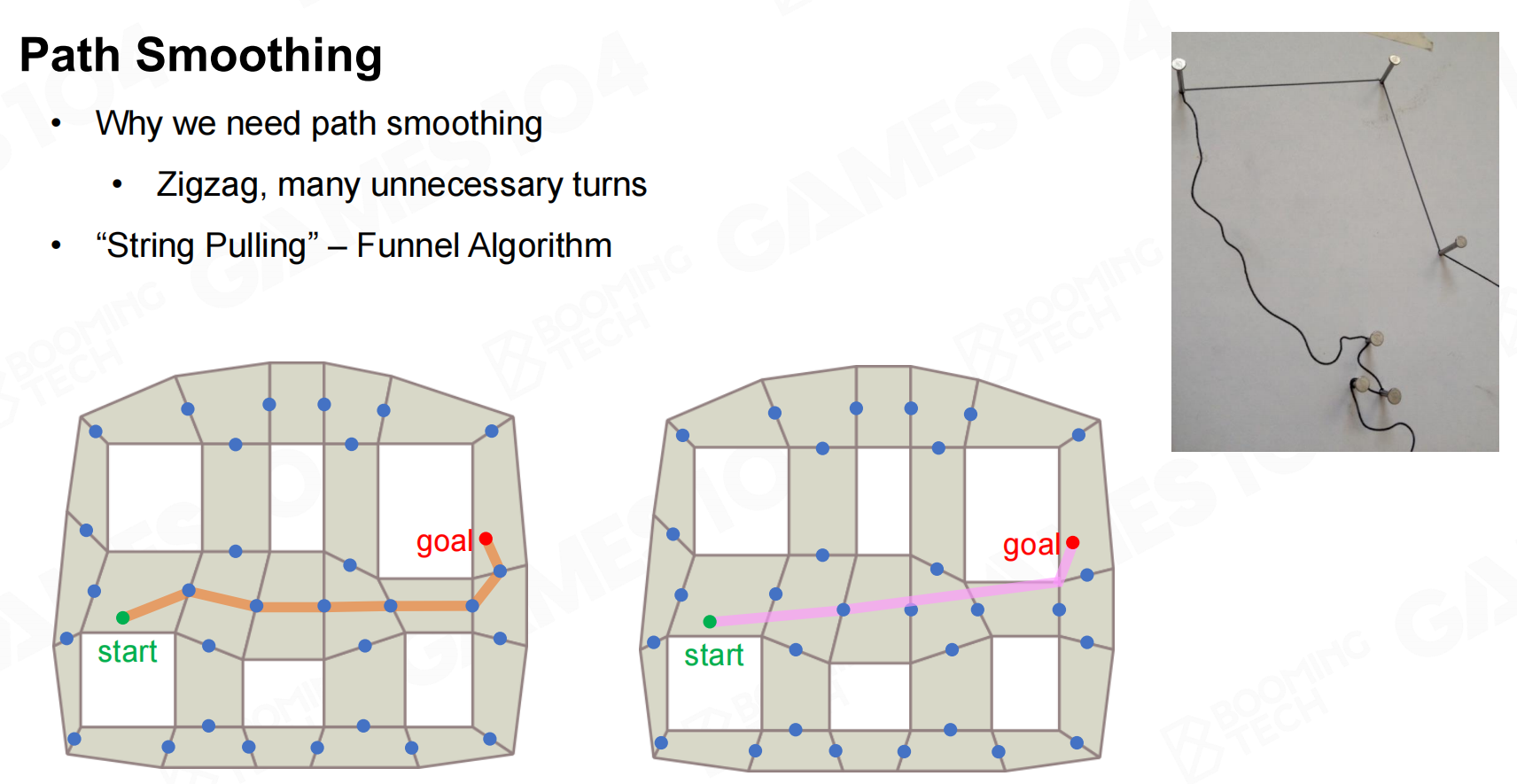 路径平滑
路径平滑
游戏导航中比较常用funnel算法来对折线路径进行平滑,它不仅可以应用在二维平面上也可以应用在寻路网格上。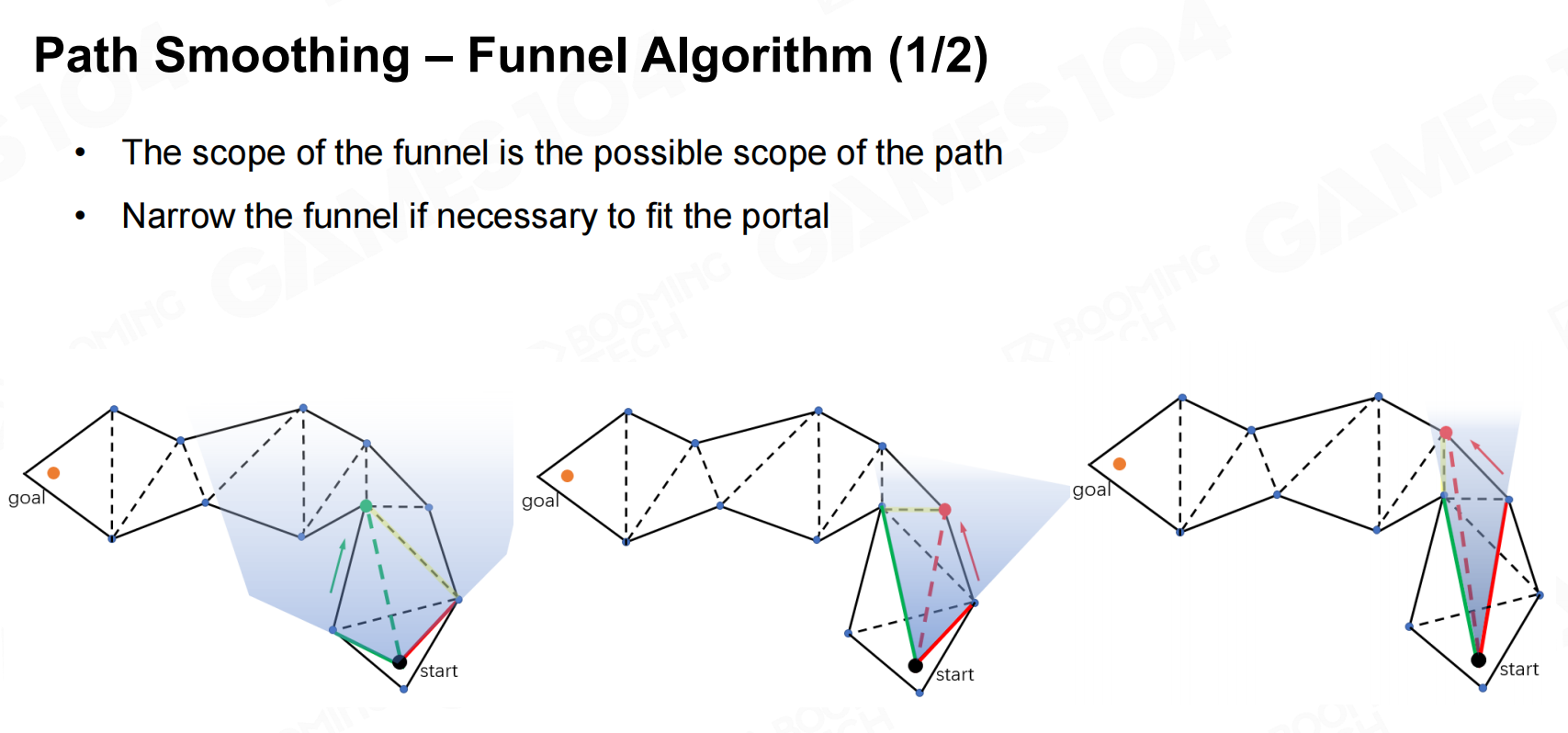 路径平滑-漏斗算法
路径平滑-漏斗算法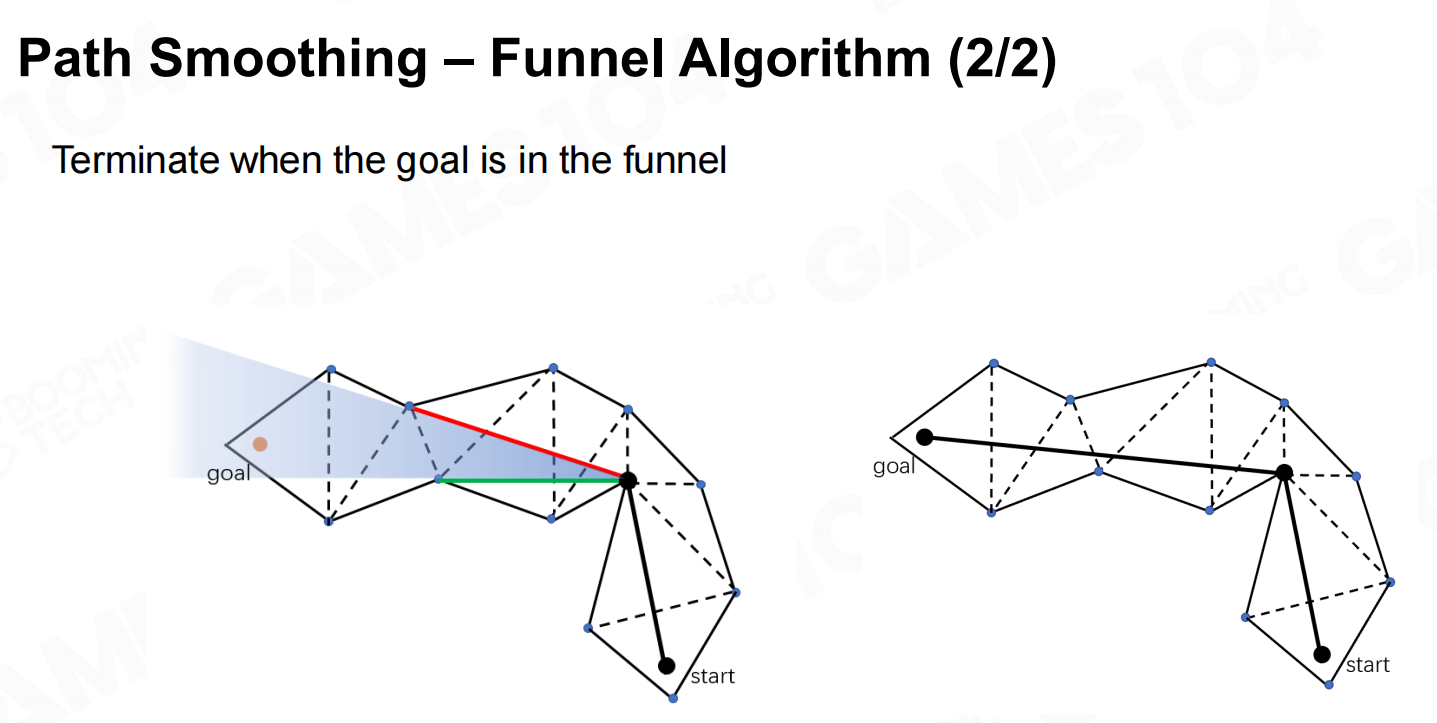 路径平滑-漏斗算法2
路径平滑-漏斗算法2
导航网格生成(NavMesh Generation)
如何从游戏地图上生成寻路网格是一个相对困难的问题。 导航网格生成
导航网格生成
一般来说想要生成寻路网格首先需要将地图转换为体素,然后在体素地图上计算距离场得到区域的划分,最后就可以在划分好的区域中生成一个凸多边形网格作为寻路网格。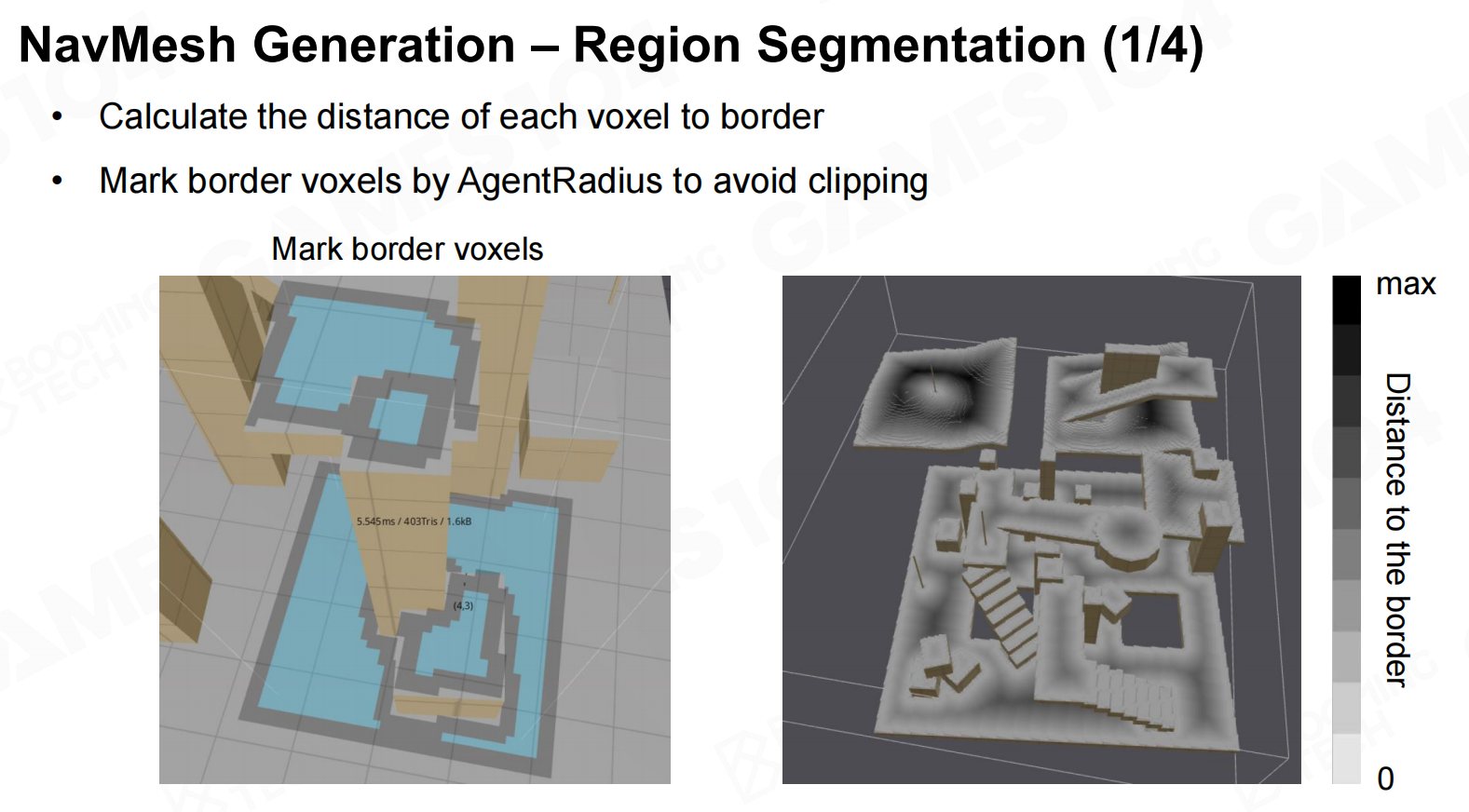 导航网格生成-区域分割
导航网格生成-区域分割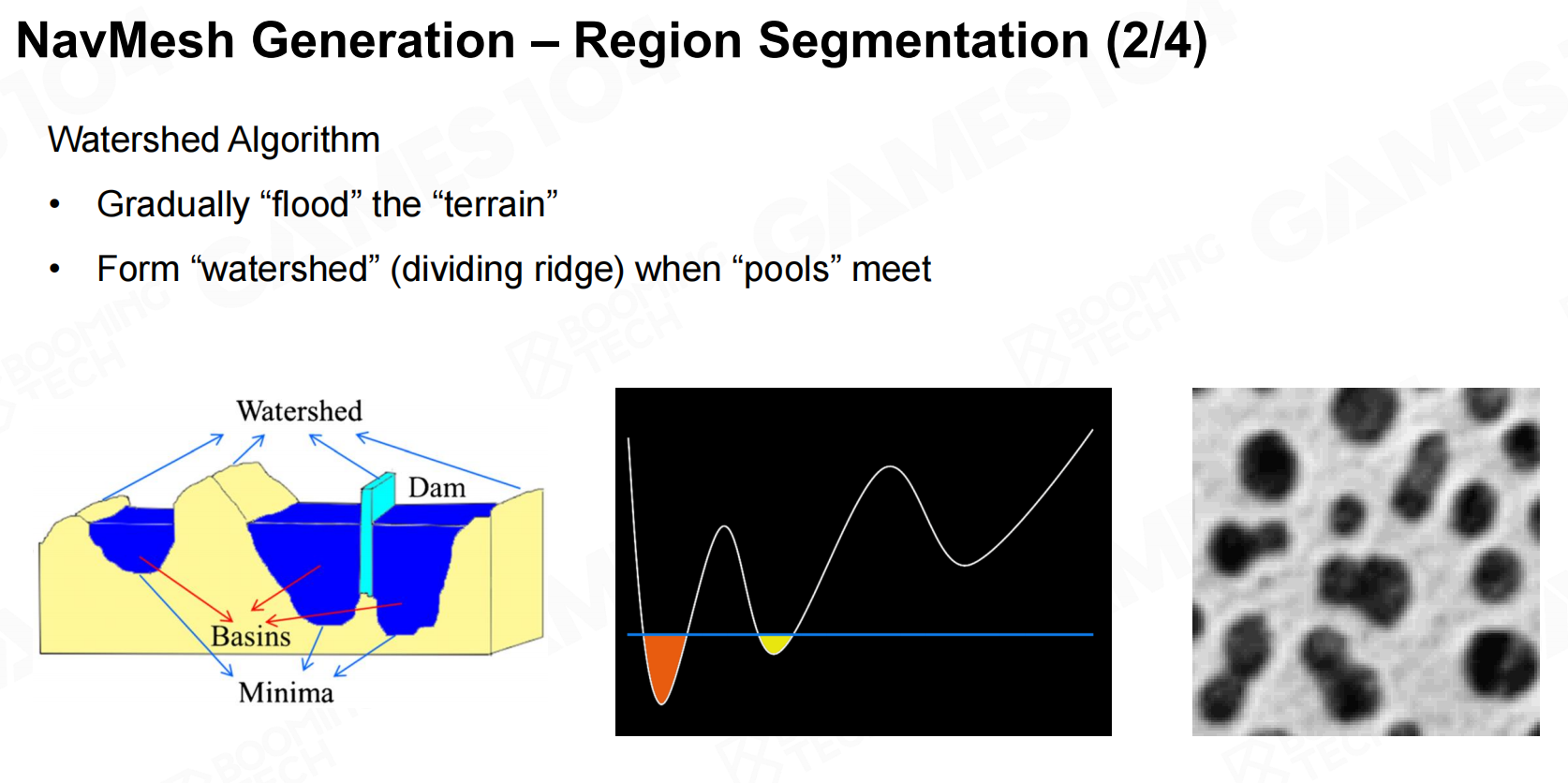 导航网格生成-区域分割2
导航网格生成-区域分割2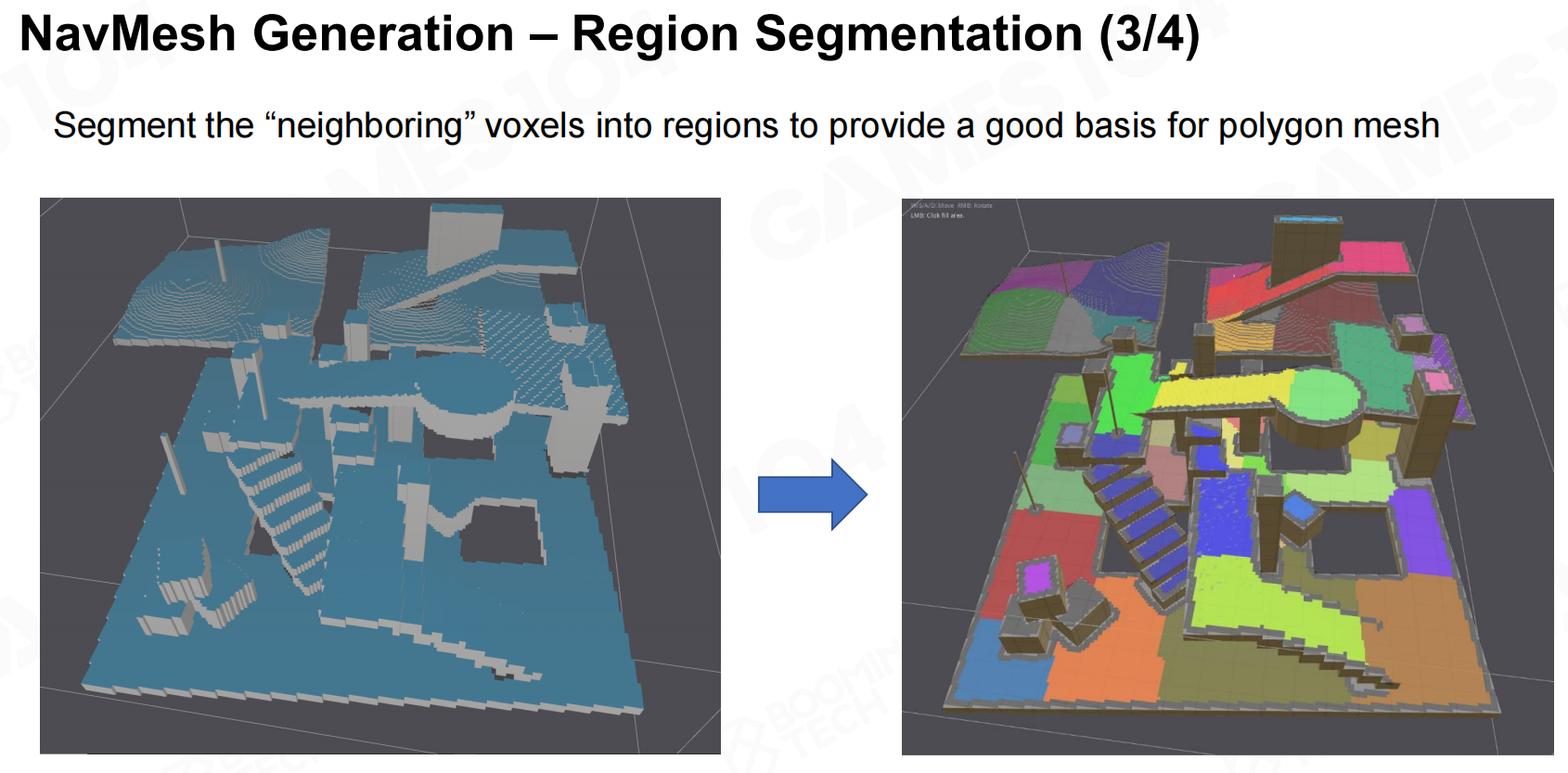 导航网格生成-区域分割3
导航网格生成-区域分割3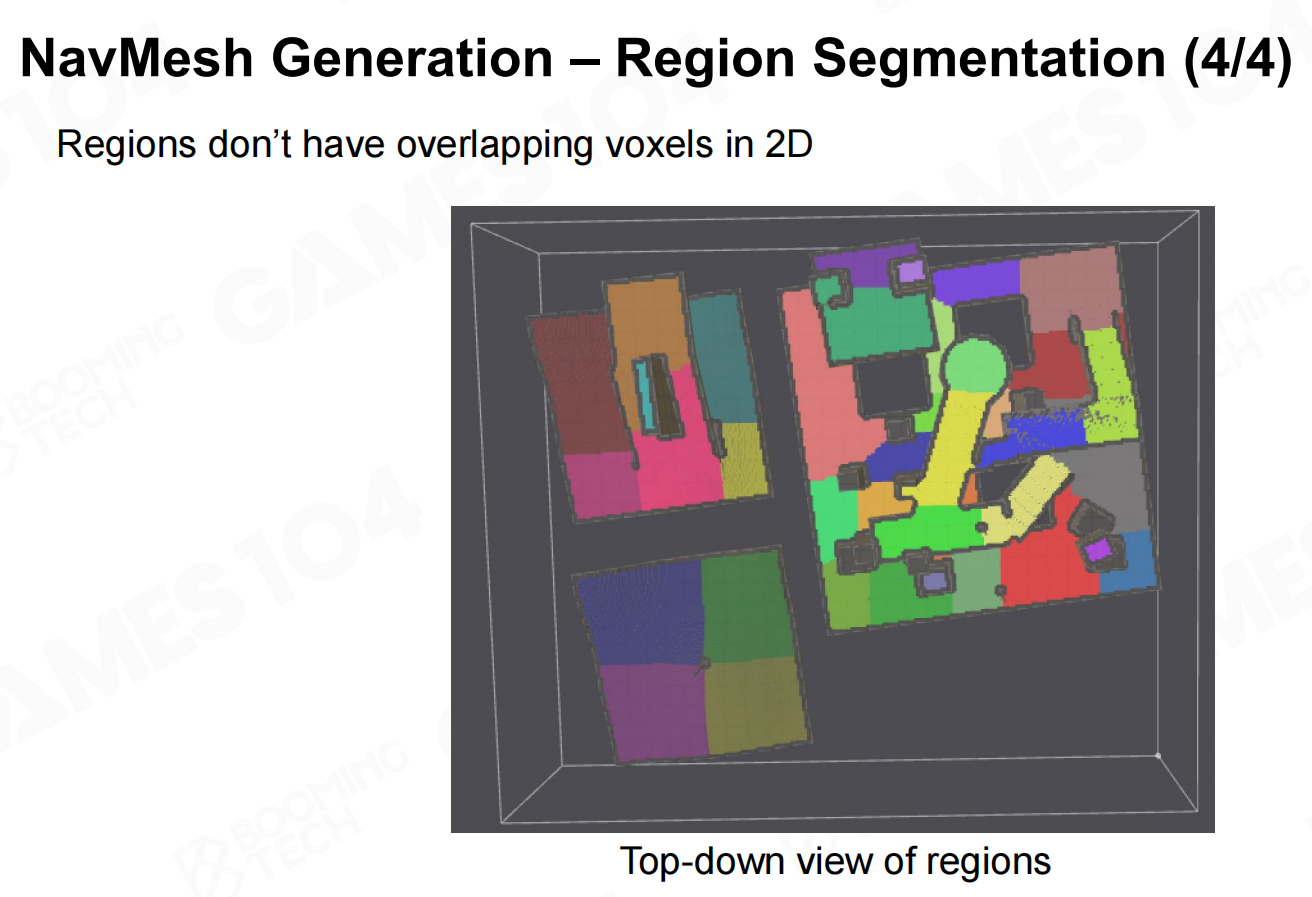 导航网格生成-区域分割4
导航网格生成-区域分割4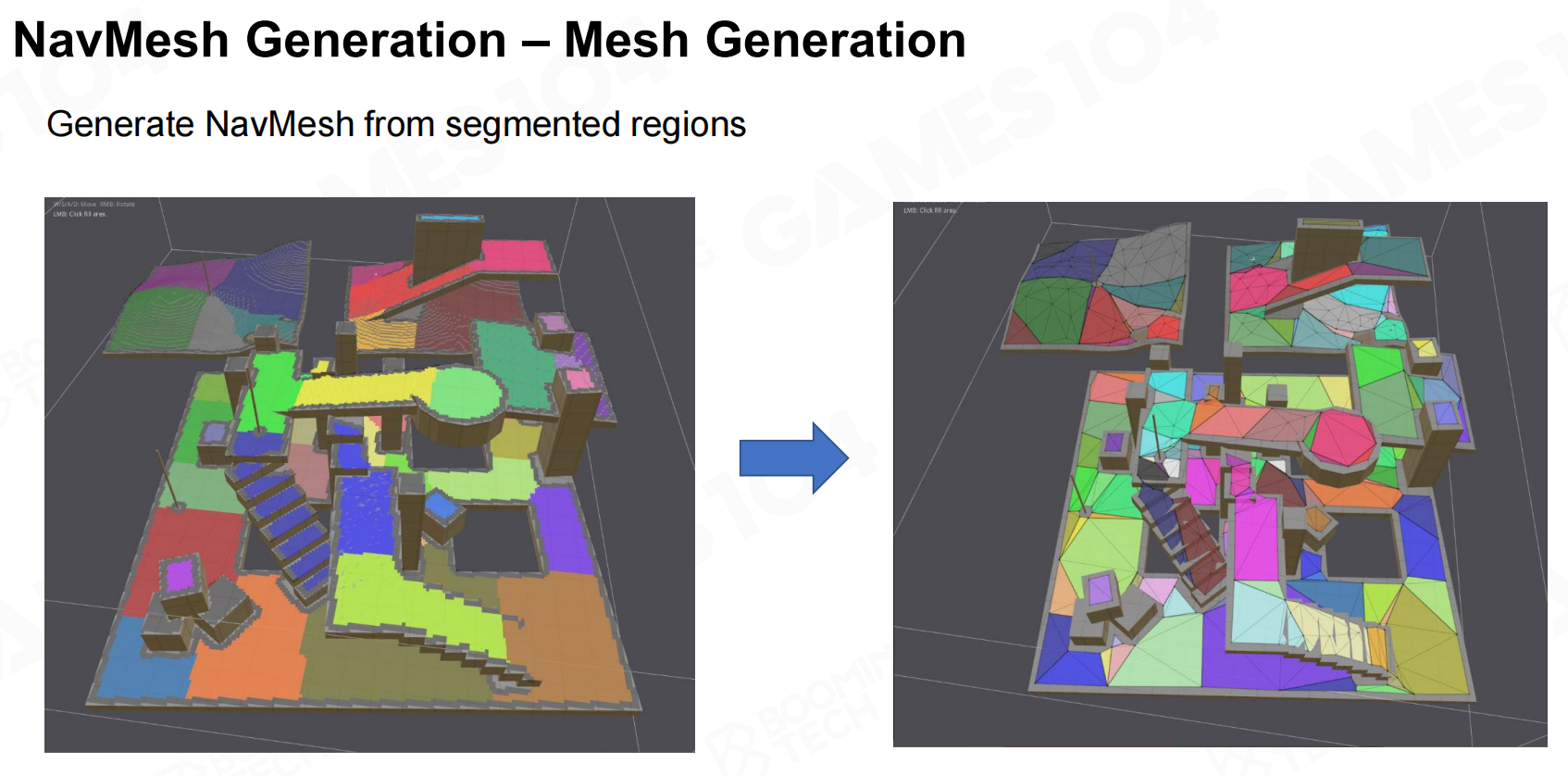 导航网格生成-网格生成
导航网格生成-网格生成
除此之外我们还可以在多边形上设置不同的flag来触发不同的动画、声效以及粒子效果。 导航网格高级特征-多边形标志
导航网格高级特征-多边形标志
对于动态的环境我们可以把巨大的场景地图划分为若干个tile。当某个tile中的环境发生改变时只需要重新计算该处的路径就可以得到新的路径。 导航网格高级特征-瓦片
导航网格高级特征-瓦片
还需要注意的是使用自动化算法生成的寻路网格是不包括传送点这样的信息的,有时为了提升玩家和场景的互动我们还需要手动设置这些传送点。当然这会导致寻路算法更加复杂。 导航网格高级特征-非网格链接
导航网格高级特征-非网格链接
转向系统(Steering)
得到最优路径后就可以根据路径来控制角色前进了。但在实际游戏中角色可能包含自身的运动学约束使得我们无法严格按照计算出的路径进行运动,这一点对于各种载具尤为明显。因此我们还需要结合steering算法来调整实际的行进路径。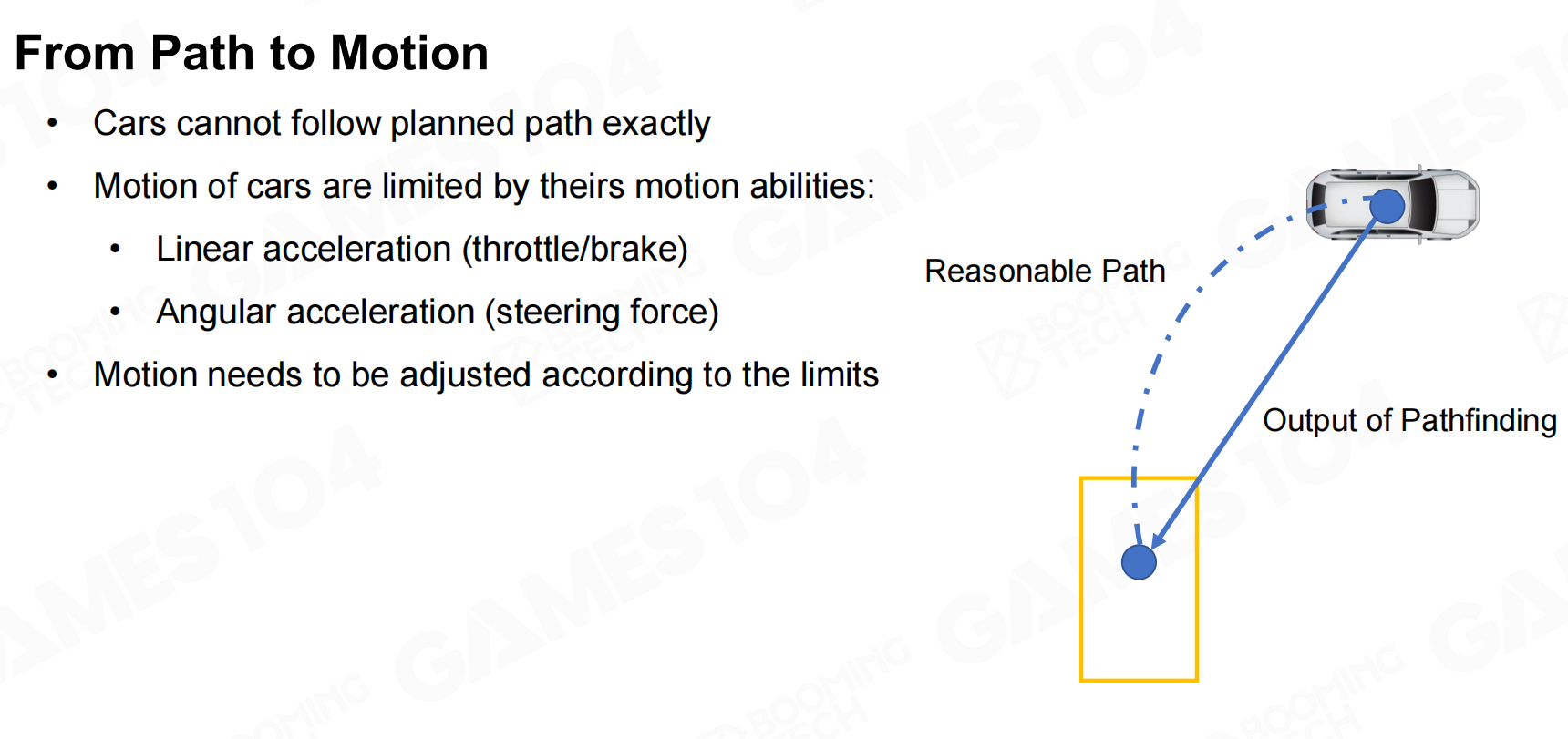 从路径到运动
从路径到运动
steering算法可以按照行为分为以下几种:追赶和逃脱(seek/flee)、速度匹配(velocity match)以及对齐(align)。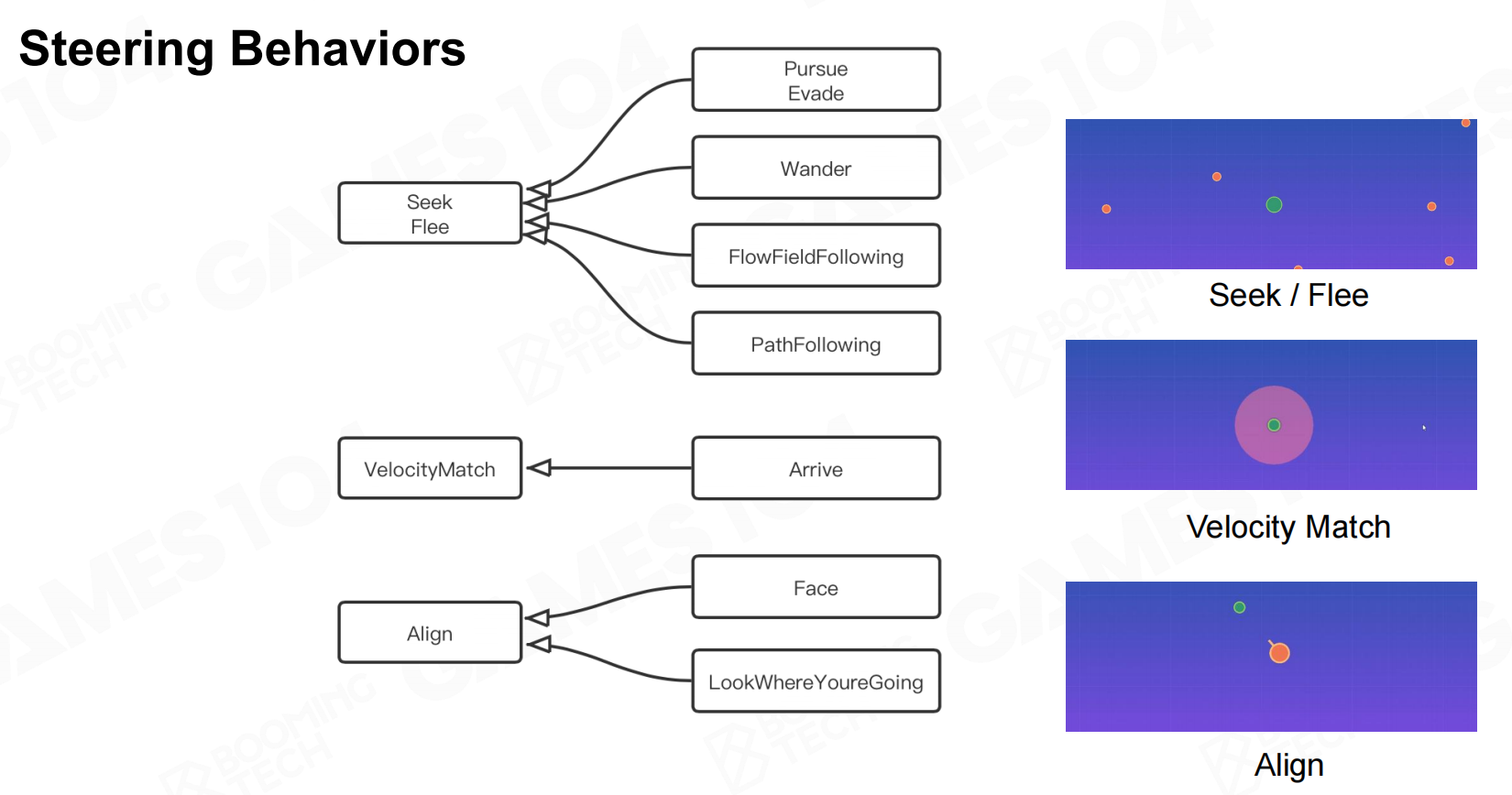 转向行为
转向行为
躲避或巡逻(Seek/Flee)
seek/flee的要求是根据自身和目标当前的位置来调整自身的加速度从而实现追赶或是逃脱的行为,像游戏中的跟踪、躲避或是巡逻等行为都可以使用seek/flee来实现。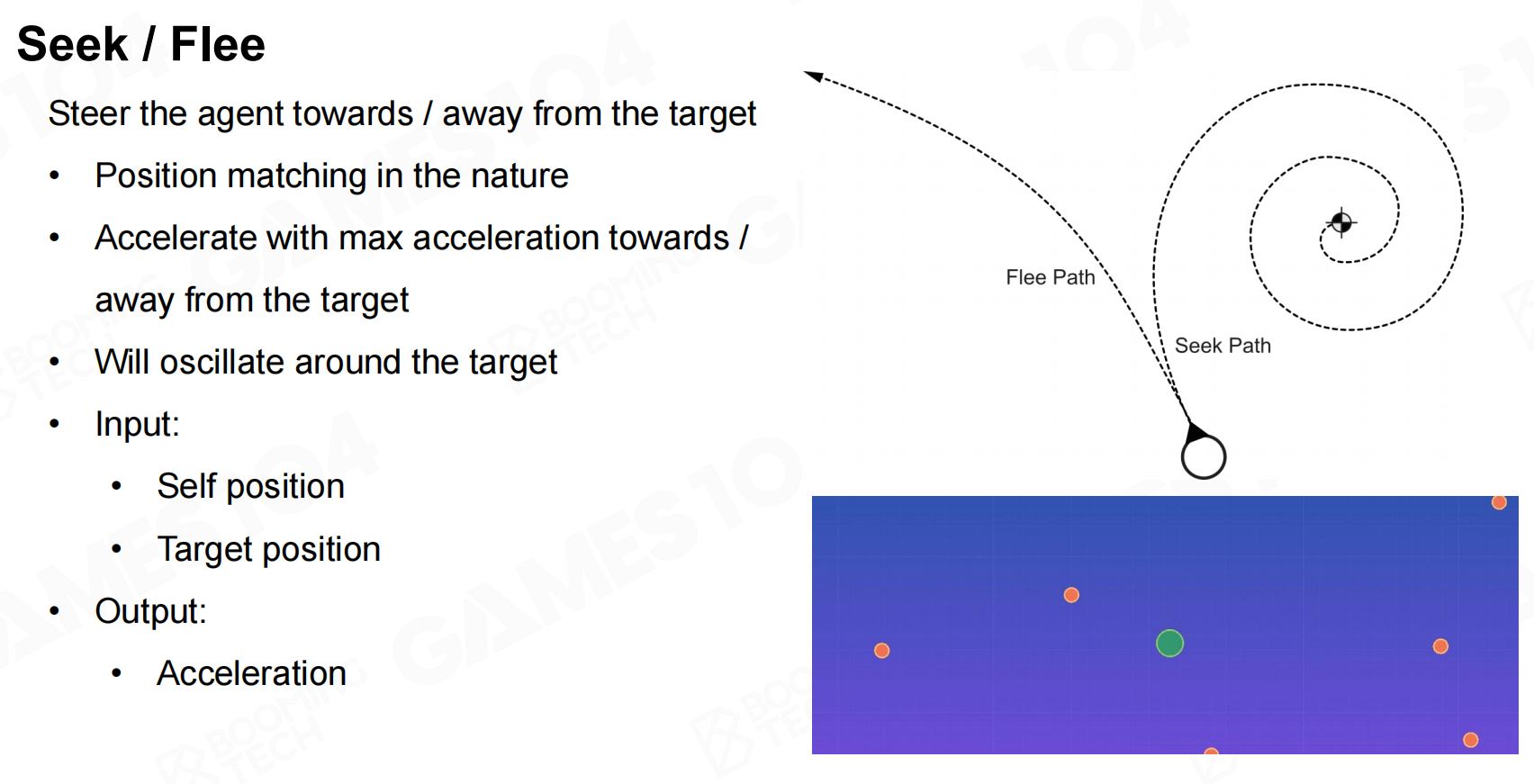 躲避或巡逻
躲避或巡逻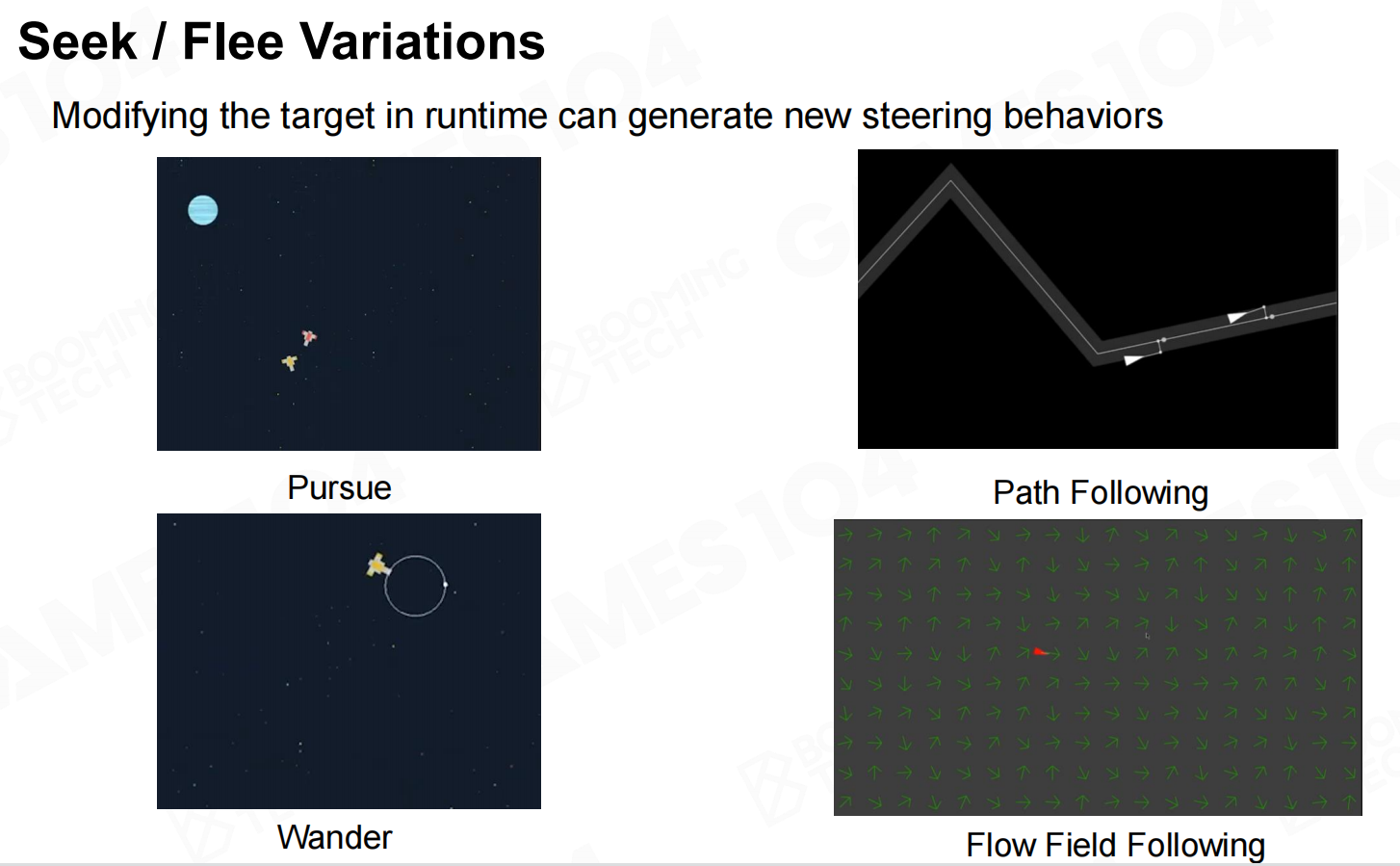 躲避或巡逻变化
躲避或巡逻变化
速度匹配(Velocity Match)
velocity match的目的是利用当前自身和目标的相对速度以及匹配时间来进行控制,使得自身可以按指定的速度到达目标位置。 速度匹配
速度匹配
对齐(Align)
align则是从角度和角加速度的层面进行控制,使得自身的朝向可以接近目标。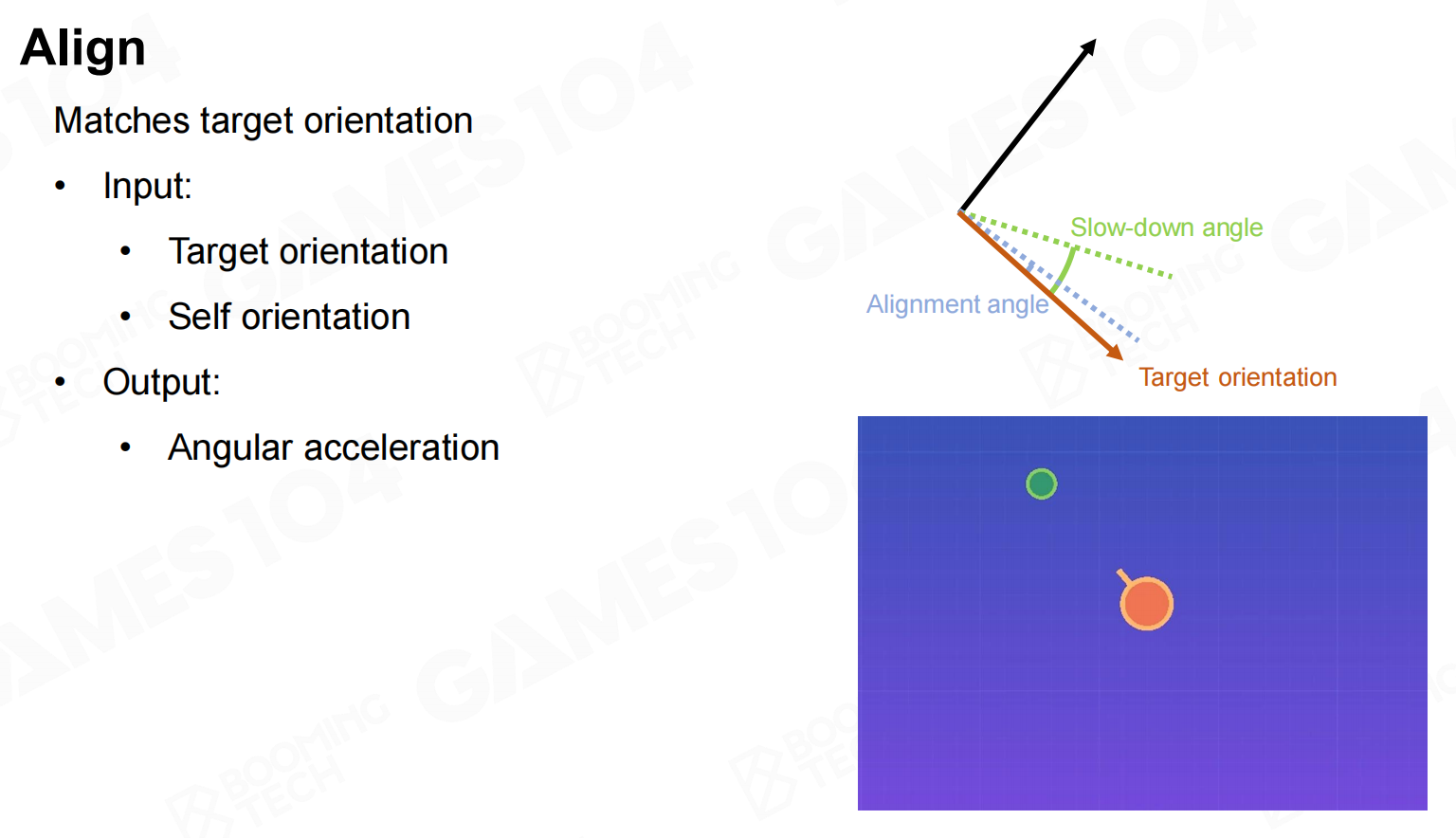 对齐
对齐
群体模拟(Crowd Simulation)
群体模拟(crowd simulation)是游戏AI必须要处理的问题。在游戏场景中往往会具有大量的NPC,如何控制和模拟群体性的行为是现代游戏的一大挑战。 群体
群体
游戏场景中群体模拟的先驱是Reynolds,他同时也是steering系统的提出者。目前游戏中群体行为模拟的方法主要可以分为三种:微观模型(microscopic models)、宏观模型(macroscopic models)以及混合模型(mesoscopic models)。 群体模拟模型
群体模拟模型
微观模型(Microscopic Models)
微观模型的思想是对群体中每一个个体进行控制从而模拟群体的行为,通常情况下我们可以设计一些规则来控制个体的行为。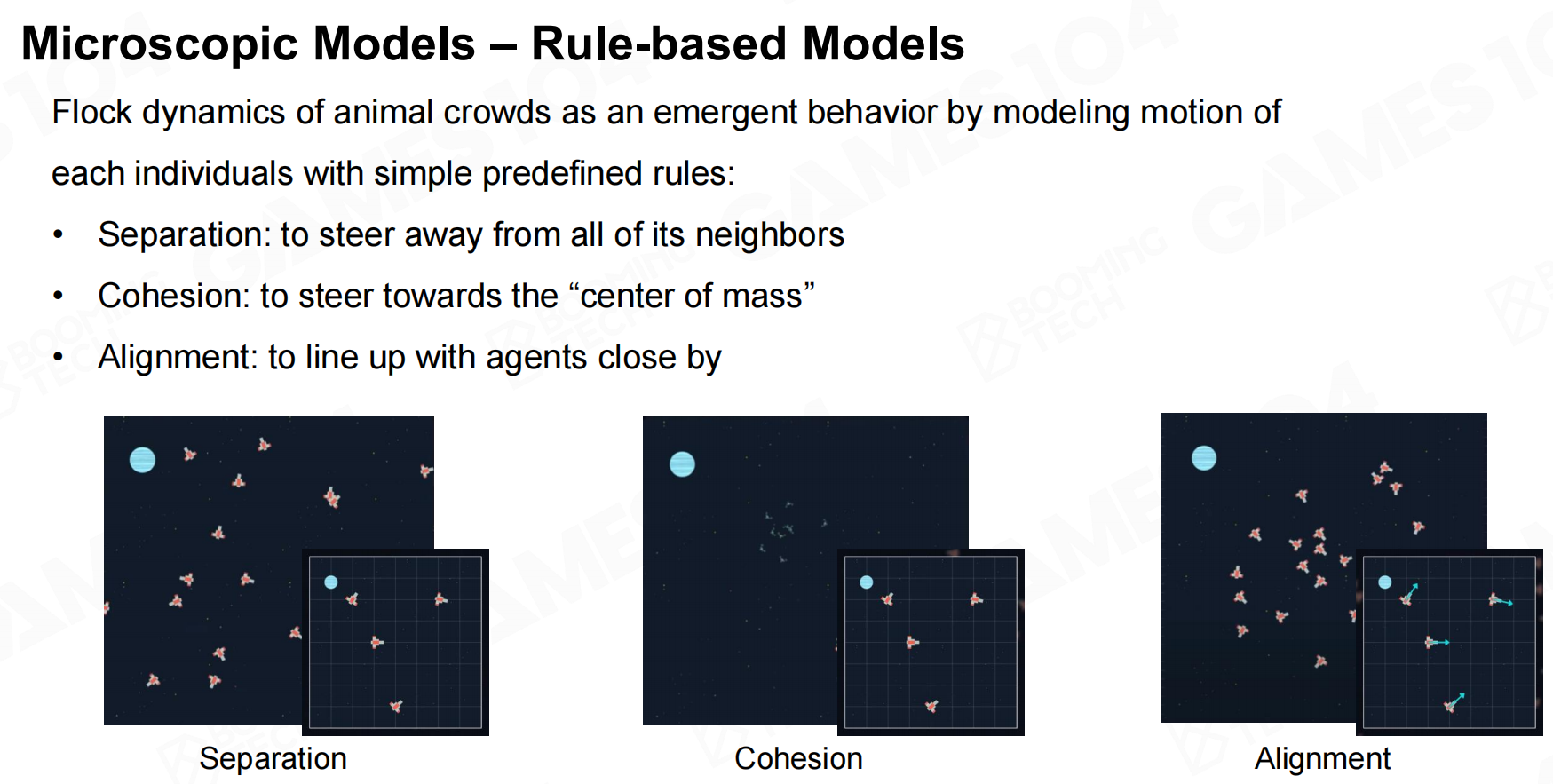 微观模型-基于规则的模型
微观模型-基于规则的模型 微观模型-基于规则的模型2
微观模型-基于规则的模型2
宏观模型(Macroscopic Models)
宏观模型的思想则是在场景中设计一个势场或流场来控制群体中每个个体的行为。 宏观模型
宏观模型
混合模型(Mesoscopic Models)
混合模型则综合了微观和宏观两种模型的思路,它首先把整个群体划分为若干个小组,然后在每个小组中对每个个体使用微观模型的规则来进行控制。这样的方法在各种RTS游戏中有着广泛的应用。 混合模型
混合模型
碰撞(Collision Avoidance)
混合模型则综合了微观和宏观两种模型的思路,它首先把整个群体划分为若干个小组,然后在每个小组中对每个个体使用微观模型的规则来进行控制。这样的方法在各种RTS游戏中有着广泛的应用。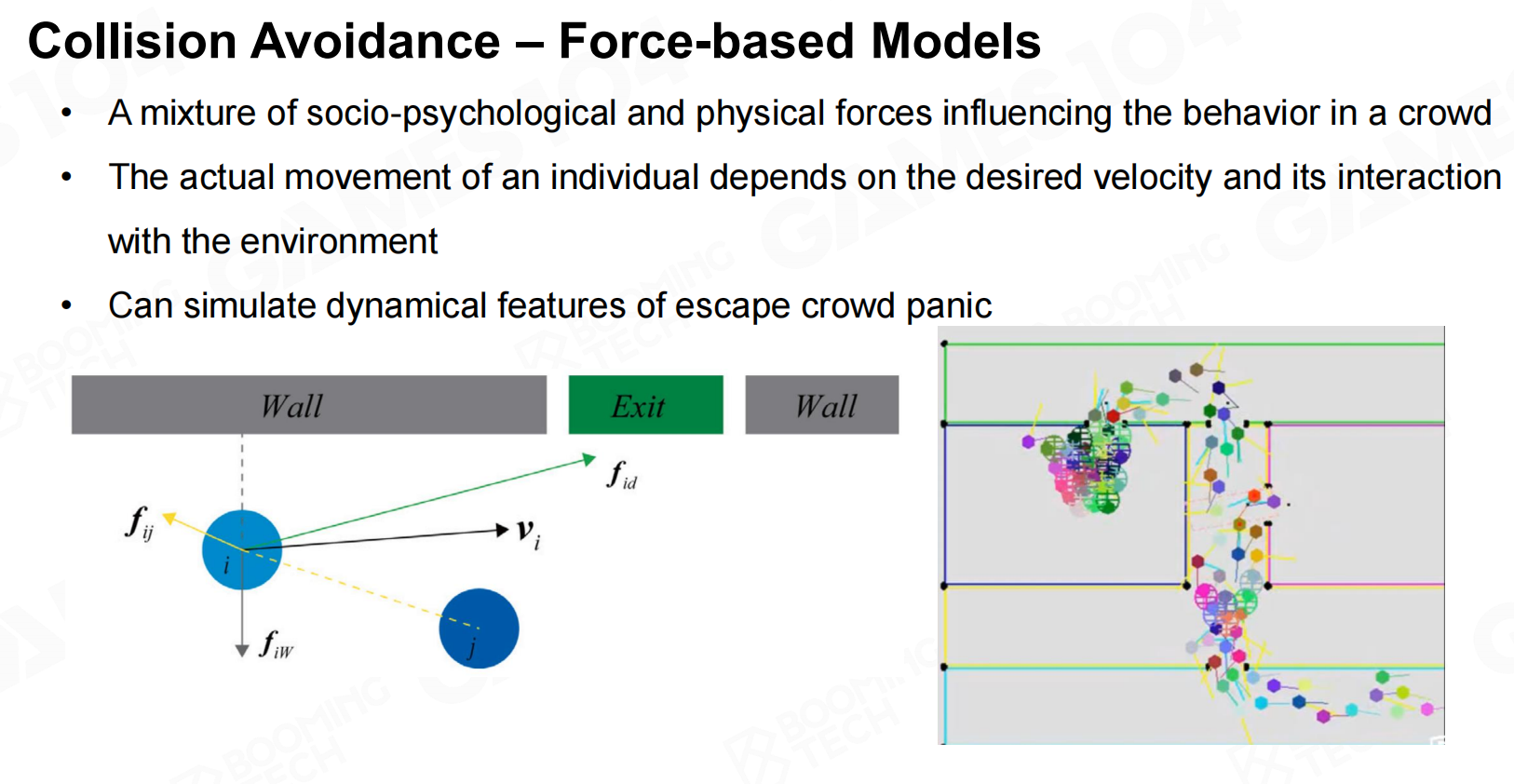 碰撞-基于力的模型
碰撞-基于力的模型 碰撞-基于力的模型2
碰撞-基于力的模型2
另一种处理的方法是基于速度障碍(velocity obstacle, VO)来进行控制。 碰撞-速度障碍
碰撞-速度障碍
VO的思想是当两个物体将要发生碰撞时相当于在速度域上形成了一定的障碍,因此需要调整自身的速度来避免相撞。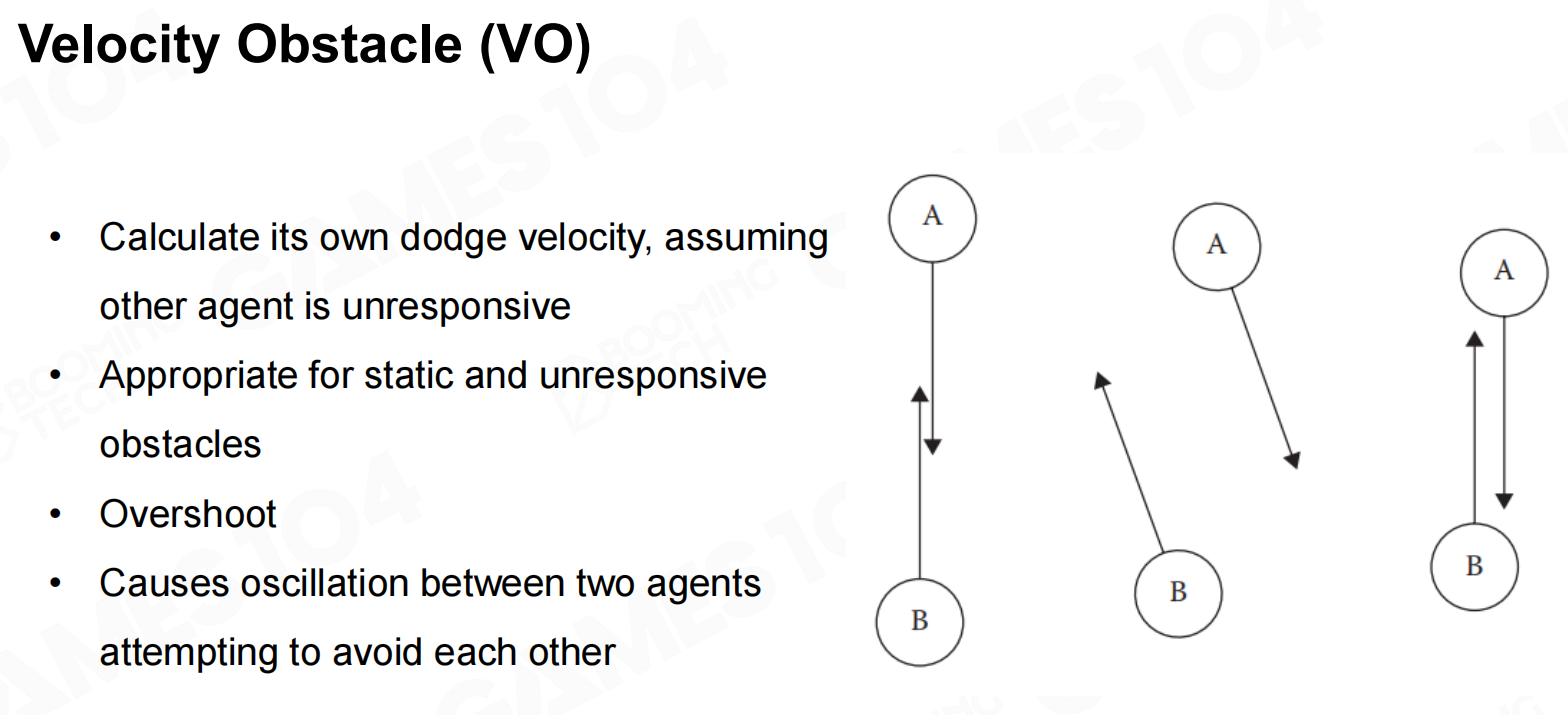 速度障碍
速度障碍
当参与避让的个体数比较多时还需要进行一些整体的优化,此时可以使用ORCA等算法进行处理。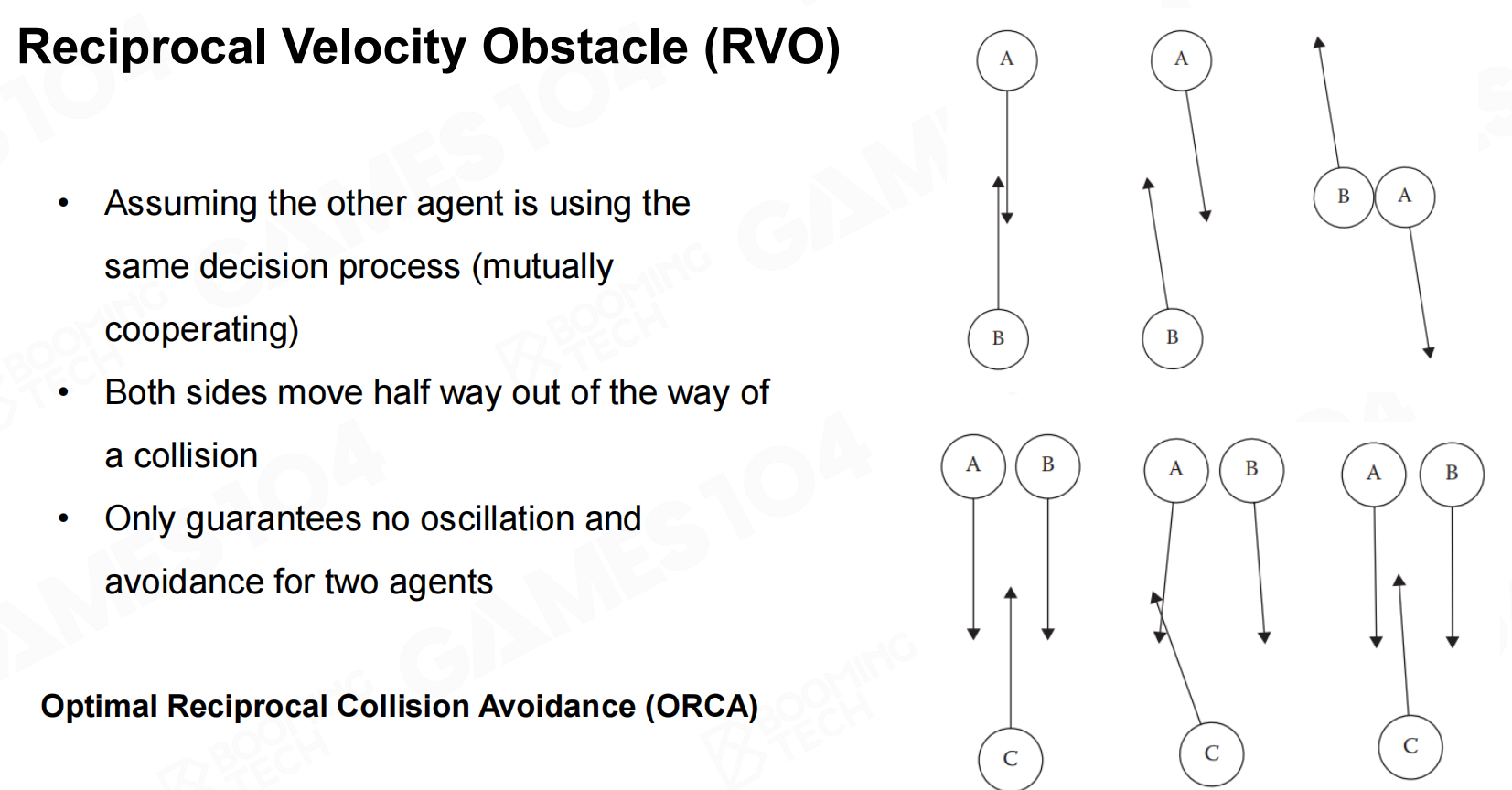 反向速度障碍
反向速度障碍
感知(Sensing)
感知(sensing)是游戏AI的基础,根据获得信息的不同我们可以把感知的内容分为内部信息(internal information)和外部信息(external information)。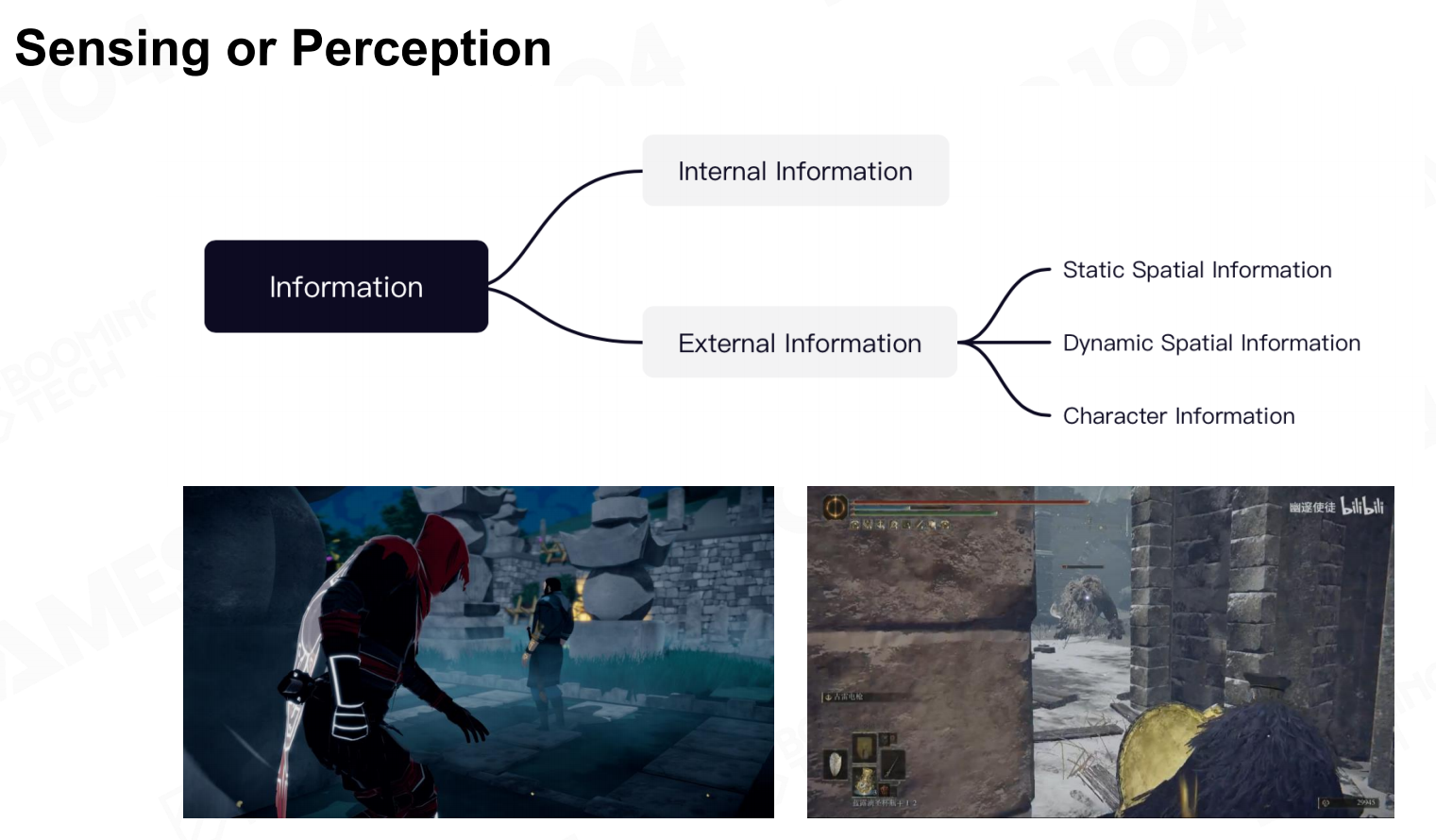 感测或感知
感测或感知
内部信息包括AI自身的位置、HP以及各种状态。这些信息一般可以被AI直接访问到,而且它们是AI进行决策的基础。 内部信息
内部信息
而外部信息则主要包括AI所处的场景中的信息,它会随着游戏进程和场景变化而发生改变。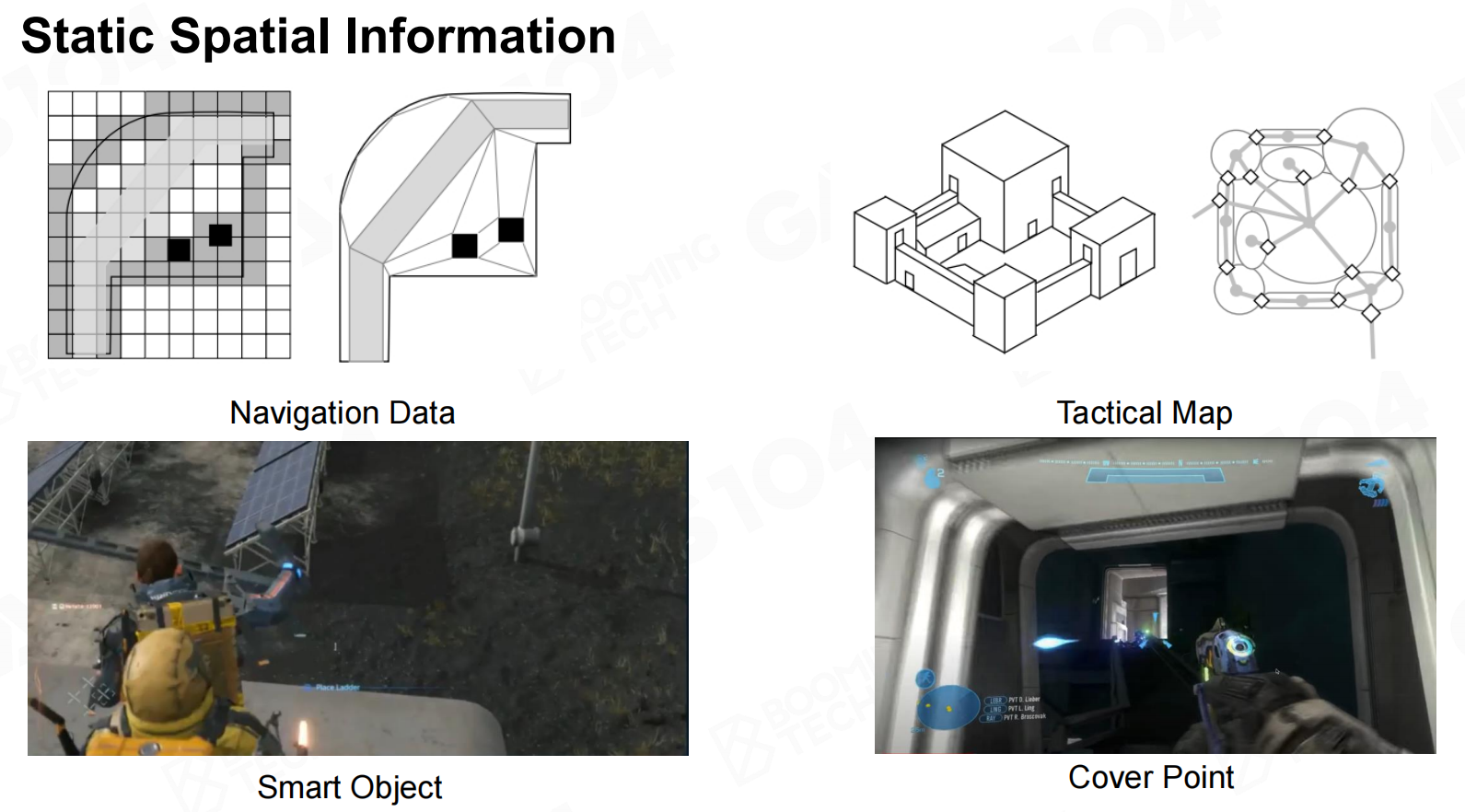 静态空间信息
静态空间信息
外部信息的一种常用表达方式是influence map,场景的变化会直接反映在influence map上。当AI需要进行决策时会同时考虑自身的状态并且查询当前的influence map来选择自身的行为。 动态空间信息-影响图
动态空间信息-影响图 动态空间信息-游戏对象
动态空间信息-游戏对象
游戏AI进行感知时还需要注意我们不能假设AI可以直接获得所有游戏的信息,而是希望AI能够像玩家一样只利用局部感知的信息来进行决策。 传感仿真
传感仿真
经典决策算法(Classic Decision Making Algorithms)
在上面这些知识的基础上就可以开始构建游戏AI系统了。游戏AI算法的核心是决策(decision making)系统,经典的决策系统包括有限状态机(finite state machine, FSM)和行为树(behavior tree, BT)两种。 决策算法
决策算法
有限状态机(Finite State Machine)
在有限状态机模型中我们认为AI的行为可以建模为在不同状态之间的游走,不同状态之间的切换称为转移(transition)。以吃豆人游戏为例,游戏AI可以使用一个包含3个状态的状态机来表示。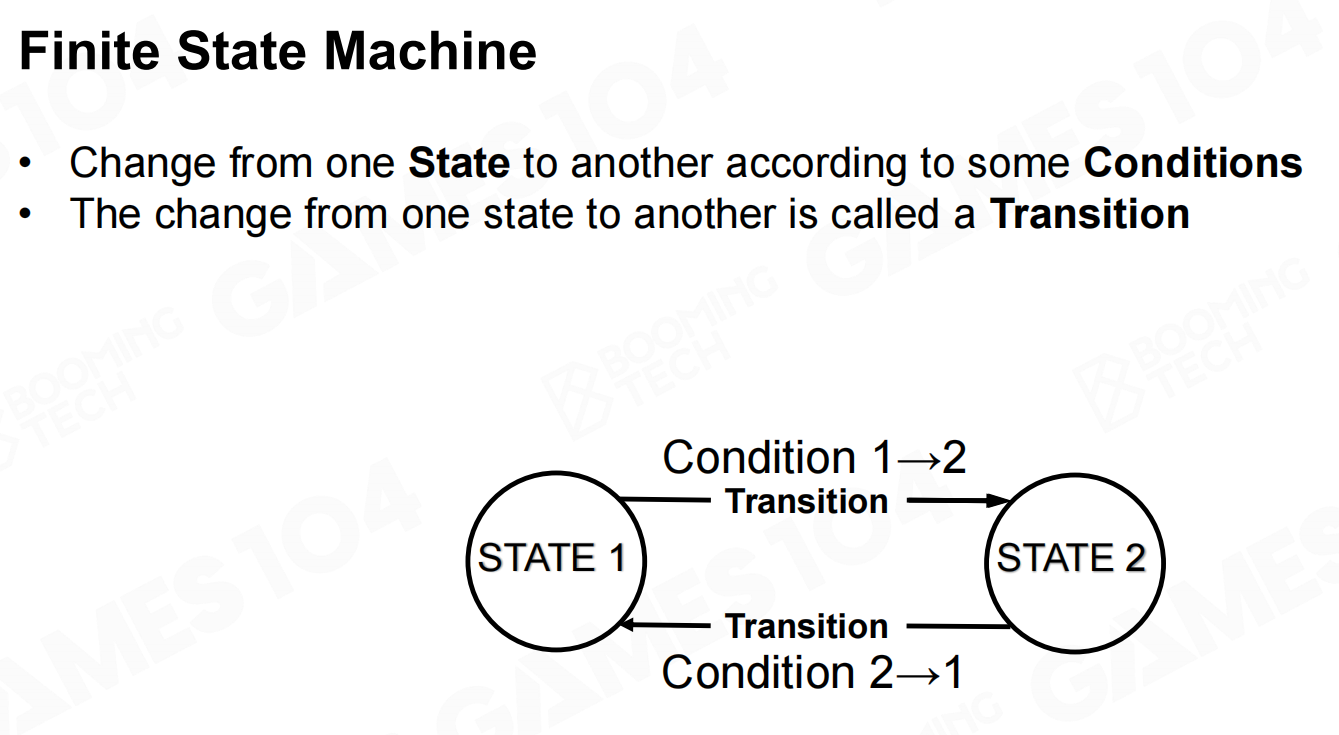 有限状态机
有限状态机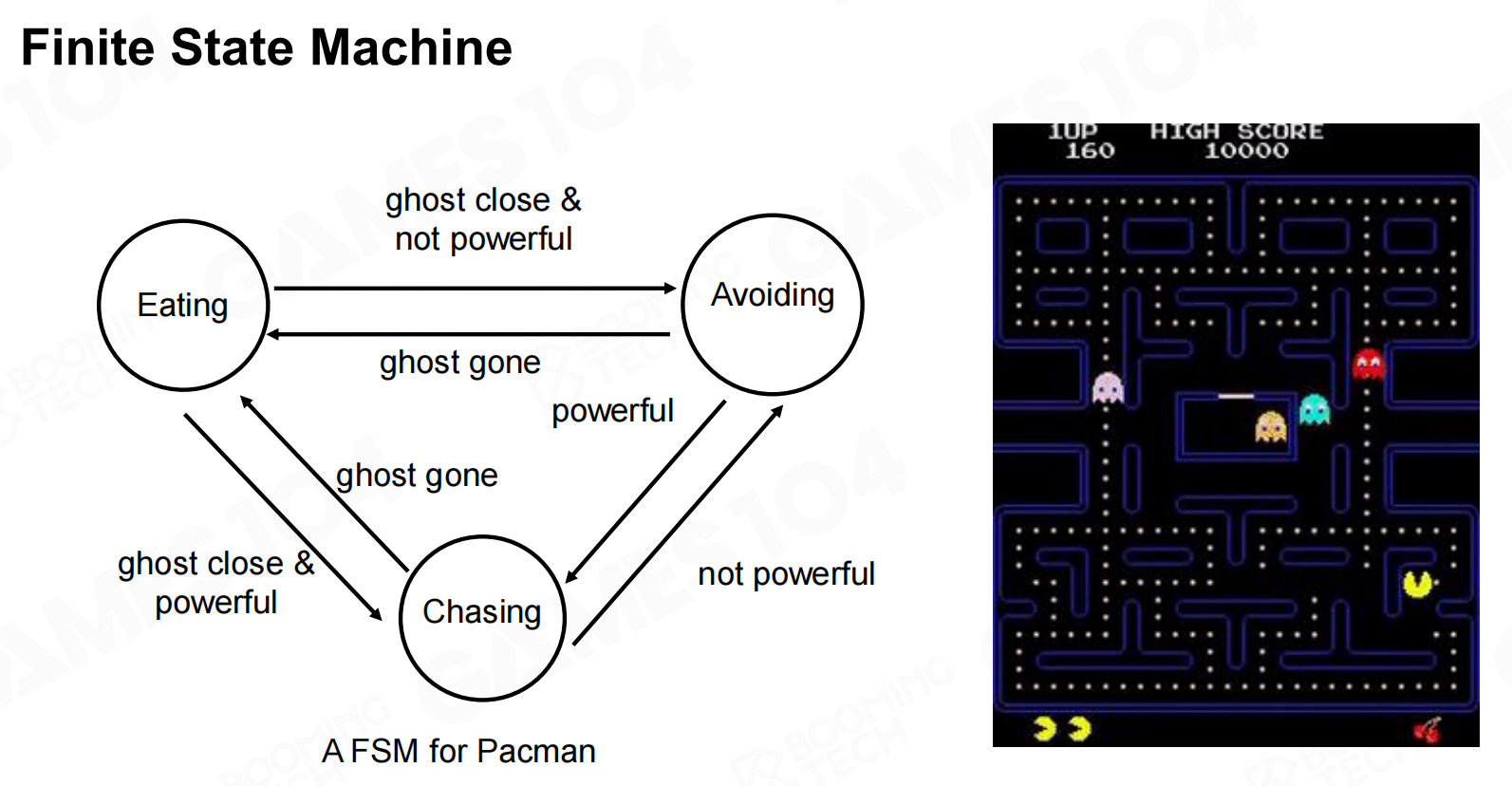 有限状态机2
有限状态机2
有限状态机的缺陷在于现代游戏中AI的状态空间可能是非常巨大的,因此状态之间的转移会无比复杂。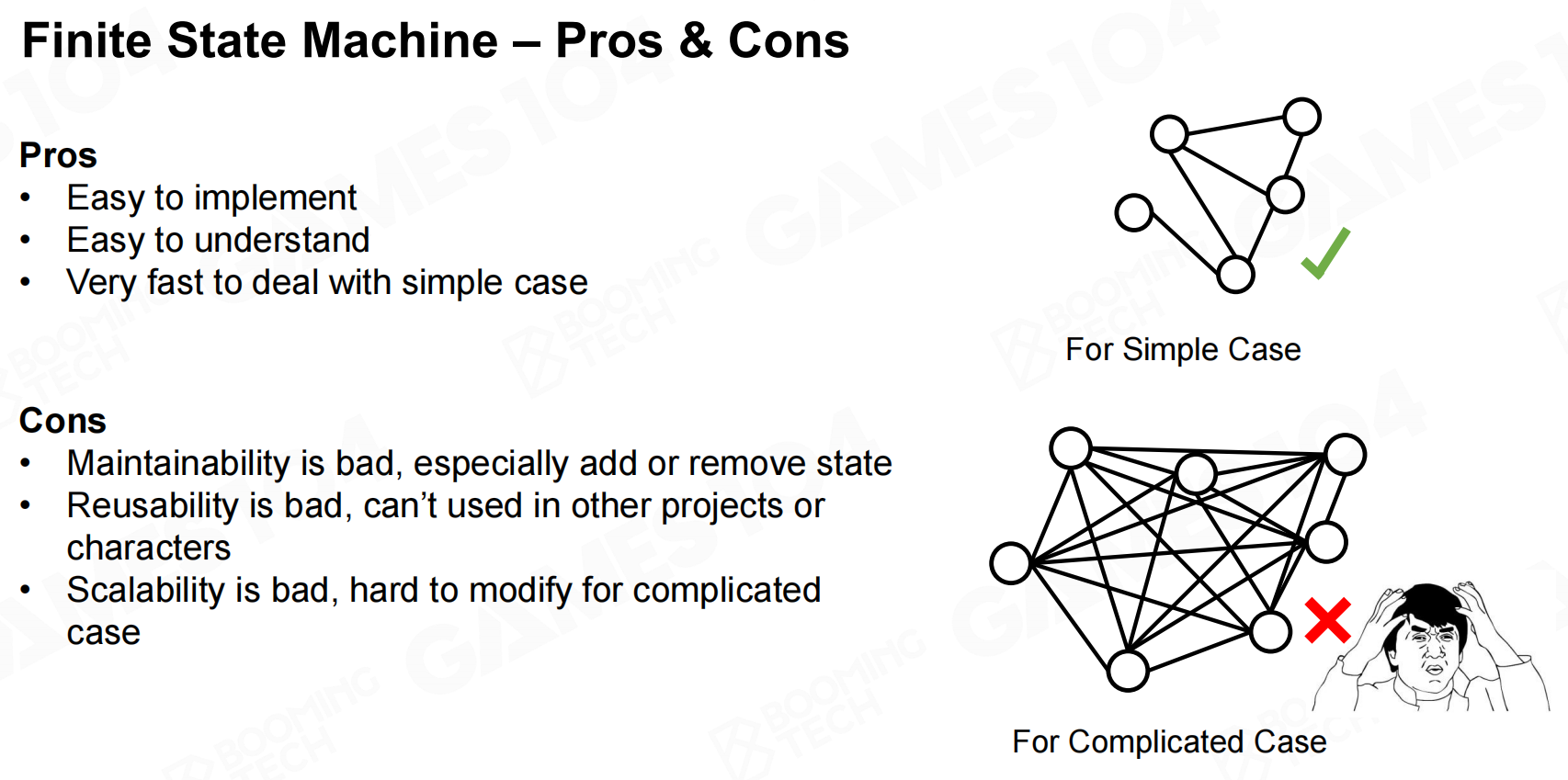 有限状态机-利弊
有限状态机-利弊
为了克服有限状态机过于复杂的问题,人们还提出了hierarchical finite state machine(HFSM)这样的模型。在HFSM中我们把整个复杂的状态机分为若干层,不同层之间通过有向的接口进行连接,这样可以增加模型的可读性。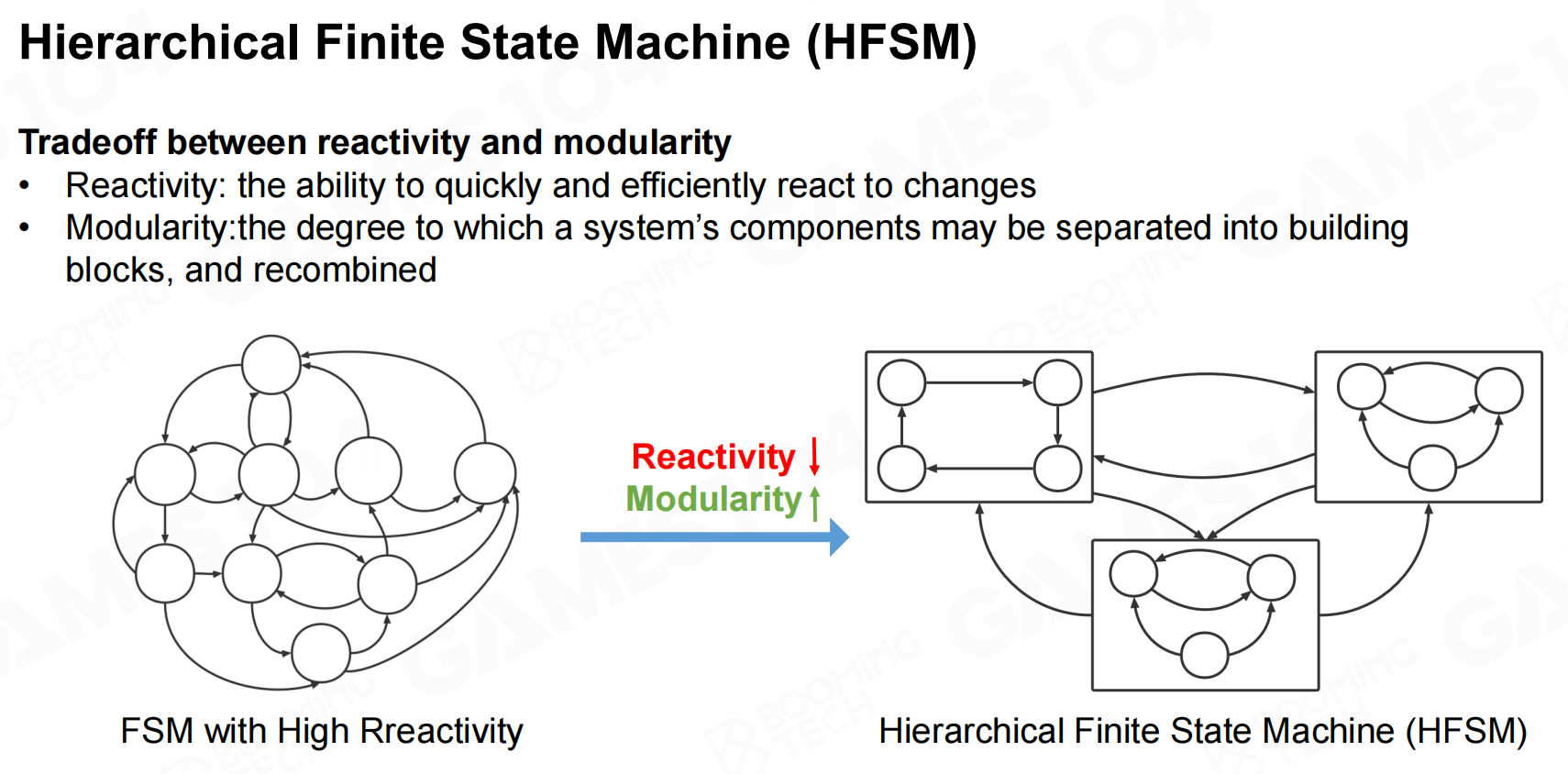 分层有限状态机
分层有限状态机
行为树(Behavior Tree)
在现代游戏中更为常用的决策算法是行为树,它的决策行为更接近人脑的决策过程。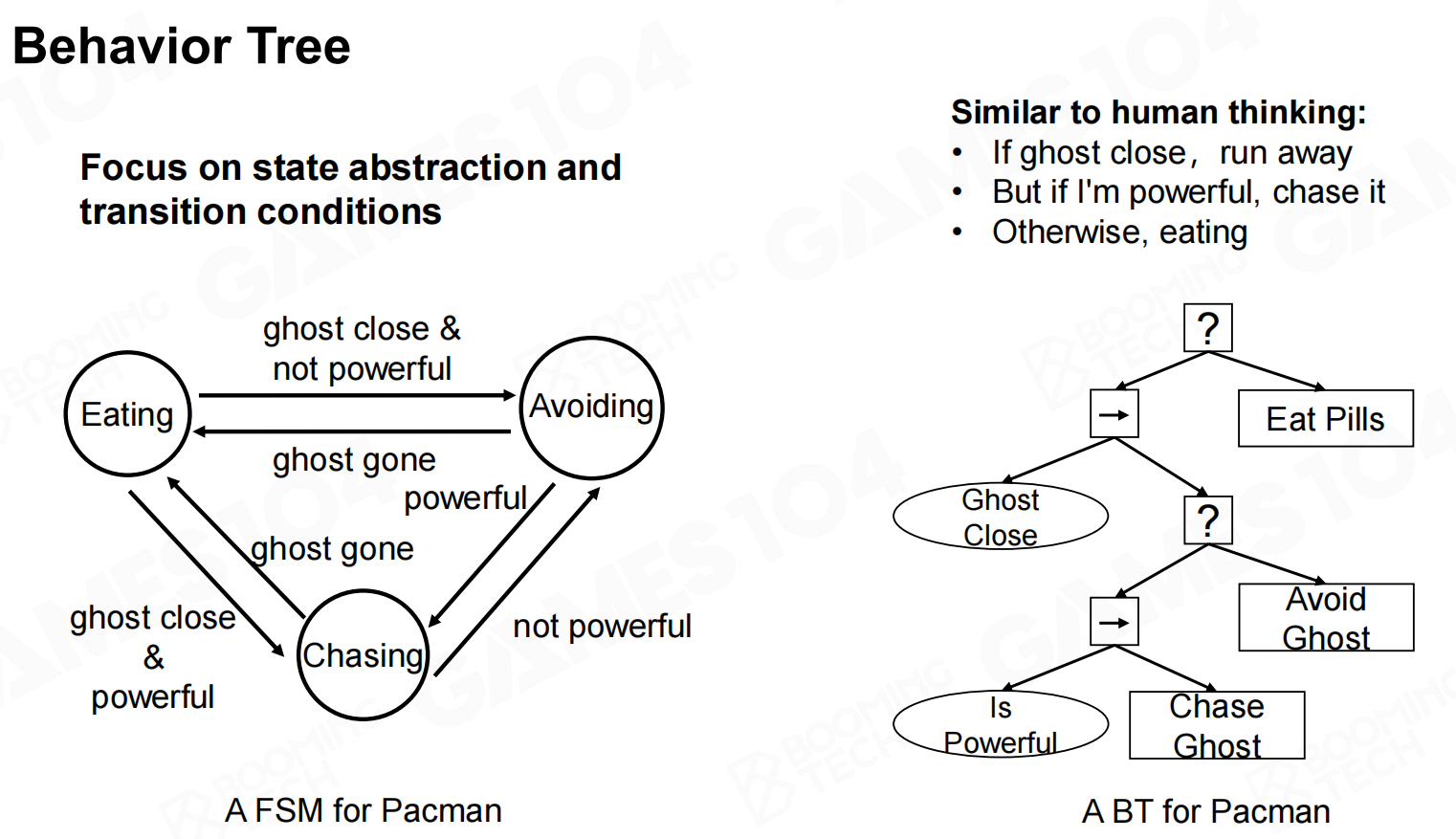 行为树
行为树
行为树中的执行节点(excution node)表示AI执行的过程,它包括条件判断以及具体执行的动作两种节点。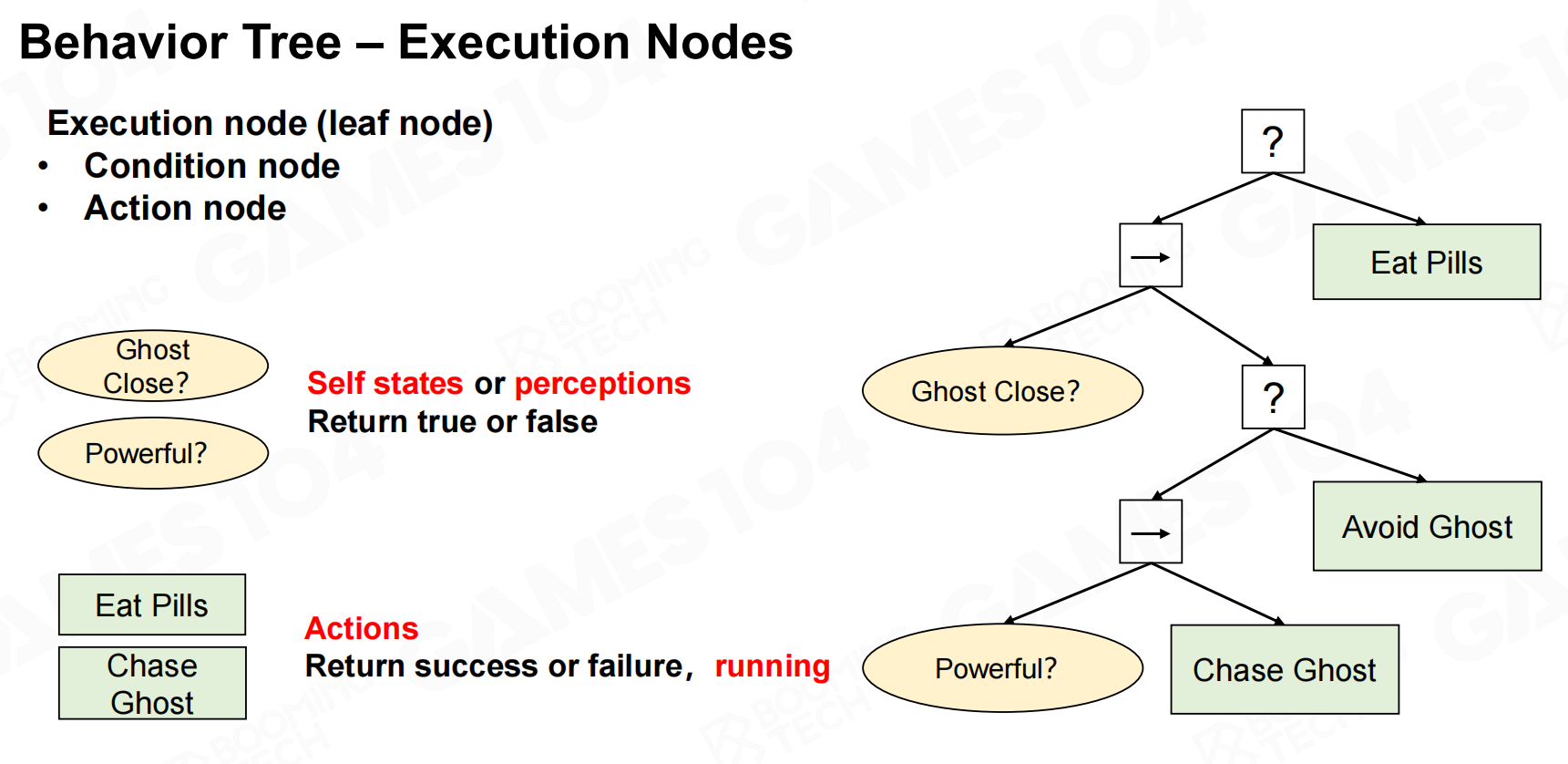 行为树-执行节点
行为树-执行节点
行为树中的另一种节点是控制节点(control node),它用来表示决策过程的控制流。control node包括sequence、selector、parallel以及decorator等几种。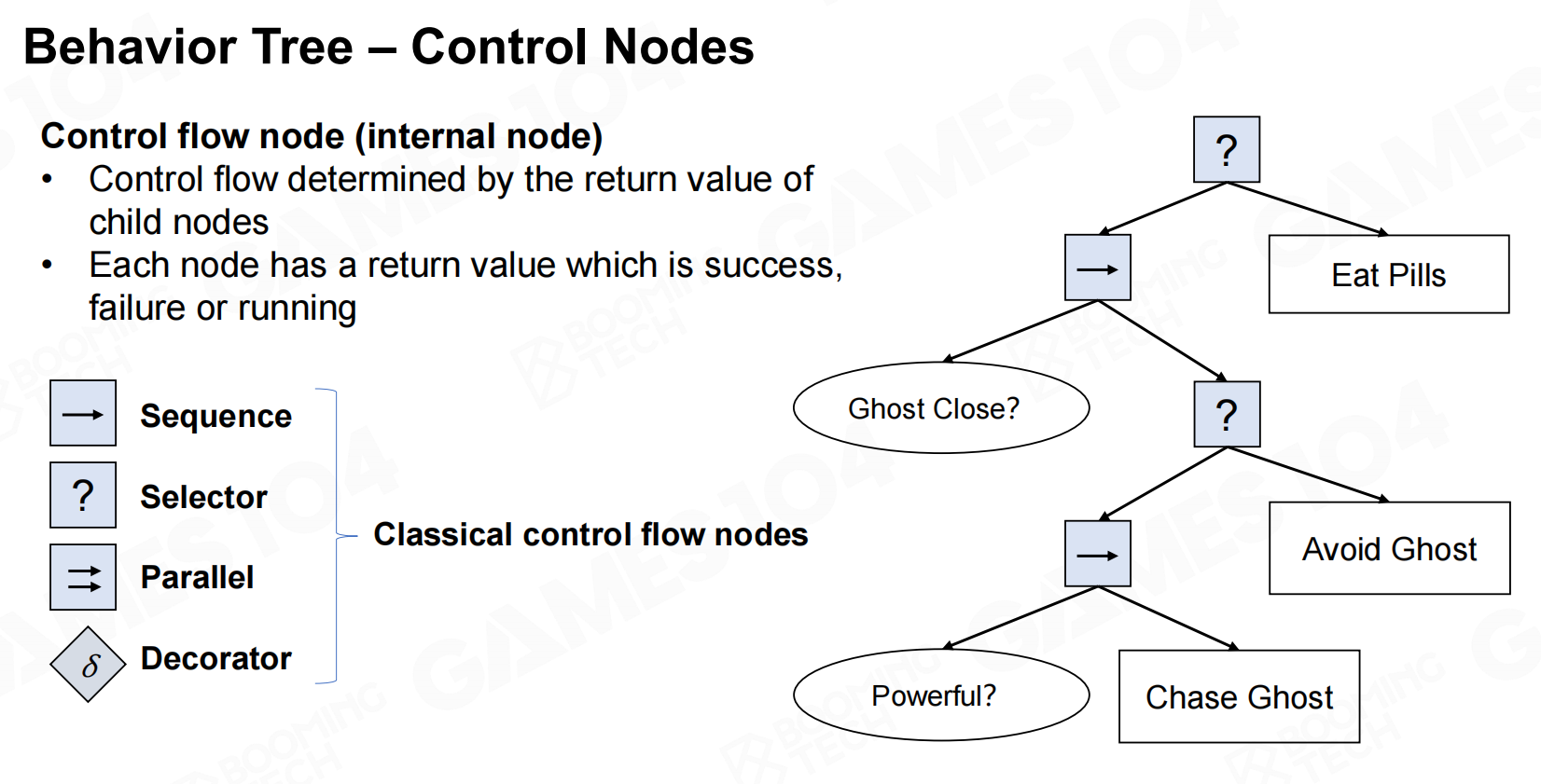 行为树-控制节点
行为树-控制节点
sequence是表示对当前节点的子节点依次进行访问和执行,一般可以用来表示AI在当前状态下的行为计划。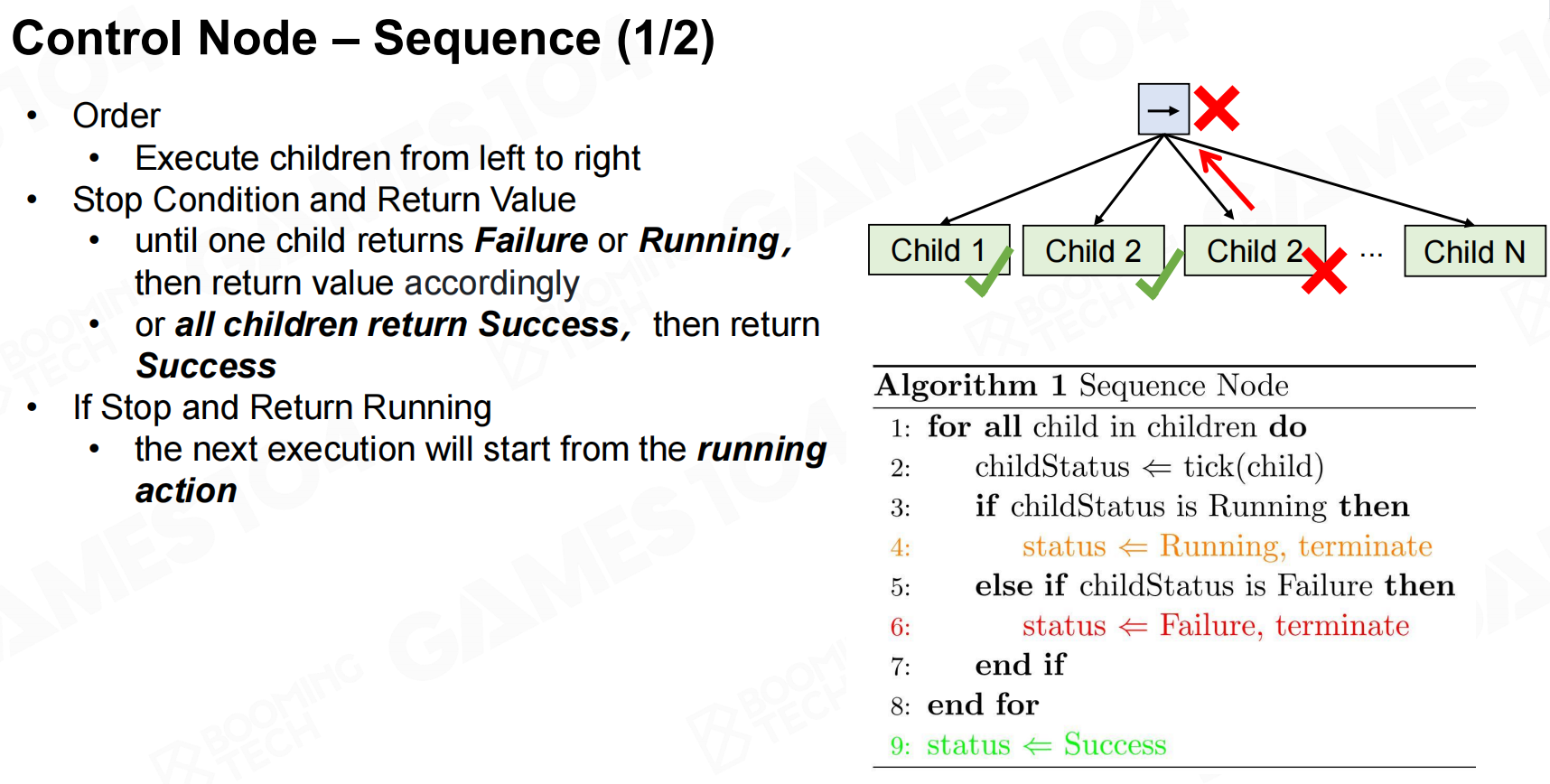 控制节点-序列
控制节点-序列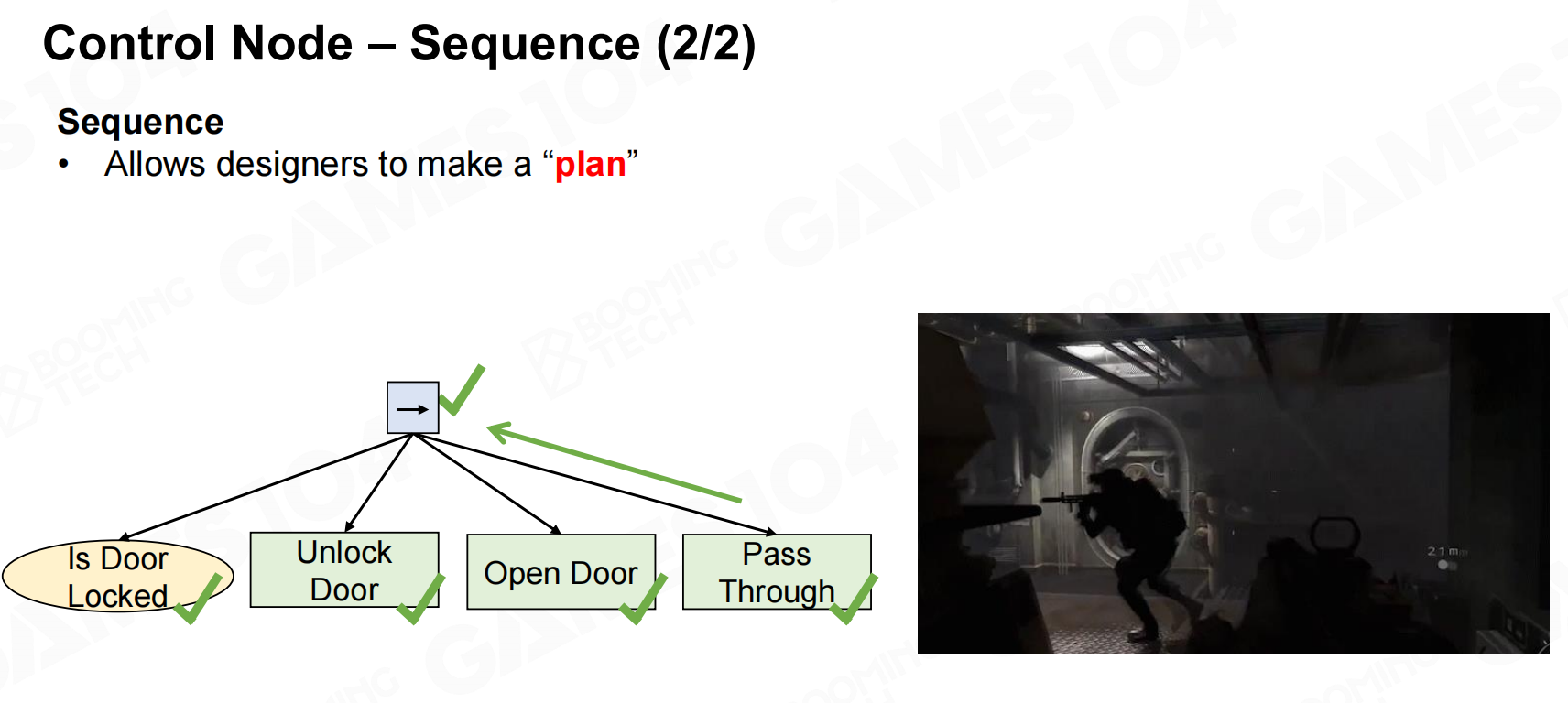 控制节点-序列2
控制节点-序列2
selector同样会遍历当前节点的子节点,但不同于sequence的地方是如果某个子节点返回True则会终止遍历。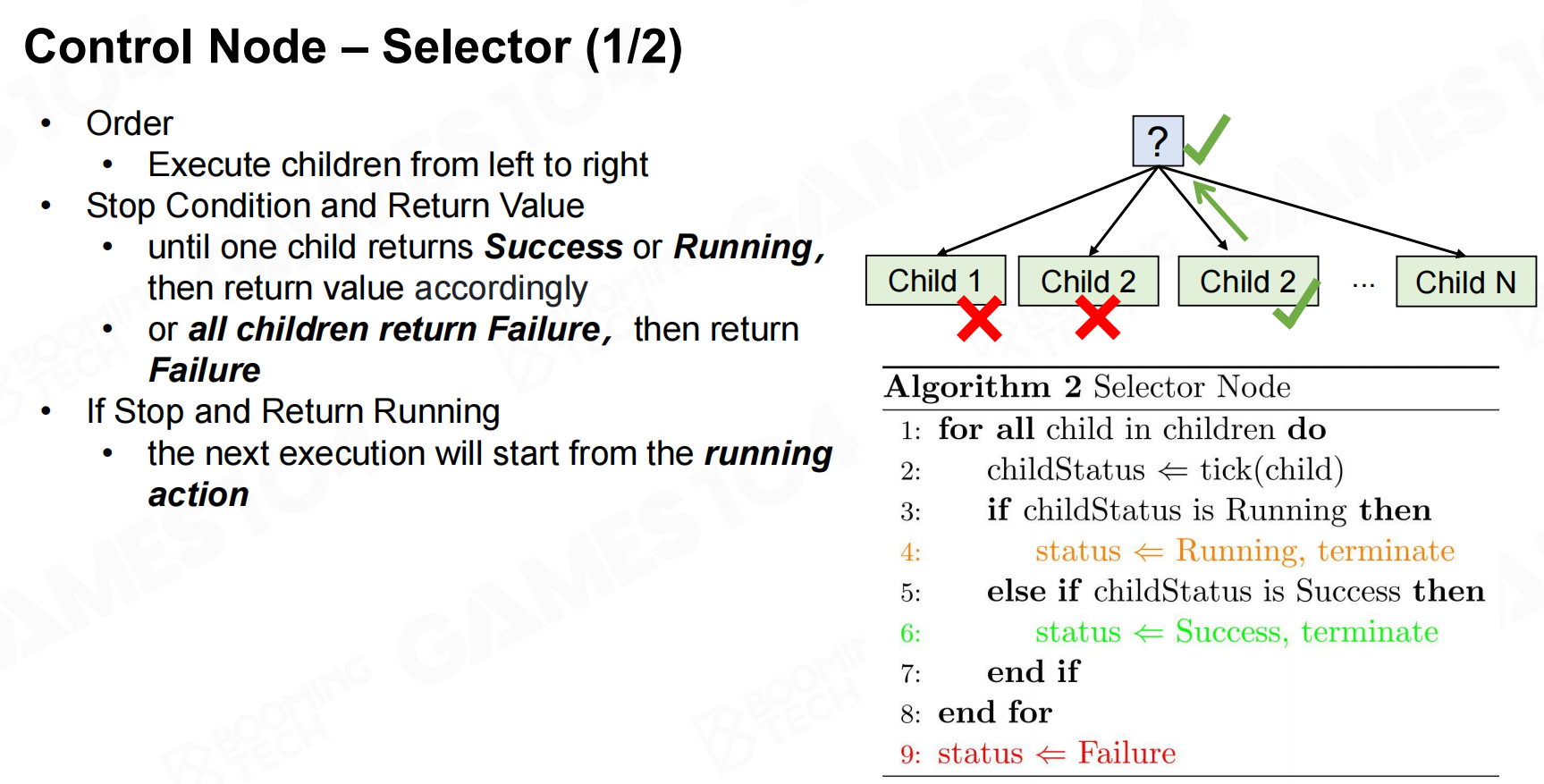 控制节点-选择器
控制节点-选择器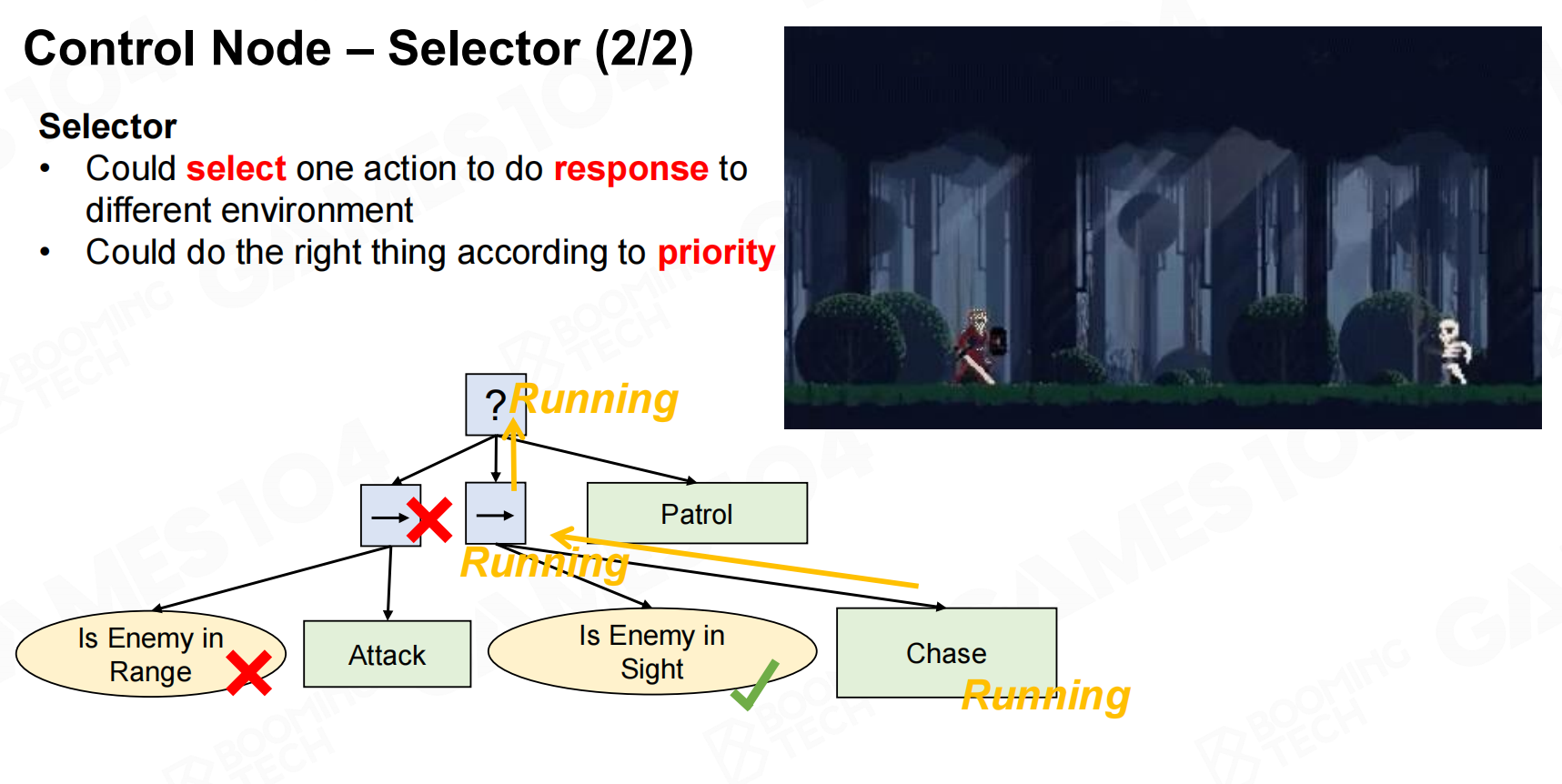 控制节点-选择器2
控制节点-选择器2
parallel会同时执行当前节点下的所有子节点。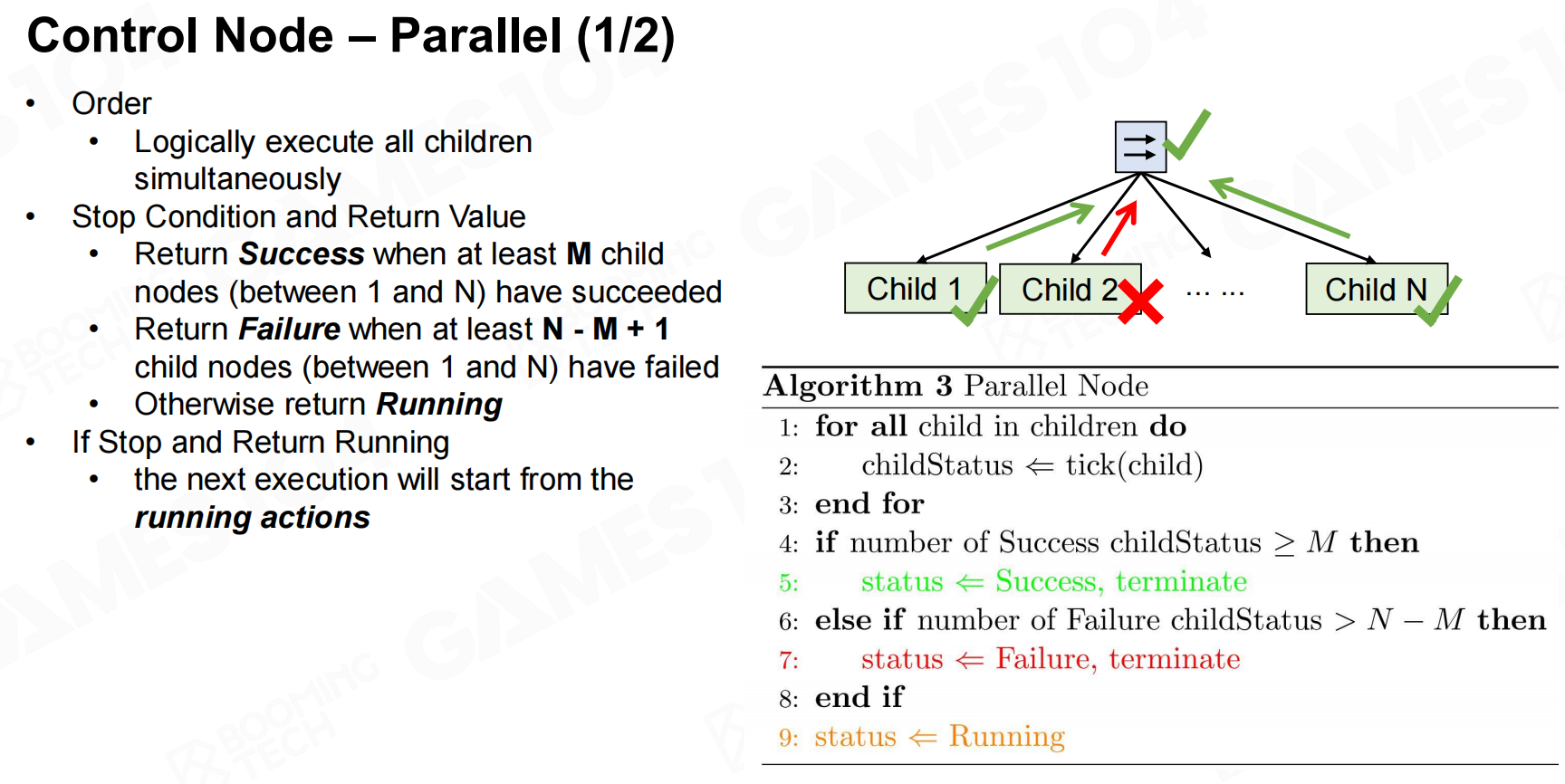 控制节点-并行
控制节点-并行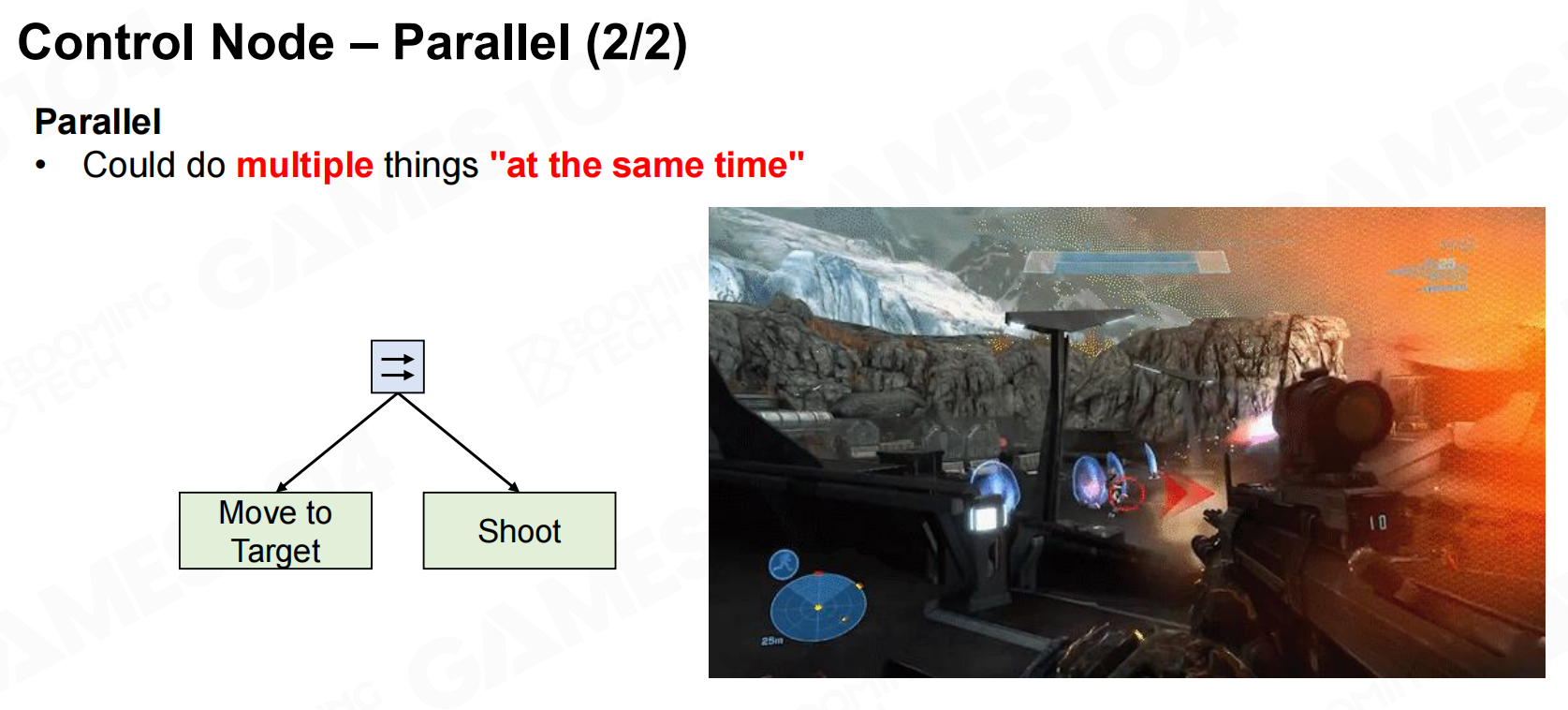 控制节点-并行2
控制节点-并行2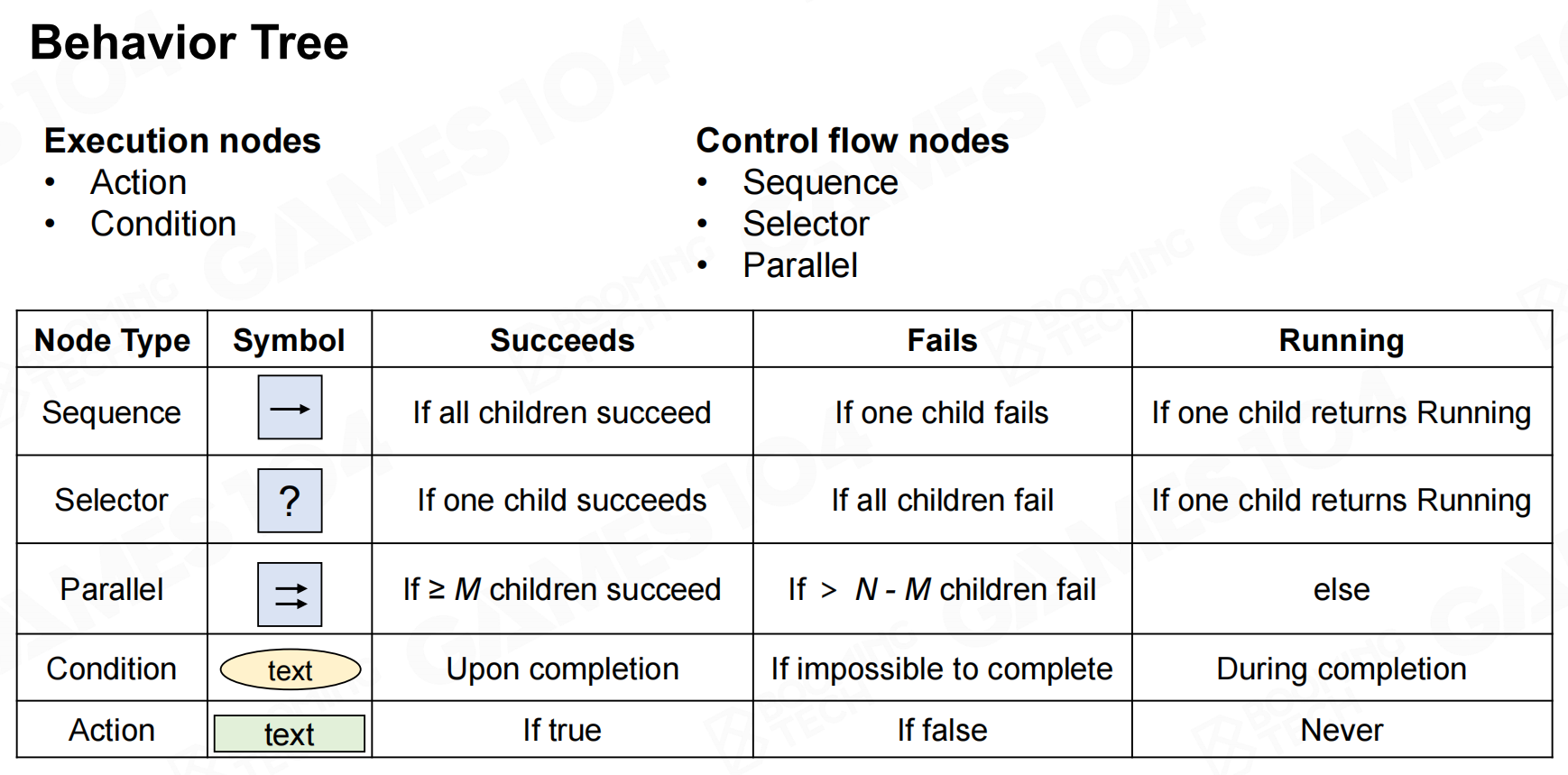 行为树
行为树
行为树在进行执行时需要注意每一次执行时都需要返回根节点。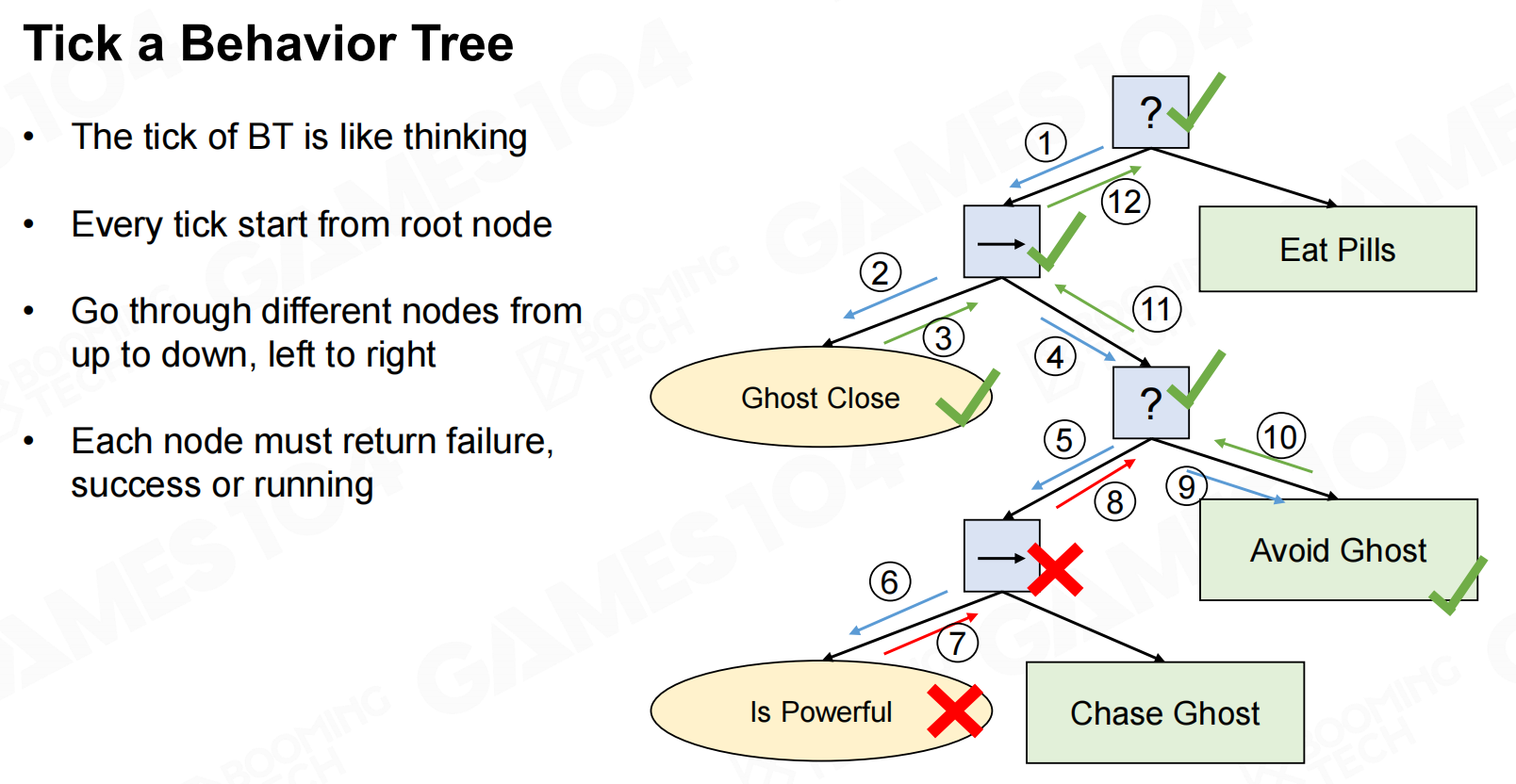 执行行为树
执行行为树
在现代游戏中还提出了decorator节点来丰富可以执行的行为。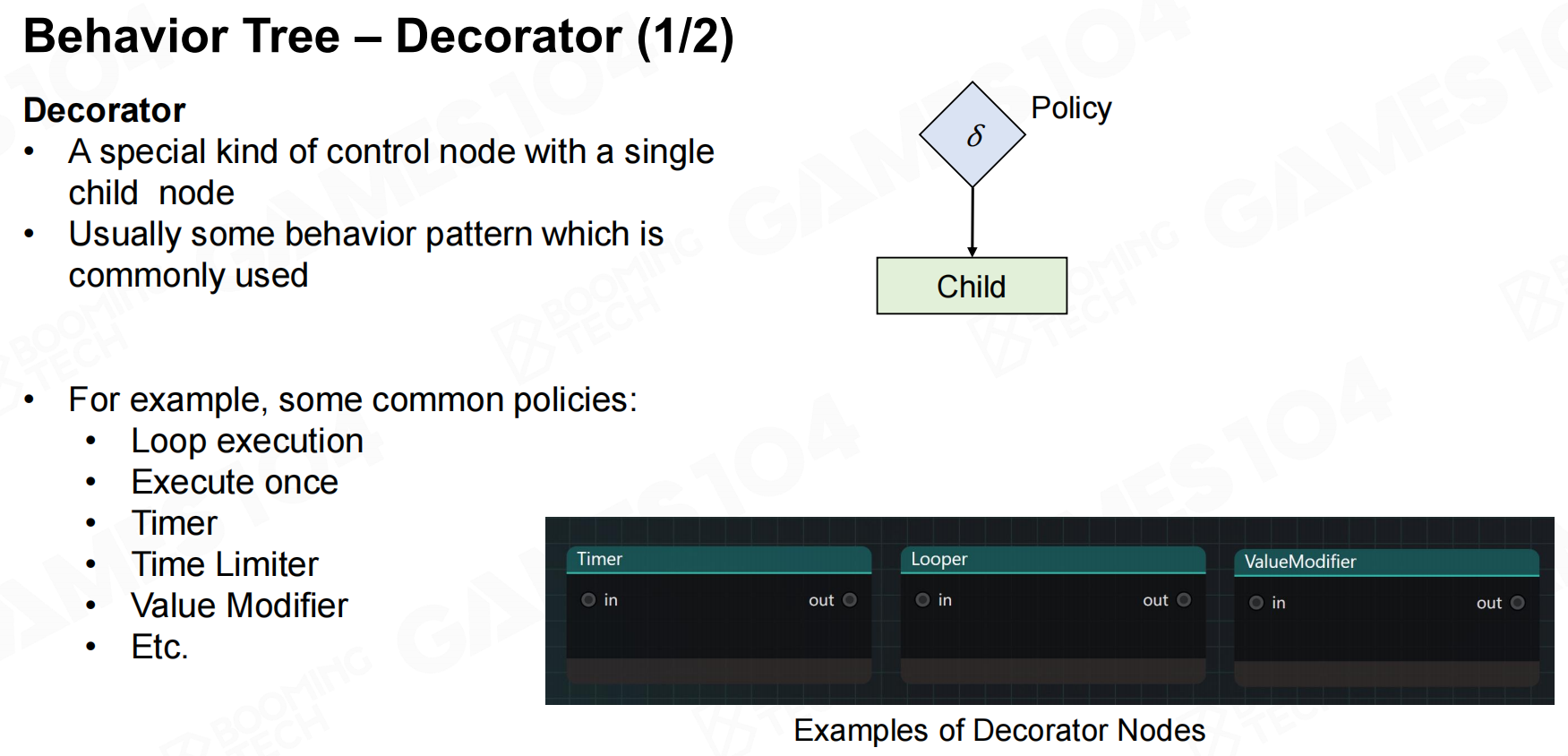 行为树-装饰器
行为树-装饰器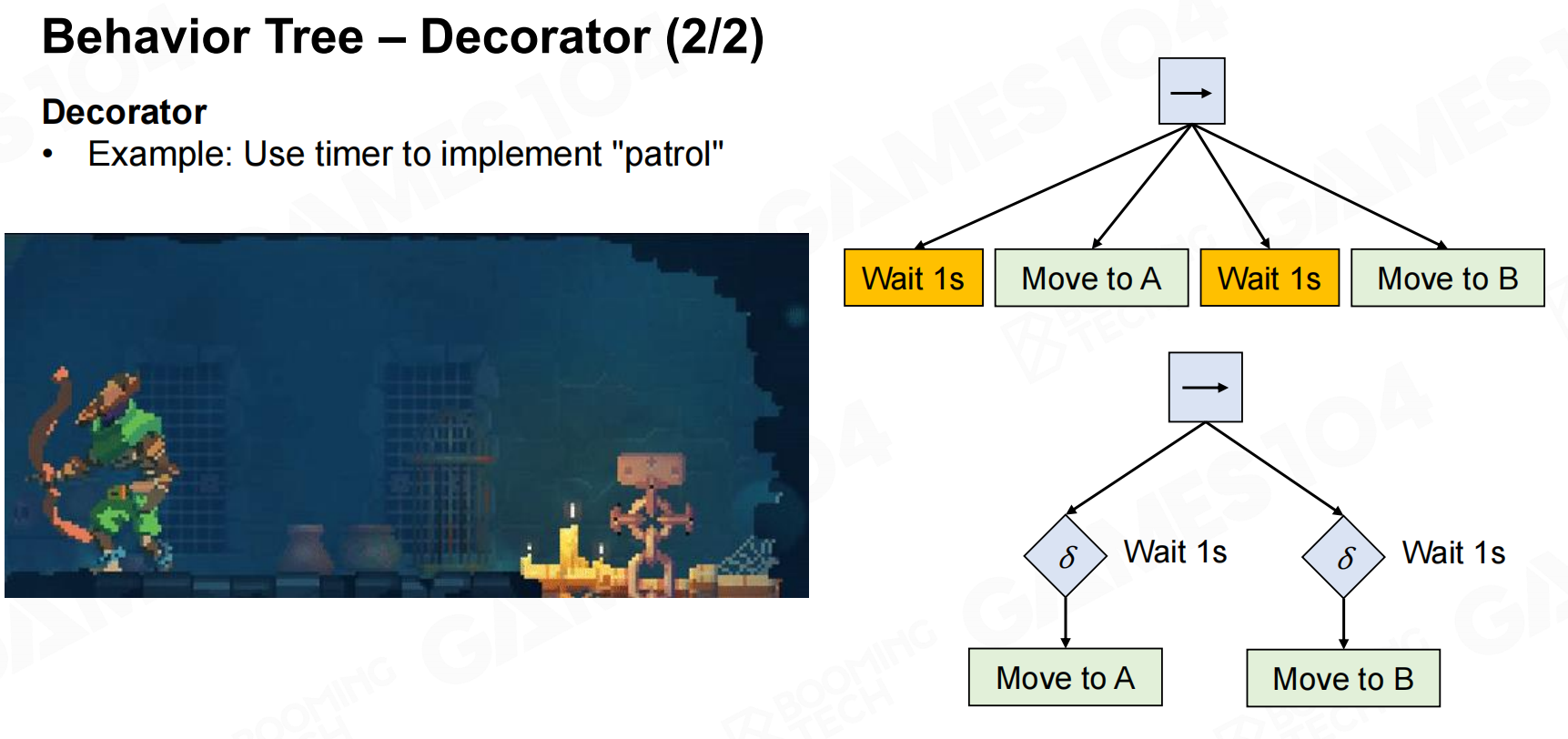 行为树-装饰器2
行为树-装饰器2
我们还可以使用precondition和blackborad来提升决策过程的可读性。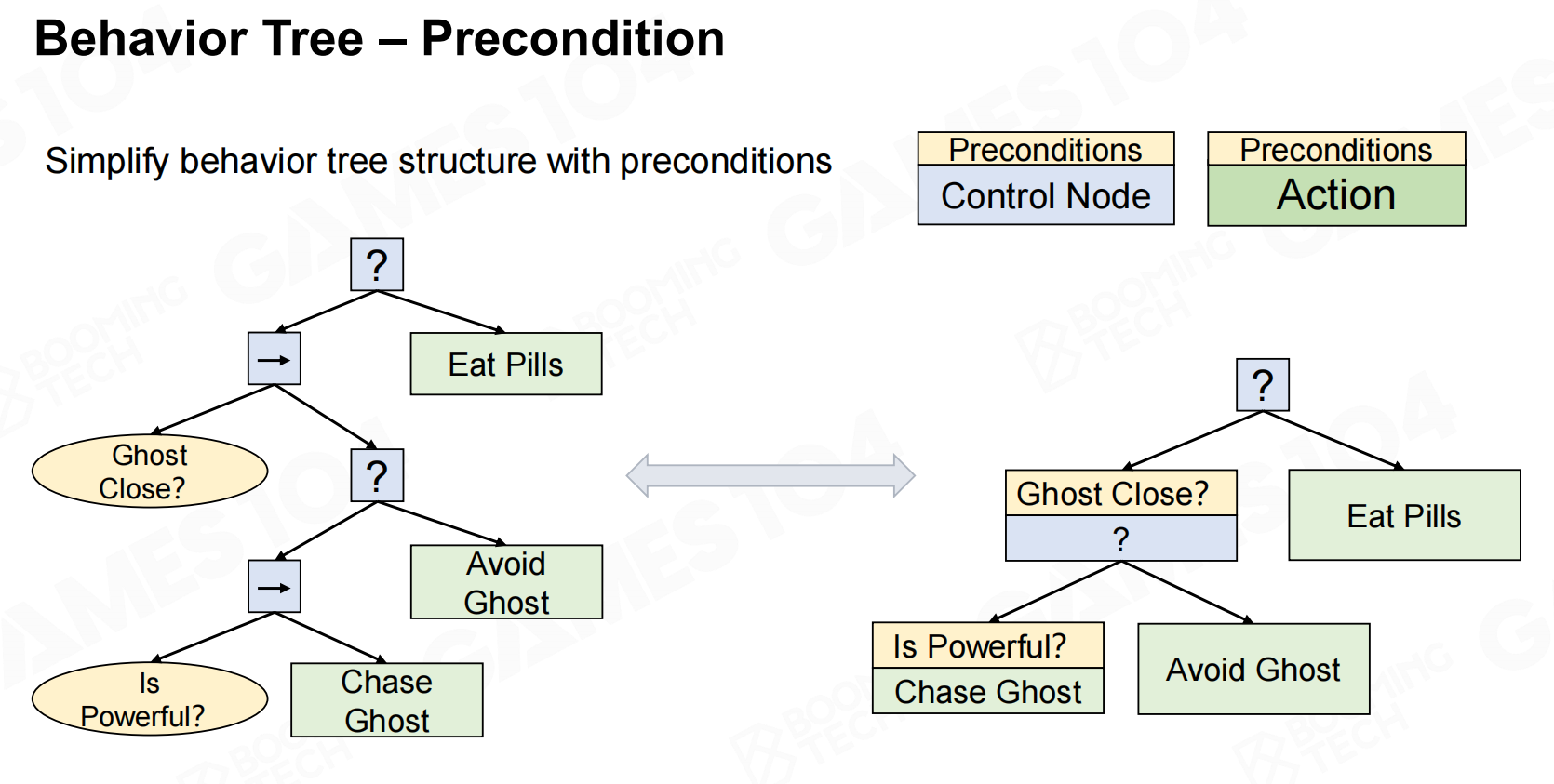 行为树-先决条件
行为树-先决条件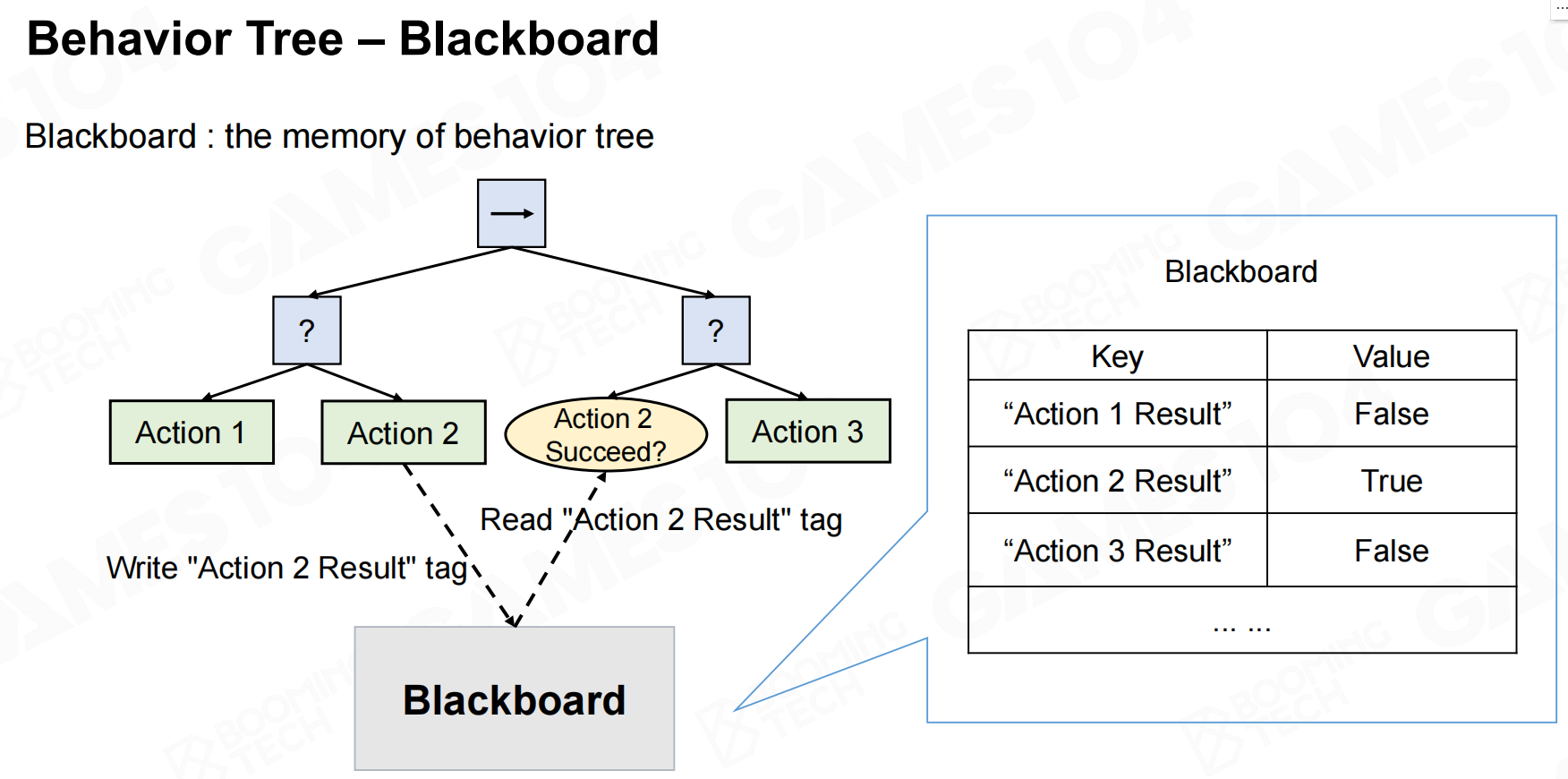 行为树-黑板
行为树-黑板
行为树的决策过程非常符合人的决策行为而且也易于调试,因此广泛应用在各种游戏AI中。当然行为树也有一些缺点,比如说每次调用时都必须从根节点出发重新执行,这样的效率是比较低的。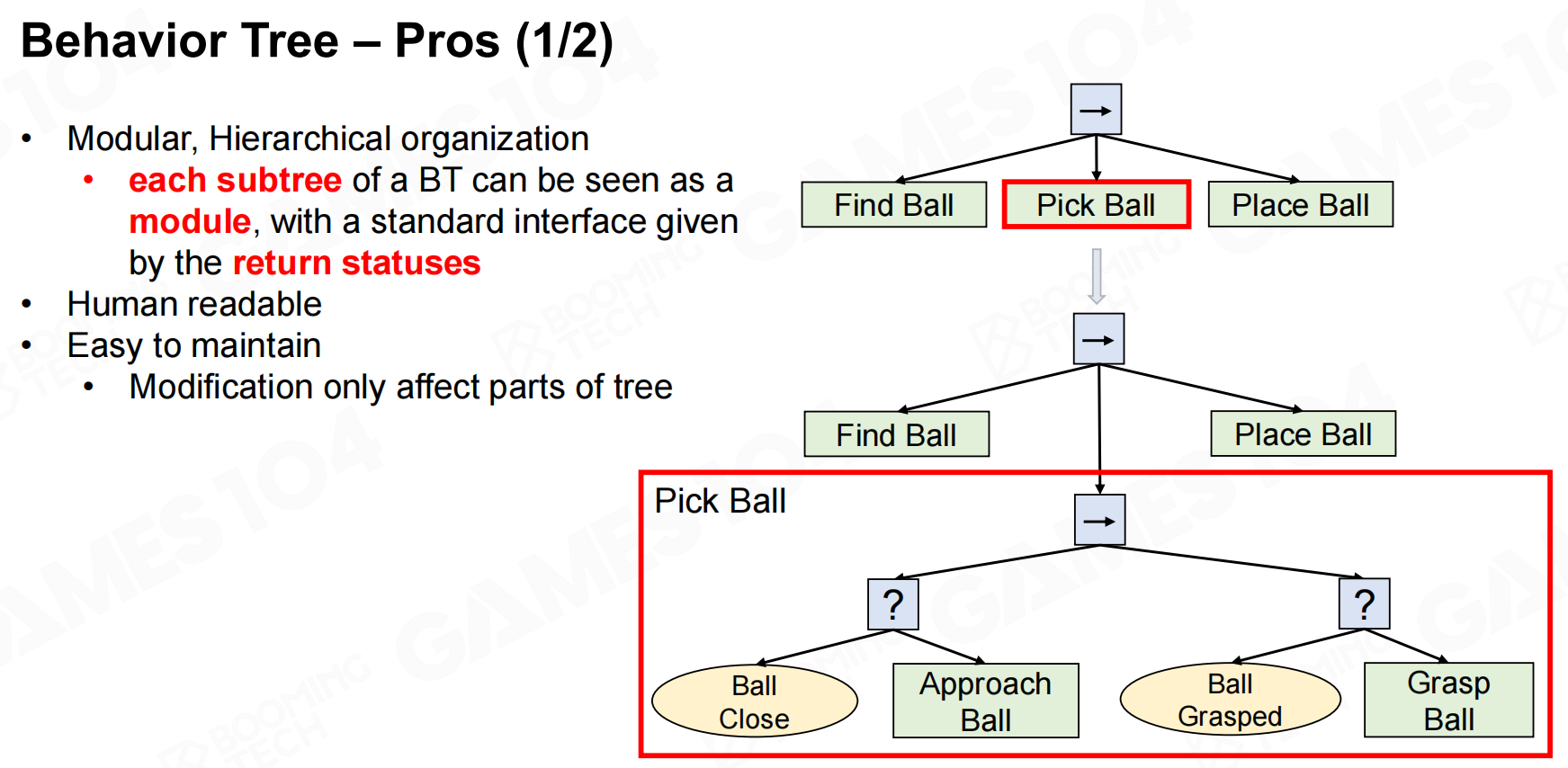 行为树-优点
行为树-优点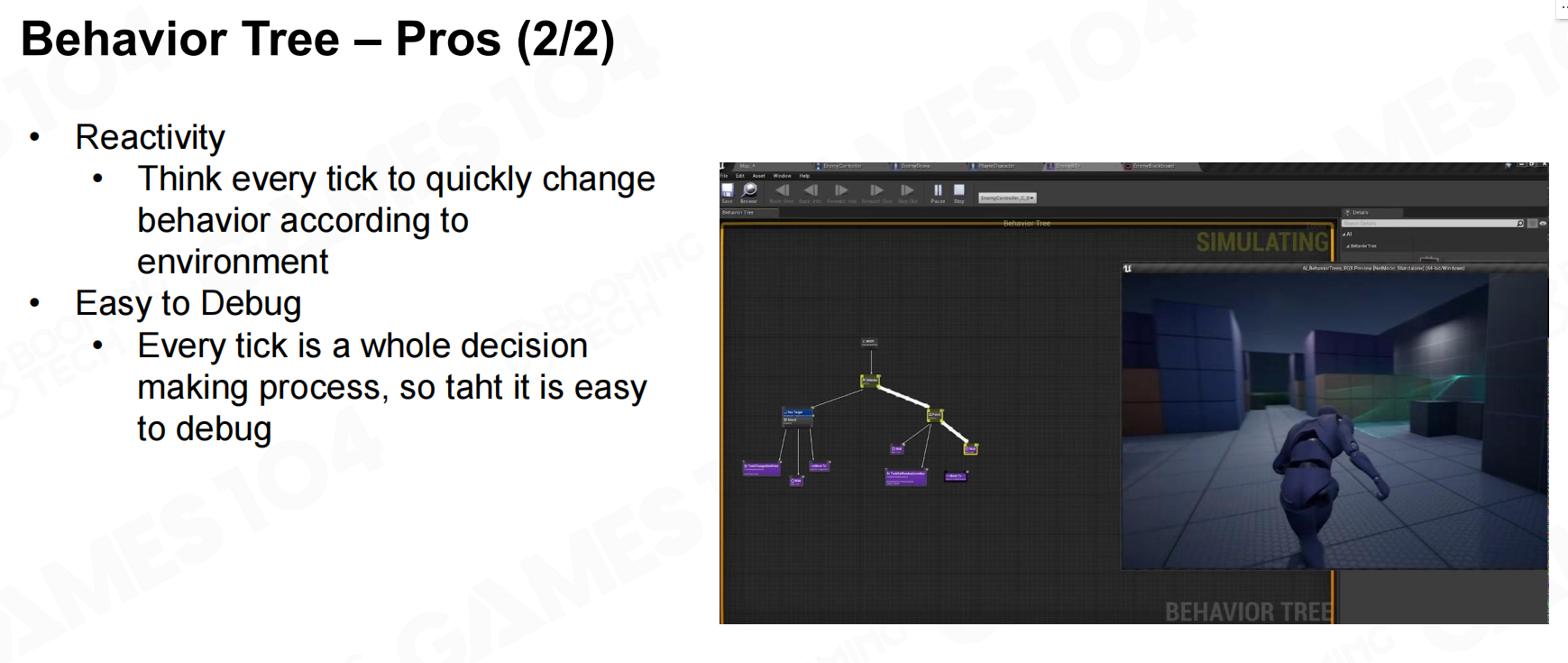 行为树-优点2
行为树-优点2 行为树-缺点
行为树-缺点
目前随着AI技术的发展,游戏AI也开始使用一些规划(planning)算法来进行决策。这些更先进的算法我们会在后面的课程进行介绍。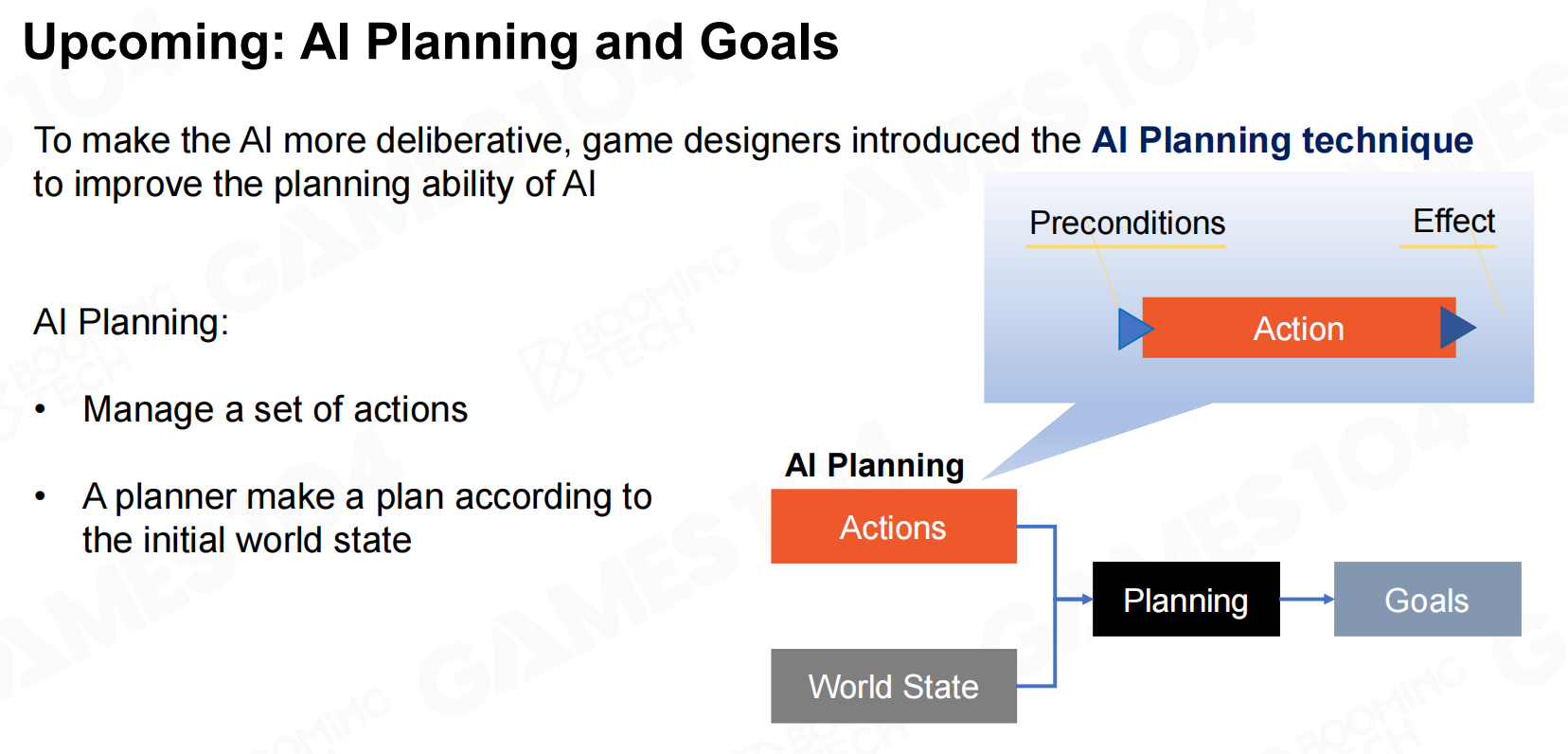 即将到来的目标是:人工智能规划和目标
即将到来的目标是:人工智能规划和目标
引用
- 本文作者:樱白 - Cherry White
- 本文链接:https://cherry-white.github.io/posts/bd4c9b3a.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!
☕ 如果这篇文章对你有帮助
欢迎请我喝杯咖啡,支持持续创作